一道看了答案都不知道为什么的面试题
❝扫描下方二维码或者微信搜索公众号
❞菜鸟飞呀飞,即可关注微信公众号,阅读更多Spring源码分析、Java并发编程、Netty源码系列和MySQL工作原理文章。

题目
经常看到一道面试题,题目如下,每次都是猜答案,几乎每次都猜错。看到答案后,也无法解释为什么,直到最近学习了 JVM 相关的知识,才理解透彻。
// 运行环境为JDK版本1.8
public static void main(String[] args) {
String s1 = new String("1");
s1.intern();
String s2 = "1";
System.out.println(s1 == s2); // false String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4); // true } 这道题在 JDK1.8 的环境下运行(注意:这道题与 JDK 的版本密切相关,不同版本会有不同的答案),结果分别为 false、true。s1 和 s2 的比较结果,很容易判断,而对于 s3 和 s4 的比较结果,则就不太好理解了,接下来将从字节码和 JVM 内存结构的角度来解释一下运行结果。
intern()
intern()方法是 String 类提供的一个方法,当调用一个字符串对象 s 的 intern()方法时,会先判断字符串常量池中是否存在 s 所表示的字面量(这个判断过程使用的是字符串的 equals()进行比较的,即比较的是字符串的内容),如果字符串常量池中存在该字面量,则 intern()方法不做任何操作,直接返回常量池中该字面量的地址;如果字符串常量池中不存在该字面量,那么就将该字面量放入到字符串常量池中(也就是在常量池中造了一个"对象"),然后返回常量池中该字面量的地址。
这里的关键点在于字符串常量池,在 JVM 虚拟机规范中,字符串常量池是属于方法区的一部分,而方法区只是 Java 虚拟机规范中的概念,具体如何去实现方法区,是由各个虚拟机厂商自己决定的。并且同一厂商实现的虚拟机,在不同版本中也存在不同的区别。例如 HotSpot 虚拟机,在 JDK1.6 中,整个方法区都是在永久代(PermGem)实现的;到了 JDK1.7 中,方法区也是在永久代(PermGem)实现的,但与 JDK1.6 不同的是,将方法区中的运行时常量池和字符串常量池放到了堆空间,而其他部分在还是在永久代中;再到 JDK1.8 时,则是用元空间(Metaspace)实现的方法区,即用元空间(Metaspace)取代了永久代(PermGem),元空间使用的是直接内存,但是方法区中的运行时常量池和字符串常量池依旧是在堆空间,这和 JDK1.7 是相同的。如下面的示意图所示。 
从 JDK1.6 到 JDK1.8,字符串常量池从永久代移到堆内存,对于 intern()方法,也产生了一定的变化。
「假设现在有字符串对象 s(这个对象 s 是处于堆中的),它的字符串的内容是"aa"(即字面量为"aa"),并且假设字符创常量池中也不存在字面量"aa"」 。那么在 JDK1.6 中,当调用 s.intern()方法时,由于字符传常量池中不存在"aa",所以此时会在字符串常量池中(永久代)创建一个字符串"aa",示意图如下。 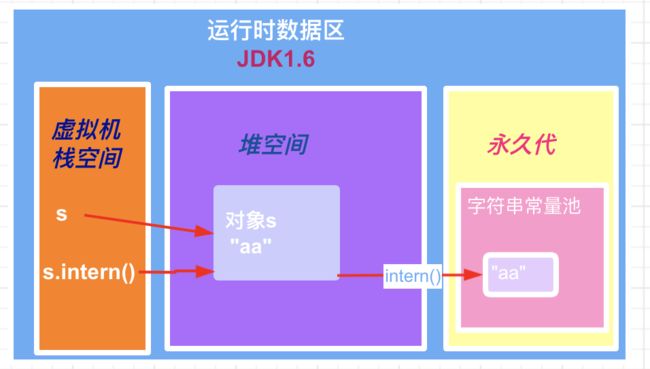
而在 JDK1.7、JDK1.8,或者更高版本中,当调用 s.intern()方法时,由于字符传常量池中不存在"aa",所以此时也需要在字符串常量池中创建一个字面量"aa",但是注意此时与 JDK1.6 不同的是,字符串常量池被移到了堆内存当中,所以当此时在字符串常量池中创建一个字面量"aa"时,虚拟机发现堆内存中已经存在了字符串的值为"aa"的对象 s,所以此时只是在字符串常量池中创建一个指针,指针指向的是堆内存当中对象 s 的地址,示意图如下。(搞清楚这一点非常重要) 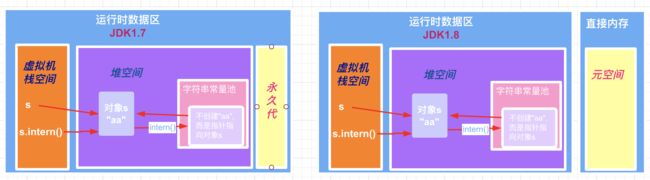
JDK1.7 及以后的版本中,对于 intern()方法为什么要这么设计呢?我觉得原因可能是:「节省堆空间」。将字符串常量池从永久代移到堆空间后,我们创建的对象和字符串常量池都处于堆中,如果在调用 intern()方法时,再在字符串常量池创建一个字符串对象,这就和堆中的对象重复了,如果直接使用一个指针,指向堆中的对象,这样就可以节省堆空间了。(对于在字符创常量池中创建指针这个说法,并不一定准确,这里这是为了方便描述。对于 intern()方法,在 1.7 及以上版本中,你也可以理解为是直接将堆中对象 s 移到字符串常量池中,这样最终的结果同样是只会有一个"aa")。
解答开篇
前面铺垫了那么多,终于可以解释一下开篇题目的前一半了。
String s1 = new String("1");
s1.intern();
String s2 = "1";
System.out.println(s1 == s2); // false
- 当执行完 「String s1 = new String("1")」 时,会创建出两个对象:1) 字符串常量池中字面量为"1"的字面量;2)堆中 s1 字符串对象;
- 当执行 「s1.intern()」 时,由于字符串常量池中已经存在了字面量"1",所以 intern()方法不做任何操作,仅仅只是返回字符串常量池中字面量"1"的地址(虽然返回了常量池中字符串"1"的地址,但是我们并没有用变量去接收这个返回值,所以这一行代码可以理解为啥也没干);
- 执行 「String s2 = "1"」 时,由于字符串常量池中已经存在了字面量"1",所以此时 s2 指向的就是字符串常量池中"1"的地址;
- 因此在判断 「s1 == s2」 的时候,由于 s1 指向的是堆空间的对象,s2 指向的是字符串常量池中的对象,因此最终结果为 false。
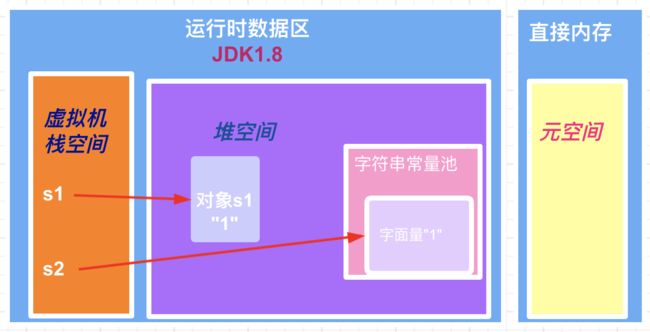 s1==s2
s1==s2
对于 s1 和 s2 的判断,相对而言比较简单,也比较好理解。不需要从字节码角度就能得出正确的答案。而对于 s3 和 s4 的比较,就必须得从字节码的角度,才能得出正确答案了。
new String("1") + new String("1")的字节码指令
在解释 s3 和 s4 之前,需要搞清楚这样一个问题:「String s = new String("1") + new String("1")」 在 JVM 底层是如何实现字符串的拼接的。为了方便说明描述,我定义了如下一个方法。
public void append(){
String s = new String("1") + new String("1");
}
接下来来看一下该方法的字节码,查看字节码的方法有很多,可以通过「javap -v 文件名」 ,也可以通过第三方工具,例如「jclasslib」,也可以在 IDEA 中安装该插件。最终看到的字节码如下图所示。 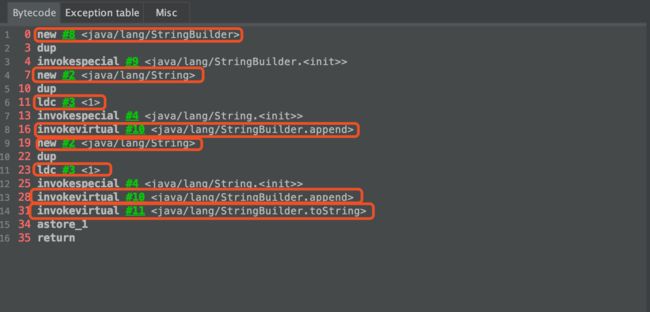
字节码的重点部分我用红色框标记出来了,下面解释一下。
- 首先 new 了一个 StringBuilder 对象,因此可以看出来,对于上面的字符串拼接操作,其底层采用的是 StringBuilder 来进行拼接的。
- 创建了一个 String 对象,也就是对应字符串拼接的前半部分;
- 然后通过字节码指令 「ldc」从字符串常量池中加载了一个字面量"1",随后赋值给 2 中创建的 String 对象;
- 调用 StringBuilder 的 append 方法进行拼接;
- 接着又创建了一个 String 对象,也就是对应字符串拼接的后半部分;同样也是通过字节码指令 「ldc」从字符串常量池中加载了一个字面"1",随后赋值给刚刚创建的 String 对象;
- 接着又调用 StringBuilder 的 append 方法进行拼接;
- 最后调用 StringBuilder 的 toString()方法,然后将结果返回。
至此,我们可以看下,这一步一共产生了多少个对象。堆中:1 个 StringBuilder 对象、2 个 String 对象,然后字符串常量池中一个字面量"1",也就是 4 个对象。
然而,真的只有 4 个对象吗?其实不止,因为最后还调用了「StringBuilder 的 toString()」 方法,我们可以看下 StringBuilder.toString()方法的源码以及字节码,如下图所示。
 StringBuilder.toString()源码
StringBuilder.toString()源码
从图中可以发现,在 StringBuilder.toString()中,也会创建一个新的 String 对象,因此我们示例中这个字符串操作,最终会产生 5 个对象。从这个结论中,我们也可以理解,「为什么在进行多个字符串拼接时,尽量不要使用 "加号" 这种连字符」,因为在 JVM 中会 new 很多对象,效率不高。
另外,上面的分析中,其实还隐藏着另外一个结论:两个"1"进行拼接后,结果为"11",「而这个字符串"11"实际上只是存在于堆空间中的一个对象,在字符串常量池中,并不存在字面量"11",只存在"1"」 。 理解这一点是解答开篇中「s3==s4」结果的关键。
解释
接下来解释一下为什么「s3==s4」为什么在 JDK1.8 下,运行结果为 true。
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4); // true
- 首先执行完 「String s3 = new String("1") + new String("1")」 后,s3 指向的是堆空间对象地址,并且在字符串常量池中并没有产生字面量"11";
- 由于第 1 步中,在字符串常量池中并没有产生字面量"11",所以调用 「s3.intern()」 方法时,会向字符常量池中尝试创建一个字面量"11"。又因为这是在 JDK1.8 环境下,所以此时在字符串常量池中不会真的创建一个字面量"11",而是创建一个指针,指针指向的是堆空间中的上 s3 的对象。(至于为什么,前面在介绍 intern()方法时已经解释了具体原因)
- 执行 「String s4 = "11"」 时,发现字符串常量池中存在字面量"11"的指针,这个字面量指针指向的是 s3 对象的地址,因此 s4 也会指向 s3 的对象的地址;
- 因此 s3 和 s4 都指向的是堆空间的同一个对象,所以结果为 true。
示意图如下。 
相似问题
现在把这道题的前提条件修改为在「JDK1.6」中运行,结果又会不一样。「输出结果两个均为 false」,这又是为什么呢?
对于 s1 和 s2 的判断结果比较好理解,一个指针指向堆空间,一个指针指向永久代,所以结果为 false。而对于 s3 和 s4 的比较,就有点不一样了。因为在 JDK1.6 中,字符串常量池是处于永久代中的,当 s3 调用 intern()方法时,如果字符串常量池中不存在"11",则会创建一个字面量"11",而不像 JDK1.8 中,会让字符创常量池的指针指向堆中的对象。因此最终 s3 指向的是堆空间中的对象,而 s4 指向的是永久代中字符串常量池中的对象,这两个地址不一样,因此结果为 false。
再把这道题做一下稍微做一下修改,把「s3.intern()」 这一行代码向下移动一行,运行环境依然是 JDK1.8,代码如下,那么运行结果是多少呢?
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
这个时候,结果就变成了 false。为什么?这是因为 s3 在创建完成时,字符串常量池中还不存在字面量"11",然后我们执行「String s4 = "11"」 会直接向字符串常量池中添加一个字面量为"11"的字符串(因为使用字节码中使用的是「ldc」字节码指令),此时 s4 指向的地址是字符串常量池。当我们再调用「s3.intern()」 时,由于字符串常量池已经存在了"11",所以 intern()方法什么事都不会干。因此最终 s3 指向的是堆空间,而 s4 指向的是字符串常量池,所以最后结果为 false。
总结
实际上,与这道面试题相似的题目很多,如果要对这类问题准确得出答案,其根本上需要对字符串拼接的原理比较熟悉,需要熟悉字符串拼接符号「加号」的底层原理,它在字节码上是如何实现的,另外还需要明白 JVM 中运行时数据区的结构,以及在 JDK 不同版本中,它们有什么细微的区别。
事实上,这类题目,我们在实际工作中基本不会遇到,也只会在面试时可能会遇到,那搞清楚它又有什么意义呢?实际上它考察的是一个开发人员的基本功,对 JVM 的了解程度。这也是最近笔者在学习 JVM 方面的一点心得,以前碰到这类面试题搞不明白时基本都是背答案,但是题目稍微做一点改动,往往会得出错误的答案。而如果从 JVM 的角度去理解,那么这类题对我们而言,也只是换个不同的壳子。
❞