准确分词:加载自定义字典分词(pyhanlp分词示例)
目录
一、pyhanlp
1.1基本介绍
1.2 pyhanlp加入字典
二、分词对比
tokenizer.py :hanlp函数
cut_data.py 主文件
全部代码、数据集:https://github.com/455125158/NLP_basis
一、pyhanlp
1.1基本介绍
pyhanlp介绍:https://github.com/hankcs/pyhanlp
pyhanlp在线演示:http://hanlp.com/?sentence=%E4%B8%8B%E9%9B%A8%E5%A4%A9%E5%9C%B0%E9%9D%A2%E7%A7%AF%E6%B0%B4
中文分词≠自然语言处理!
中文分词只是第一步;HanLP从中文分词开始,覆盖词性标注、命名实体识别、句法分析、文本分类等常用任务,提供了丰富的API。
不同于一些简陋的分词类库,HanLP精心优化了内部数据结构和IO接口,做到了毫秒级的冷启动、千万字符每秒的处理速度,而内存最低仅需120MB。无论是移动设备还是大型集群,都能获得良好的体验。
不同于市面上的商业工具,HanLP提供训练模块,可以在用户的语料上训练模型并替换默认模型,以适应不同的领域。项目主页上提供了详细的文档,以及在一些开源语料上训练的模型。
HanLP希望兼顾学术界的精准与工业界的效率,在两者之间取一个平衡,真正将自然语言处理普及到生产环境中去。
我们使用的pyhanlp是用python包装了HanLp的java接口。
pyhanlp常用API:
from pyhanlp import *
print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))
for term in HanLP.segment('下雨天地面积水'):
print('{}\t{}'.format(term.word, term.nature)) # 获取单词与词性
testCases = [
"商品和服务",
"结婚的和尚未结婚的确实在干扰分词啊",
"买水果然后来世博园最后去世博会",
"中国的首都是北京",
"欢迎新老师生前来就餐",
"工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作",
"随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。"]
for sentence in testCases: print(HanLP.segment(sentence))
# 关键词提取
document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," \
"根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \
"有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \
"严格地进行水资源论证和取水许可的批准。"
print(HanLP.extractKeyword(document, 2))
# 自动摘要
print(HanLP.extractSummary(document, 3))
# 依存句法分析
print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))
1.2 pyhanlp加入字典
- 添加hanlp分词自定义词典,在"D:\anaconda1\Lib\site-packages\pyhanlp\static\data\dictionary\custom"下
2.2.1.删除"CustomDictionary.txt.bin"(这是缓存文件删了没事)
2.2.2.在“CustomDictionary.txt”中添加你想不要分词的词语,因为下面我选用的是医学类的文章,所以我添加几个医用名称。
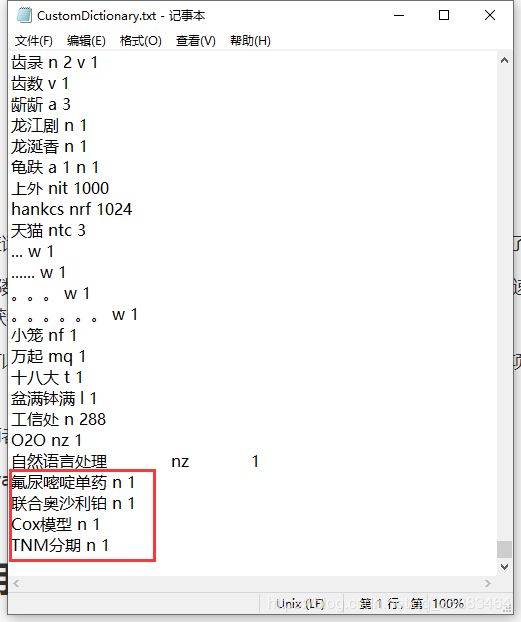
添加格式为:“词” “词性” “词频” ,中间用空格隔开。
二、分词对比
-
tokenizer.py :hanlp函数
pyhanlp处理文本分词基本格式,有很好移植型。
from pyhanlp import *
def to_string(sentence,return_generator=False):
if return_generator:
return (word_pos_item.toString().split('/') for word_pos_item in HanLP.segment(sentence))
# toString()转化为str
else:
return " ".join([word_pos_item.toString().split('/')[0] for word_pos_item in HanLP.segment(sentence)])
# 这里的“”.split('/')可以将string拆分成list 如:'ssfa/fsss'.split('/') => ['ssfa', 'fsss']
def seg_sentences(sentence,with_filter=True,return_generator=False):
segs=to_string(sentence,return_generator=return_generator)
if with_filter:
g = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ' and word_pos_pair[1] not in drop_pos_set]
else:
g = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ']
return iter(g) if return_generator else g
def cut_hanlp(raw_sentence,return_list=True):
'''
:param raw_sentence: 输入的文本
:param return_list: 设置返回格式,True是返回[]
:return:
'''
if len(raw_sentence.strip())>0:
return to_string(raw_sentence) if return_list else iter(to_string(raw_sentence))
-
cut_data.py 主文件
#-*- coding=utf8 -*-
import jieba
import re
from tokenizer import cut_hanlp
jieba.load_userdict("dict.txt") # jieba字典
def merge_two_list(a, b):
c=[]
len_a, len_b = len(a), len(b)
minlen = min(len_a, len_b)
for i in range(minlen):
c.append(a[i])
c.append(b[i])
if len_a > len_b:
for i in range(minlen, len_a):
c.append(a[i])
else:
for i in range(minlen, len_b):
c.append(b[i])
return c
if __name__=="__main__":
fp=open("text.txt","r",encoding="utf8")
fout=open("result_cut.txt","w",encoding="utf8")
regex1=u'(?:[^\u4e00-\u9fa5()*&……%¥$,,。.@! !]){1,5}期' # 非汉字xxx期
regex2=r'(?:[0-9]{1,3}[.]?[0-9]{1,3})%' # xx.xx%
p1=re.compile(regex1)
p2=re.compile(regex2)
for line in fp.readlines():
result1=p1.findall(line) # 返回匹配到的list
# print(result1)
if result1:
regex_re1=result1
line=p1.sub("FLAG1",line) # 将匹配到的替换成FLAG1
# print(line)
result2=p2.findall(line)
if result2:
line=p2.sub("FLAG2",line)
# print(line)
words=jieba.cut(line) # 结巴分词,返回一个generator object
result = " ".join(words) # 结巴分词结果 本身是一个generator object,所以使用 “ ”.join() 拼接起来
words1=cut_hanlp(line) # hanlp分词结果,返回的是str
if "FLAG1" in result:
result=result.split("FLAG1")
result=merge_two_list(result,result1)
ss = result
result="".join(result) # 本身是个list,我们需要的是str,所以使用 "".join() 拼接起来
if "FLAG2" in result:
result=result.split("FLAG2")
result=merge_two_list(result,result2)
result="".join(result)
# print(result)
fout.write("jieba :"+result)
fout.write("hanlp:"+str(words1))
fout.close()
最后结果:

基本一致