TensorFlow+CNN+OpenCV快速识别中文验证码
声明:文章仅源自个人兴趣爱好,不涉及他用,侵权联系删。
转载请注明:转自此博文https://leejason.blog.csdn.net/article/details/106150572
TensorFlow+CNN+OpenCV快速识别中文验证码
- 1 项目简介
- 1.1 关于验证码识别
- 1.2 此次识别的验证码类型
- 1.3 最初解决方法
- 1.4 项目文件
- 1.5 涉及到的python库
- 1.6 模型结构
- 2 项目流程
- 2.1 采集验证码图片
- 2.2 处理图片
- 2.2.1 灰度化效果
- 2.2.2 二值化效果
- 2.2.3 图像滤波、降噪:
- 2.3 构建目标值
- 2.4 读取图片
- 2.5 建立文件名与特征值映射
- 2.6 再次建立此次读取 文件名 与 特征值 之间的联系
- 2.7 构建卷积神经网络,获取y_predict
- 2.8 构造损失函数
- 2.9 优化损失
- 2.10 计算准确率
- 2.11 模型训练与保存
- 3 预测
1 项目简介
本项目使用了卷积神经网络(CNN),基于TensorFlow深度学习框架,该框架封装了非常通用的校验、训练、验证、识别和调用 API,两者结合极大地降低了验证码识别的成本和时间精力。
当初刚接触神经网络这块写的一个项目,网格什么的都是采用最简单的,也没有优化什么的。但是识别率的话达到99.99%,基本百分百了,处理此次验证码基本是足够了。
1.1 关于验证码识别
验证码识别大多是爬虫会遇到的问题,也可以作为图像识别的入门案例。这里介绍一下使用传统的图像处理和机器学习算法,它们都涉及多种技术:
图像处理
-
前处理(灰度化、二值化)
-
图像分割
-
裁剪(去边框)
-
图像滤波、降噪
-
去背景
-
颜色分离
-
旋转
机器学习
- KNN
- SVM
使用这类方法对使用者的要求较高,且由于图片的变化类型较多,处理的方法不够通用,经常花费很多时间去调整处理步骤和相关算法。
而使用卷积神经网络,只需要通过简单的前处理,就可以实现大部分静态字符型验证码的端到端识别,效果很好、通用性很高。
1.2 此次识别的验证码类型
验证码图片如下
![]()
![]()
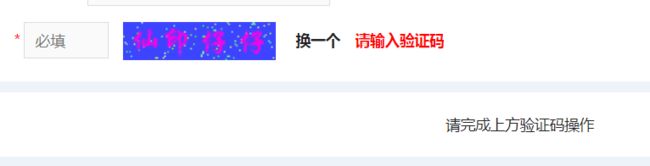
概括一下,就是中文汉字验证码,汉字带有字体,外加背景干扰。
1.3 最初解决方法
最初,是借助打码平台解决的,一张验证码图片40积分(折合人民币4分钱一次),对于每天请求几万、几十万次来说,长时间下来是笔不小的开支了,所以自行识别验证码就显得很有必要。
1.4 项目文件
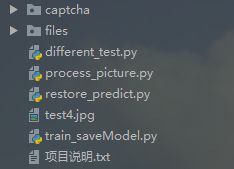
| 文件名 | 说明 |
|---|---|
| process_picture.py | right-aligned 文本居右 |
| different_test.py | 测试文件 |
| train_saveModel.py | 读取文件及训练模型扥 |
| restore_predict.py | 加载模型预测 |
| files | 存放初始验证码、训练好的模型 |
| captcha | 处理过的验证码图片 |
1.5 涉及到的python库
- tensorflow
- requests
- matplotlib
- pandas
- numpy
- cv2
- re
- os
- glob
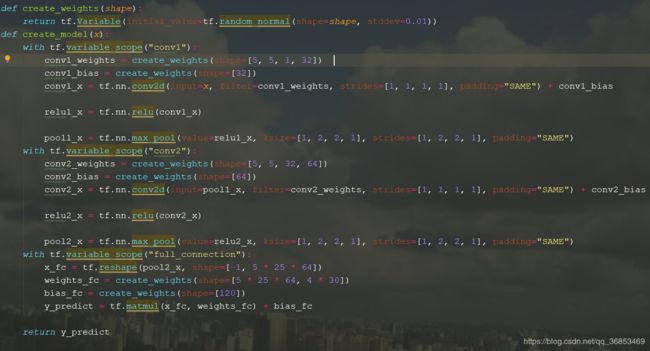
1.6 模型结构
采用先对简单的两层卷积+全连接:
| 序号 | 层级 |
|---|---|
| 输入 | input |
| 1 | 卷积层+激活层+池化层 |
| 2 | 卷积层+激活层+池化层 |
| 3 | 全连接层 |
| 输出 | output |
2 项目流程
2.1 采集验证码图片
要识别验证码,就需要大量的验证码图片用来构建训练集与测试集,所以用爬虫脚本抓取了20000张验证码图片:
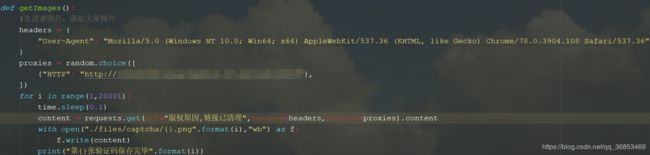
采集效果:
2.2 处理图片
2.2.1 灰度化效果

2.2.2 二值化效果

2.2.3 图像滤波、降噪:
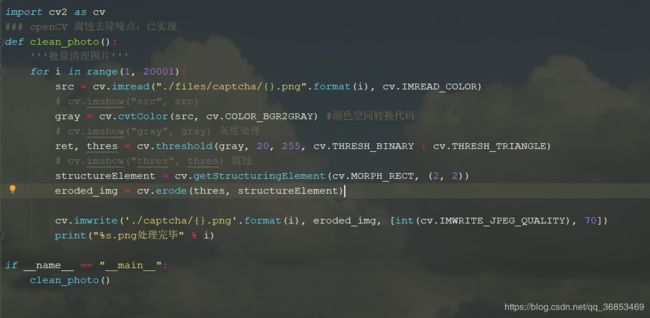
二值化和灰度化后就使噪点显得很明显了,因为不是很懂图像处理这块,还专门花了点时间去学了下OpenCV, 虽然最终还是请教了下做图像处理的同学,很感谢他给予的帮助。
处理出后的大致效果如图

去除了背景干扰,每个字的大小和轮廓都是差不多的,所以觉得用深度学习算法识别正确率应该会大大提高。
图像处理整体代码:
2.3 构建目标值
有了图片,那么就需要建立图片与图片汉字(目标值)对应关系,本来打算借助百度智能云识别的,但是不管是原图,还是处理后的图片都是几乎识别不出来的,最后无奈,还是选择了打码平台,构建了labels.csv,如图:

2.4 读取图片
def readPic():
path = r"./captcha"
files_list = glob.glob(path+"/*.png")
#构造队列
file_queue = tf.train.string_input_producer(files_list)
reader = tf.WholeFileReader()
key,value = reader.read(file_queue)
image_decoded = tf.image.decode_jpeg(value)
image_resized = tf.image.resize(image_decoded,[20,100])
#更新静态形状
image_resized.set_shape([20,100,1])
image_cast = tf.cast(image_resized,tf.float32)
#批处理
filename_batch,image_batch = tf.train.batch([key,image_cast],batch_size=50,num_threads=2,capacity=50)
return filename_batch,image_batch
2.5 建立文件名与特征值映射
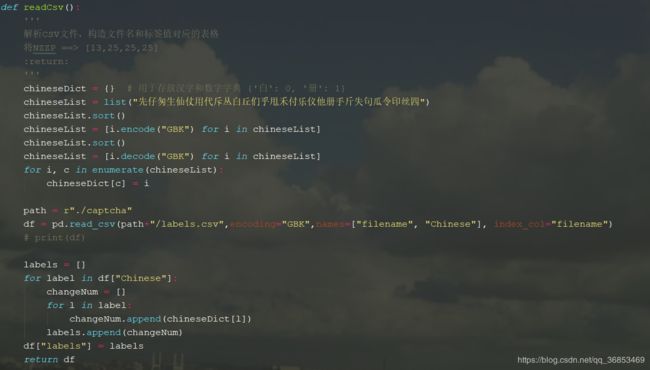
2.6 再次建立此次读取 文件名 与 特征值 之间的联系
def filename2label(filenames,df):
'''
将filename 和 标签值 对应
:param filenames: 文件名,格式为 b' 二进制格式
:param df:DataFrame 字母 和 对应的初步目标值构成
:return: labels ndarray
'''
labels = []
# print(df)
for filename in filenames:
name = re.findall(r'(\d+)\.png',str(filename))
if name:
label = df.loc[int(name[0]),"labels"]
labels.append(label)
return np.array(labels)
2.7 构建卷积神经网络,获取y_predict
2.8 构造损失函数
loss_list = tf.nn.sigmoid_cross_entropy_with_logits(labels=y_true, logits=y_predict)
loss = tf.reduce_mean(loss_list)
2.9 优化损失
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
2.10 计算准确率
equal_list = tf.reduce_all(
tf.equal(tf.argmax(tf.reshape(y_predict, shape=[-1, 4, 30]), axis=2),
tf.argmax(tf.reshape(y_true, shape=[-1, 4, 30]), axis=2)), axis=1)#按行,1axis=1或者-1
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
2.11 模型训练与保存
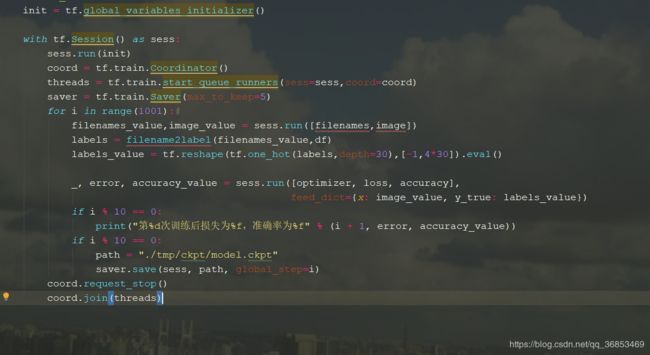
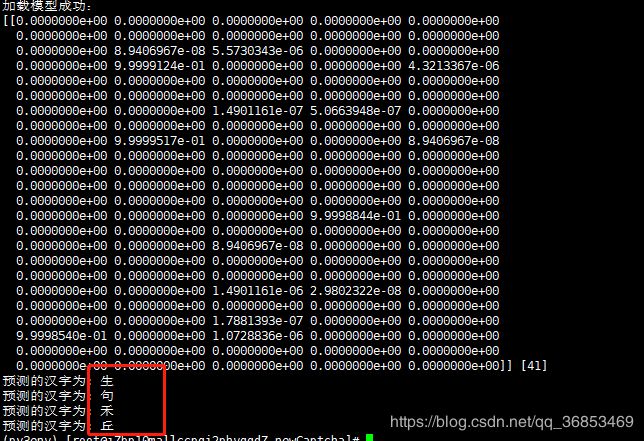
3 预测
随机选择一张验证码图片:

处理后的:
预测结果:
文章很多语言及文章排版格式参考自机器之心的中文项目:快速识别验证码,CNN也能为爬虫保驾护航