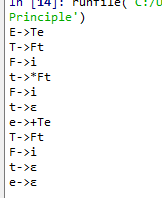语法分析-LL(1)分析的python实现
语法分析:将切分的单词序列组合成各类短语短语,常见的方法:自上而下,自下而上。
LL(1):左扫描,左推导。
大体步骤:
1.从文件或其他方式导入\储存文法(实质就是几行符号流) 并把其中的终结字符和非终结字符存在数组\列表里
2.把文法每行的“或”(|)切分成两个即A->B|C 切分为A->B和A->C
for i in gramma:
ss=i[0:1]
j=0
while j':
break
j+=1
j+=1 #找到->后的第一个位置
while j 3.根据文法创建first集和follow 集
(1)first:在切分后的文法中 如果A->a…… (a为终结字符)则把a放入A的follow中 如果A->B ……(B为非终结) 则先递归求B的first,然后放入A的first
(2)follow::先把‘$’放入开始字符(E)的follow;存在 ……Ab(b为非终结),则把b放入A的follow ;存在AB(B为非终结),则把B的first放入A的follow;存在B=EAC,且C的first中含有‘ε’,则把B的follow放入A的follow;若A为某段的最后字符,则把‘$’放入A的follow;若B=……A,则把B的follow放入A的follow
def GetFirst(stack_item):
if stack_item[1] in vt:#产生式第一个为终结
first[stack_item[0]].add(stack_item[1])#将其放入第一个的first
else:
for find_item in stack:
if find_item[0]==stack_item[1]:
GetFirst(find_item)
first[stack_item[0]]=first[stack_item[1]]|first[stack_item[0]]
def GetFollow(vi_item):
for i in stack:
j=1
while j4.求预测分析表(代码使用双重字典)
对于每个产生式A->alpha 执行(1)(2)
(1)对first(alpha)中的每一个终结字符a,把A->alpha放入M[A,a]
(2)如果ε在first(alpha)中,对于follow(alpha)的每一个终结字符b,把A->alpha放入M[A,b](包括$)
写了半天并没有写出来 于是就手动建了。。。
6.对输入的记号流进行分析:
设w为记号流 ip为指向第一个符号 设S为栈 初始只有开始元素E和$($在最低)
while(栈顶不是$){
如果 栈顶与ip指向符号相同,则栈弹出,ip指向下一个
否则如果栈顶为终结符,则出错
否则如果栈顶和ip指向符号所在的分析表不存在,则出错
否则如果存在,先输出预测表中对应的产生式,然后弹出栈顶元素,并把产生式->后的元素逆序压入栈中
}
完整代码:
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 1 12:32:13 2019
@author: 71405
"""
from collections import defaultdict
def addtwodimdict(thedict, key_a, key_b, val):
if key_a in thedict:
thedict[key_a].update({key_b: val})
else:
thedict.update({key_a:{key_b: val}})
def GetFirst(stack_item):
if stack_item[1] in vt:#产生式第一个为终结
first[stack_item[0]].add(stack_item[1])#将其放入第一个的first
else:
for find_item in stack:
if find_item[0]==stack_item[1]:
GetFirst(find_item)
first[stack_item[0]]=first[stack_item[1]]|first[stack_item[0]]
def GetFollow(vi_item):
for i in stack:
j=1
while j':
break
j+=1
j+=1 #找到->后的第一个位置
while jTe')
addtwodimdict(ana_table, 'E', '(', 'E->Te')
addtwodimdict(ana_table, 'e', '+', 'e->+Te')
addtwodimdict(ana_table, 'e', ')', 'e->ε')
addtwodimdict(ana_table, 'e', '$', 'e->ε')
addtwodimdict(ana_table, 'T', 'i', 'T->Ft')
addtwodimdict(ana_table, 'T', '(', 'T->Ft')
addtwodimdict(ana_table, 't', '+', 't->ε')
addtwodimdict(ana_table, 't', '*', 't->*Ft')
addtwodimdict(ana_table, 't', ')', 't->ε')
addtwodimdict(ana_table, 't', '$', 't->ε')
addtwodimdict(ana_table, 'F', 'i', 'F->i')
addtwodimdict(ana_table, 'F', ')', 'F->(E)')
sen="i*i+i$"
ip=0
ss=['$','E']
while ss[len(ss)-1]!='$':
print(ss)
print(sen[ip])
if ss[len(ss)-1]==sen[ip]:
ss.pop()
ip+=1
elif ss[len(ss)-1] in vt:
print("error1")
break
elif sen[ip] not in ana_table[ss[len(ss)-1]]:
print("error2")
break
elif sen[ip] in ana_table[ss[len(ss)-1]]:
strings=ana_table[ss[len(ss)-1]][sen[ip]]
print(strings)
ss.pop()
j=len(strings)-1
while j>2:
if strings[j]!='ε':
ss.append(strings[j])
j-=1
使用的文法为《编译原理》高等教育出版社第三章3.8文法 其中为了方便考虑E‘表示为e T’同理
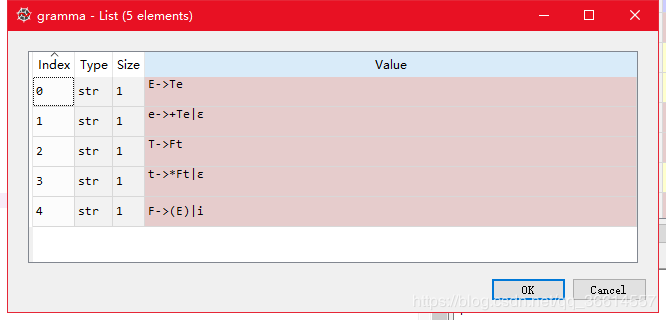
文法(gramma):
切分后(stack):->已经省略

first集与follow集合:(不知道为啥多了一行 ,但没有value ,还没来得及修改)

最后分析结果: