Selenium3自动化测试——21.数据驱动应用
往往我们需要通过数据集合直接驱动应用,这里通过循序渐进的三种方式来描述。
1. 通过csv获取数据并驱动应用
baidu_data.csv文件如下:
name,search_key
case1,selenium
case2,unittest
case3,parameterized
test1_baidu_data.py文件如下:
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver
class TestBaidu(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com"
@classmethod
def tearDownClass(cls):
cls.driver.quit()
def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3)
def test_search(self):
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
search_key = line[1]
self.baidu_search(search_key)
if __name__ == '__main__':
unittest.main(verbosity=2)
结果:打开百度浏览器后,依次输入关键字selenium,unittest,parameterized,依次得到三个搜索界面。
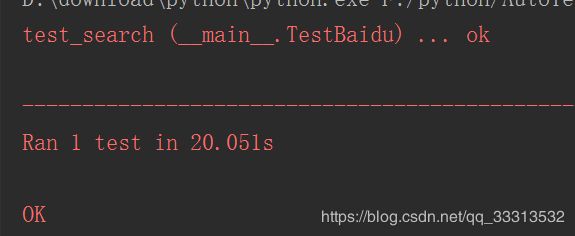
缺点:如果有一个数据没有获取到就会影响后续数据的解析。
2.将数据获取后存储到数组中,再创建不同测试方法使用数据
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver
class TestBaidu(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com"
cls.test_data = []
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
cls.test_data.append(line)
@classmethod
def tearDownClass(cls):
cls.driver.quit()
def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3)
def test_search_selenium(self):
self.baidu_search(self.test_data[0][1])
def test_search_unittest(self):
self.baidu_search(self.test_data[1][1])
def test_search_parameterized(self):
self.baidu_search(self.test_data[2][1])
if __name__ == '__main__':
unittest.main(verbosity=2)
结果:先测试parameterized--selenium--unittest

3. 使用Parameterized实现参数化
1)安装parameterized
pip install parameterized
2)实现百度搜索的测试
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver
from parameterized import parameterized
class TestBaidu(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com"
@classmethod
def tearDownClass(cls):
cls.driver.quit()
def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(2)
# 通过Parameterized实现参数化,case1--定义测试用例的名称,selenium--定义搜索的关键字
@parameterized.expand([
("case1", "selenium"),
("case2", "unittest"),
("case3", "parameterized"),
])
def test_search(self, name, search_key):
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
if __name__ == '__main__':
#执行更详细的执行日志
unittest.main(verbosity=2)
步骤1)导入Parameterized
2)通过@parameterized.expand()装饰测试用例
3)使用unittest的main方法,设置verbosity参数为2,输出更详细的执行日志。
得到的结果如下:
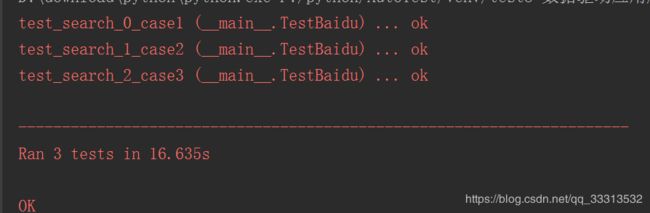
通过@parameterized.expand()中元组的个数来统计测试用例数,产生3条测试用例。