tensorflow实现AlexNet(MNIST数据集)
问题背景:之前写了一篇AlexNet代码实现的博文,那里的代码有个最大的问题——数据来源是人为给定的,就给了个图片尺寸224,并不是真的有数据集。因此,本文要在MNIST上试试AlexNet。当然,因为输入图片尺寸大小不一样,所以只是借鉴AlexNet的结构,详细参数是不一样。
本文参考了好几个博主的代码,各分析其优缺点。参考的链接如下:
1)https://blog.csdn.net/felaim/article/details/65630312
这份代码好就好在【集成化】,代码量少但思路清晰,故引用过来。
2)https://blog.csdn.net/phdat101/article/details/52410569
这份代码好就好在【构造模型和评价模型分开了,而且有tensorboard可视化】
下面详细看看吧~
第一种实现
当卷积基本结构差不多的时候,采取这样的构建方式确实很好,省了很多代码量!
#coding=utf-8
from __future__ import print_function
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
import tensorflow as tf
# 定义网络超参数
learning_rate = 0.001
training_iters = 10000 #我这里只迭代一万次
batch_size = 64 #每个batch的大小
display_step = 20 #每20步展示一下结果
# 定义网络参数
n_input = 784 # 输入的维度
n_classes = 10 # 标签的维度
dropout = 0.8 # Dropout 的概率
# 占位符输入
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32)
# 卷积操作,统一卷积格式(stride\padding),且加上relu
def conv2d(name, l_input, w, b):
return tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(l_input, w, strides=[1, 1, 1, 1], padding='SAME'),b), name=name)
# 最大下采样操作
def max_pool(name, l_input, k):
return tf.nn.max_pool(l_input, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME', name=name)
# 归一化操作
def norm(name, l_input, lsize=4):
return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name)
# 定义整个网络
def alex_net(_X, _weights, _biases, _dropout):
# 向量转为矩阵
_X = tf.reshape(_X, shape=[-1, 28, 28, 1]) #自动分好batch数
# 卷积层
conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1'])
# 下采样层
pool1 = max_pool('pool1', conv1, k=2)
# 归一化层
norm1 = norm('norm1', pool1, lsize=4)
# Dropout
norm1 = tf.nn.dropout(norm1, _dropout)
# 卷积
conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2'])
# 下采样
pool2 = max_pool('pool2', conv2, k=2)
# 归一化
norm2 = norm('norm2', pool2, lsize=4)
# Dropout
norm2 = tf.nn.dropout(norm2, _dropout)
# 卷积
conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3'])
# 下采样
pool3 = max_pool('pool3', conv3, k=2)
# 归一化
norm3 = norm('norm3', pool3, lsize=4)
# Dropout
norm3 = tf.nn.dropout(norm3, _dropout)
# 全连接层,先把特征图转为向量
dense1 = tf.reshape(norm3, [-1, _weights['wd1'].get_shape().as_list()[0]])
dense1 = tf.nn.relu(tf.matmul(dense1, _weights['wd1']) + _biases['bd1'], name='fc1')
# 全连接层
dense2 = tf.nn.relu(tf.matmul(dense1, _weights['wd2']) + _biases['bd2'], name='fc2') # Relu activation
# 网络输出层
out = tf.matmul(dense2, _weights['out']) + _biases['out']
return out
# 存储所有的网络参数
weights = {
'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])),
'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])),
'wc3': tf.Variable(tf.random_normal([3, 3, 128, 256])),
'wd1': tf.Variable(tf.random_normal([4*4*256, 1024])),
'wd2': tf.Variable(tf.random_normal([1024, 1024])),
'out': tf.Variable(tf.random_normal([1024, 10]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([64])),
'bc2': tf.Variable(tf.random_normal([128])),
'bc3': tf.Variable(tf.random_normal([256])),
'bd1': tf.Variable(tf.random_normal([1024])),
'bd2': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# 构建模型
pred = alex_net(x, weights, biases, keep_prob) #pred是计算完的值,此时还没归一化
a=tf.nn.softmax(pred) #a是归一化后的值。
# 定义损失函数和学习步骤
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))#这个是损失loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) #最小化loss
# 测试网络
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 初始化所有的共享变量
init = tf.initialize_all_variables()
# 开启一个训练
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters: #直到达到最大迭代次数,没考虑梯度!!!
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 获取批数据
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys, keep_prob: dropout})
if step % display_step == 0: #每一步里有64batch,64*20=1280
# 计算精度
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})
# 计算损失值
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})
print ("Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy = " + "{:.5f}".format(acc))
step += 1
print ("Optimization Finished!")
# 计算测试精度
print ("Testing Accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images[:256], y: mnist.test.labels[:256], keep_prob: 1.})) #拿前256个来测试
print ("Testing Result:", sess.run(a, feed_dict={x: mnist.test.images[63:64], y: mnist.test.labels[63:64], keep_prob: 1.})) #数组范围,从0开始,含左不含右
另外,代码中,有个函数蛮重要的,tf.nn.softmax_cross_entropy_with_logits()很长,但也很好用,参考链接:
https://blog.csdn.net/mao_xiao_feng/article/details/53382790
下面是我的运行结果:

可以看到,我测试了一下其中某一个数据,结果预测是“8”。可以看到单个数据的预测结果,这一丢丢是我相对原代码进行了修改的。
问:为什么accuracy才0.59?
答:因为我才迭代一万次。。。准确率还没提上去
第二种实现
#这个是构建模型的文件 mnist.py
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import math
import tensorflow as tf
# The MNIST dataset has 10 classes, representing the digits 0 through 9.
NUM_CLASSES = 10
# The MNIST images are always 28x28 pixels.
IMAGE_SIZE = 28
IMAGE_PIXELS = IMAGE_SIZE * IMAGE_SIZE
#从图像输入层一直到准备链接softmax之前的10个输出(可以作为全连接的模板)
def inference(images, hidden1_units, hidden2_units):
#images : [000000...0000000]
#weights: [000000]
# [000000]
# ....
# [000000]
#biases: [000000]
with tf.name_scope('hidden1'):
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases')
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
# Hidden 2
with tf.name_scope('hidden2'):
weights = tf.Variable(
tf.truncated_normal([hidden1_units, hidden2_units],
stddev=1.0 / math.sqrt(float(hidden1_units))),
name='weights')
biases = tf.Variable(tf.zeros([hidden2_units]),
name='biases')
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
# Linear
with tf.name_scope('softmax_linear'):
weights = tf.Variable(
tf.truncated_normal([hidden2_units, NUM_CLASSES],
stddev=1.0 / math.sqrt(float(hidden2_units))),
name='weights')
biases = tf.Variable(tf.zeros([NUM_CLASSES]),
name='biases')
logits = tf.matmul(hidden2, weights) + biases
return logits
#损失函数:使用了inference最后10个输出,通过softmax,与标签计算cross_entropy的平均值作为损失
def loss(logits, labels):
#labels is not noe-hot style
labels = tf.to_int64(labels)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name='xentropy')
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')
return loss
#给可视化tensorboard传递损失值,定义训练方法
def training(loss, learning_rate):
#for visualize of loss
tf.scalar_summary(loss.op.name, loss)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
#counter the step num
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
return train_op
#计算准确的个数
def evaluation(logits, labels):
correct = tf.nn.in_top_k(logits, labels, 1)
#bool转变成int32,并求和
return tf.reduce_sum(tf.cast(correct, tf.int32)) #这个是评价模型的文件 fully_connected_feed.py
#system
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os.path
import time
from six.moves import xrange # pylint: disable=redefined-builtin
#加载数据
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #数据源
from tensorflow.examples.tutorials.mnist import mnist #模型在这里
# 模型的基本参数,类似C语言开头的defined.用spyder运行的话会报错,得用CMD运行
# 可以试试别的定义超参数的方式。
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_float("learning_rate", 0.01, "The learning rate")
flags.DEFINE_integer('max_steps', 2000, 'Number of steps to run trainer.')
flags.DEFINE_integer('hidden1', 128, 'Number of units in hidden layer 1.')
flags.DEFINE_integer('hidden2', 32, 'Number of units in hidden layer 2.')
flags.DEFINE_integer('batch_size', 100, 'Batch size. '
'Must divide evenly into the dataset sizes.')
flags.DEFINE_string('train_dir', 'data', 'Directory to put the training data.')
flags.DEFINE_boolean('fake_data', False, 'If true, uses fake data '
'for unit testing.')
#占位符(就如同神经网络的接口):一组图像以及对应的标签(不是one-hot的)
def placeholder_inputs(batch_size):
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))
return images_placeholder, labels_placeholder
#给占位符对应真实的数据。false表示非one-hot数据
def fill_feed_dict(data_set, images_pl, labels_pl):
# Create the feed_dict for the placeholders filled with the next `batch size` examples.
# data_set : the original data class of images and labels from input_data.read_data_sets(), like mnist in CNN_MNIST
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size,FLAGS.fake_data)
# python dictionary
feed_dict = {
images_pl: images_feed,
labels_pl: labels_feed,
}
return feed_dict
#验证准确率就比较综合了:
#sess提供了下面这一堆运行空间的接口
#*_placeholder提供了训练好的网络的接口
#data_set是不同的数据集(训练集、测试集、验证集)
#eval_correct是集合数据验证正确的个数总和
def do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_set):
#获得一些相关常数
true_count = 0
steps_per_epoch = data_set.num_examples // FLAGS.batch_size
num_examples = steps_per_epoch * FLAGS.batch_size
#每一代的每一步都分开计算:因为fill_feed_dict中已经定义死了每次获取FLAGS.batch_size数据
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set,images_placeholder,labels_placeholder)
true_count += sess.run(eval_correct, feed_dict=feed_dict)
precision = true_count / num_examples
print(' Num examples: %d Num correct: %d Precision @ 1: %0.04f' %
(num_examples, true_count, precision))
#训练的主体部分
def run_training():
#"train_dir" is "data", the folder contains all mnist data
#指明数据源
data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)
#指定使用的操作所在的图(graph):其实大多数情况只要一个graph就可以了,这里为了完整性
with tf.Graph().as_default():
# 首先是构建网络图片数据和标签数据的占位符,指定他们的结构,好往上搭积木
images_placeholder, labels_placeholder = placeholder_inputs(FLAGS.batch_size)
# 构建网络主体,也就是推理部分(inference部分)
logits = mnist.inference(images_placeholder,FLAGS.hidden1,FLAGS.hidden2)
# 根据推理部分的结果和对应的真实标签构建损失函数
loss = mnist.loss(logits, labels_placeholder)
# 根据损失函数和学习速率构建训练过程
train_op = mnist.training(loss, FLAGS.learning_rate)
# 根据推理部分的结果和对应的真实标签计算给定数据的准确率(是一个总和)
eval_correct = mnist.evaluation(logits, labels_placeholder)
# 收集图表的信息,用于给Tensoroard提供信息。因为tf版本的问题,这里要改改
summary_op = tf.summary.merge_all()
# 初始化网络的参数
init = tf.initialize_all_variables()
# 主要是记录训练的参数
saver = tf.train.Saver()
# 指定Session
sess = tf.Session()
# 与summary_op是配套的,用于具体地操作收集的信息,比如写到缓冲区等。因为tf版本的问题,这里要改改
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
#运行参数初始化
sess.run(init)
# 进入训练环节
for step in xrange(FLAGS.max_steps):
start_time = time.time()#先记录这一步的时间
#获取这一步用于训练的batch数据
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
#按照给定的数据训练(feed_dict)、给定的训练方法(train_op),训练一次网络
#顺便获得训练之前损失函数的值(注:train_op没有输出,所以是“_”)
_, loss_value = sess.run([train_op, loss],feed_dict=feed_dict)
#训练完一次,赶紧计算一下消耗了多少时间
duration = time.time() - start_time
#下面都是一些为了方便调试而输出的各种验证信息和关心的主要参数
# 每隔训练100步就把:步数、损失函数的值、使用的时间直接输出
if step % 100 == 0:
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration))
# 然后把图表运行的信息写到缓冲区,更新磁盘文件
summary_str = sess.run(summary_op, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)
summary_writer.flush()
# 每隔1000步就保存训练数据一次,并验证一下训练集、验证集、测试集的准确率
if (step + 1) % 1000 == 0 or (step + 1) == FLAGS.max_steps:
checkpoint_file = os.path.join(FLAGS.train_dir, 'checkpoint')
saver.save(sess, checkpoint_file, global_step=step)
# Evaluate against the training set.
print('Training Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
# Evaluate against the validation set.
print('Validation Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
# Evaluate against the test set.
print('Test Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test)
def main(_):
run_training()
if __name__ == '__main__':
tf.app.run() 在用这份代码的时候,我遇到了两个问题:
1)用Spyder运行不了。原来是因为…
https://www.jianshu.com/p/a8f0b9c9dc58
2)因为tf版本不一样,有些函数不一样了
https://blog.csdn.net/s_sunnyy/article/details/70999462
另,这份代码不是采用one-hot编码。one-hot编码,其实就是上面那份代码的结果那样,结果只命中【0-9】中的一个位置,比如上面那个代码的结果是命中了【8】。参考链接:
https://blog.csdn.net/google19890102/article/details/44039761
下面是我的运行结果:
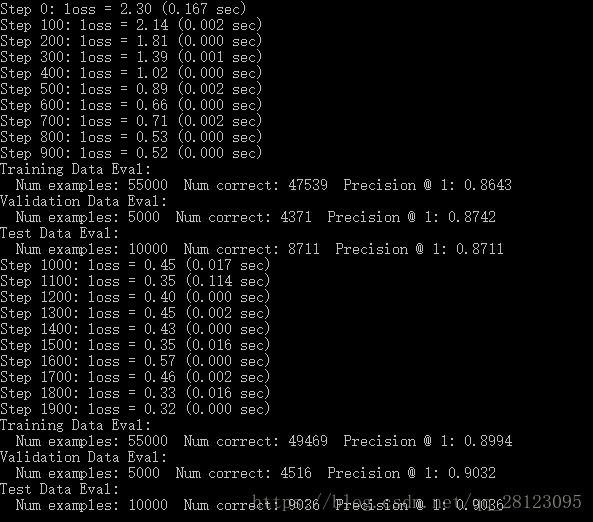
下面是tensorboard可视化:

这个是网络结构
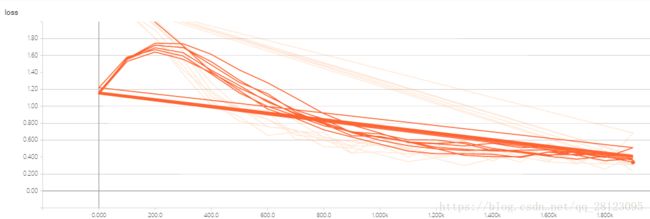
这个是loss随着step的变化。
PS:
第一种实现中,10000次迭代,accuracy才0.6
第二种实现中,2000次迭代,accuracy就有0.9
这是为什么呢?有如下猜测:
1.两者learning rate不同
2.两者batch_size不同
3.两者网络结构不同
当我把1,2都调成一样之后,第一种实现中的accuracy还是很低。那么,是网络结果的问题了。但是,明显第二种实现中的网络更为简单,accuracy却更高,这是为何?
(留坑)