关于RetinaNet目标检测算法的理解
算法介绍
RetinaNet目标检测算法是和YOLOv3算法同时期的,RetinaNet算法的准确率要比YOLOv3要高很多,当时速度慢很多。我记得YOLOv3作者的还在他那篇论文中提过它,不得了不得了,YOLO大佬可是惜字如金的!
言归正传,
RetinaNet网络其实就是ResNet+FPN+FCN网络的组合,损失函数为Focal loss
也是one-stage的目标检测算法,最大的贡献就是解决了前景背景种类不均衡问题,让one-stage算法的精度也能达到two-stage的水平。
下面是性能图:
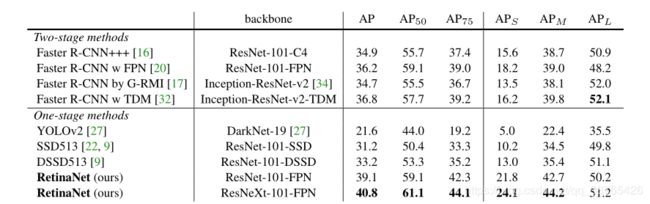
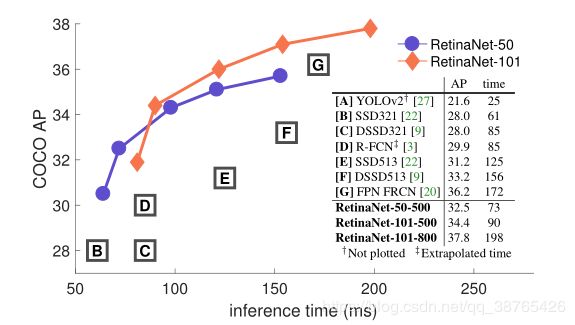
在准确率方面基本吊打所有当时最先进的算法。
论文一开始就提出来一个问题?为什么two-stage算法(例如faster-rcnn)的准确率一直比one-stage算法高呢?
作者认为是前景和背景种类不均衡问题(foreground-background class imbalance)造成的。(例如SSD算法对每张图处理的时候会产生 1 0 4 10^4 104- 1 0 5 10^5 105个候选框,而每张图只有少量位置包含目标,也就是大部分候选框都是背景。)
为了解决这个问题,作者重塑了标准的交叉熵损失函数,以减少对容易分类例子的损失。由此提出来一种新的损失函数Focal Loss,这个损失函数的出现就是为了解决在训练过程中一些稀疏难以区分的样本,可能会被大量容易区分的消极样本压倒的问题。
(例如,一堆数据中有10000个负样本和1个正样本,在训练过程中这个正样本就可以被庞大的负样本压倒,被当成噪声处理。)
在faster-rcnn算法中,IOU大于0.7的 anchor会被归类为正样本,而IOU低于0.3的为负样本,正负样本的比例为1:3,所以避免了上述情况。
对于one-stage算法是直接用滑动窗口密集取样并一次完成位置与种类的回归,所以并不能人为的控制正负样本的比例。
下面是交叉熵函数CE以及改进的focal loss函数FL:
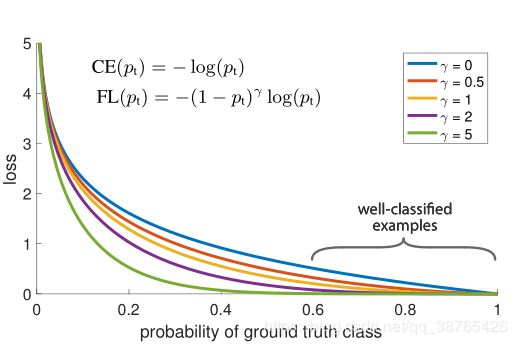
先聊一下交叉熵损失函数
交叉熵函数是信息论中的一个重要概率,用来度量两个概率分布之间的差异性。
信息量:
香农:“信息是用来消除不确定的东西”
信息量的大小是用来消除不确定的程度。例如,太阳从东边升起,这句话的信息量就为0,因为并没有不确定性。
信息量的大小与信息发生的概率成反比。
设某件事情发生的概率为P(x),则信息量的公式为:
I ( x ) = − l o g ( P ( x ) ) I(x)=-log(P(x)) I(x)=−log(P(x))
信息熵:
信息熵就是信息量的期望
H ( X ) = − ∑ i = 1 n p ( x i ) l o g ( p ( x i ) ) ( X = x 1 , x 2 , x 3... , x n ) H(X)=− ∑^n_{i=1}p(x_i)log(p(x_i)) (X=x 1 ,x 2,x 3...,x n ) H(X)=−i=1∑np(xi)log(p(xi))(X=x1,x2,x3...,xn)
相对熵(KL散度):
对于同一个随机变量X有两个单独的概率分布为 P ( x ) P(x) P(x), Q ( x ) Q(x) Q(x),则我们可以用KL散度来衡量这两个分布之间的差异。
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) / q ( x i ) ) D_{KL}(p||q)=∑^n_{i=1}p(x_i)log(p(x_i)/q(x_i)) DKL(p∣∣q)=i=1∑np(xi)log(p(xi)/q(xi))
KL散度越小,表示 P ( x ) P(x) P(x)与 Q ( x ) Q(x) Q(x)的分布更加接近。
交叉熵:
我们把KL散度公式拆开
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) / q ( x i ) ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) ) − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) = − H ( p ( x ) ) + [ ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) ] D_{KL}(p||q)=∑^n_{i=1}p(x_i)log(p(x_i)/q(x_i)) \\ =∑^n_{i=1}p(x_i)log(p(x_i))-∑^n_{i=1}p(x_i)log(q(x_i)) \\ =-H(p(x))+[∑^n_{i=1}p(x_i)log(q(x_i)) ] DKL(p∣∣q)=i=1∑np(xi)log(p(xi)/q(xi))=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))=−H(p(x))+[i=1∑np(xi)log(q(xi))]
H ( p ( x ) ) H(p(x)) H(p(x))表示信息熵,后面的就是交叉熵。
所以KL散度=交叉熵-信息熵
交叉熵(Cross entropy)公式表示为
C E ( p , q ) = − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) CE(p,q)=-∑^n_{i=1}p(x_i)log(q(x_i)) CE(p,q)=−i=1∑np(xi)log(q(xi))
在机器学习训练网络时,输入时数据和标签是确定的,那么真实的概率分布也就确定下来了,所以信息熵是个常量。由于KL散度表示真实值 P ( x ) P(x) P(x)与预测值 Q ( x ) Q(x) Q(x)之间的差异,表示的值越小越好,所以需要最小KL散度,而交叉熵就相当于KL散度加个常量(信息熵),公式比KL散度更好计算,所以机器学习一般用交叉熵来代替KL散度作为损失函数。
交叉熵在处理二分类问题上,因为二分类问题x的取值只有0,1即假和真
代入公式 C E ( p , q ) = − p ( x 1 = 0 ) l o g ( q ( x 1 = 0 ) ) − p ( x 2 = 1 ) l o g ( q ( x 2 = 1 ) ) = − p ( 0 ) l o g ( q ( 0 ) ) − p ( 1 ) l o g ( q ( 1 ) ) CE(p,q)=-p(x_1=0)log(q(x_1=0))-p(x_2=1)log(q(x_2=1))\\ =-p(0)log(q( 0))-p(1)log(q(1)) CE(p,q)=−p(x1=0)log(q(x1=0))−p(x2=1)log(q(x2=1))=−p(0)log(q(0))−p(1)log(q(1))
对于真实值 P ( x ) P(x) P(x)而言, P ( 0 ) = y , P ( 1 ) = 1 − y P(0)=y,P(1)=1-y P(0)=y,P(1)=1−y
所以 C E ( p , q ) = − y l o g ( q ) − ( 1 − y ) l o g ( 1 − q ) CE(p,q)=-ylog(q)-(1-y)log(1-q) CE(p,q)=−ylog(q)−(1−y)log(1−q)
我是用的 q q q代表预测值,而作者是用 p p p,所以把符号改一下就是下面的表达式。
(以下公式来至于原论文,我想保持原论文公式一致)
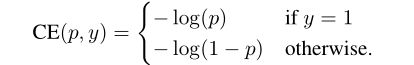
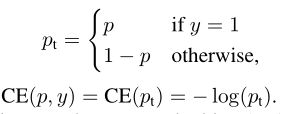
以上这就是二分类标准的交叉熵的推导过程。
作者为解决上文中前景和背景种类不均衡问题,提出了在标准的交叉熵前乘 ( 1 − p t ) λ (1-p_t)^\lambda (1−pt)λ
当 λ \lambda λ>0时,可以减少容易区分样本的损失值,更集中于难以区分样本的损失。
原理其实很简单,把 ( 1 − p t ) λ (1-p_t)^\lambda (1−pt)λ看成 α \alpha α。因为存在大量的容易区分的负样本,那我们在训练过程中用 α \alpha α进行均衡,对于容易区分的负样本, α \alpha α的值很小,损失就很小,而集中于那些难以区分的样本。
结构分析
说了这么久的损失函数,我们来聊聊主干网络
主干网络是由一个主网络和两个特定子网络构成,第一个子网络是对目标进行分类,而第二个子网络是对bounding box进行回归。

RetinaNet网络其实就是ResNet+FPN+FCN。
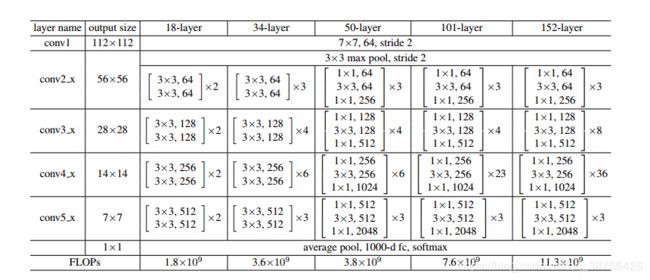
对于ResNet(残差网络),我在我写的YOLOv3中详细介绍了,在这里就省略了,有兴趣的话可以看一下我的YOLOv3)
文中一共采取了两种残差网络ResNet-50和ResNet-101。
取得的效果如下图:
我们就直接介绍FPN网络:一种多尺度预测网络。
为什么要多尺度预测呢?
最开始用神经网络进行目标检测时用的就是单特征图预测(例如FasterRcnn,YOLO),后来发现单特征图预测并不好,因为是用卷积神经网络进行特征提取时,随着卷积层数的增加,特征水平虽然会也来越高,特征图也会越来越小,但是语义信息会越来越少,提取的特征往往倾向于整体特征,而忽略了许多细节特征,表现更高层次的语义信息。(其实你可以把卷积神经网络训练当做主成分提取过程,越往后提取,主成分的作用越明显,而相关的细节会被忽略)
因此如果不进行多尺度预测,会把前面的细节特征忽略,从而导致对小物体预测的不足。
下面是常见的四种预测模式:
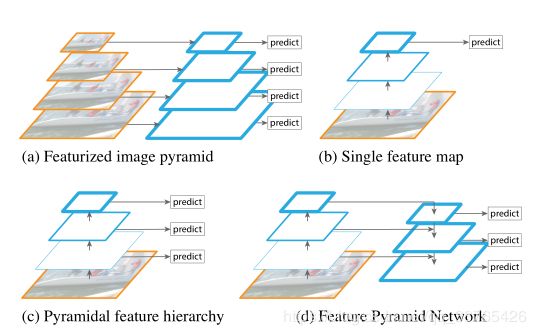
(a)这种多尺度我也是第一次见,图像金字塔,原理就是把图片先进行缩小,缩小多次,然后把每张缩小的图片单独拿出来进行识别。图像金字塔的优点是可以产生多尺度的特征,而且每个层次的语义都很强,包括高分辨率层。对于提高准确率肯定是有作用的,不过就是太慢太慢了,而且训练时数据量很大很大。
(b)就是最传统的检测方式,在多尺度检测方法出来之前都是这一种。
(c)在FPN网络出来之前,基本多尺度预测都是用的这一种特征金字塔。虽然这种结果也具有固定的多尺度金字塔结果,产生了不同空间分辨率的特征图,但是由于深度不同,导致了较大的语义差异,靠前的高分辨率特征图的低水平语义特征会损坏目标识别的表征能力。在特征提取过程中靠后特征图会越来越小,那么导致高水平语义信息也会越来越少。(SSD算法就是采取了这种模式,为了避免上述情况,它放弃了靠前的高分辨率特征图,而是从靠后的特征图中构建金字塔)
(d)相比于前三者,FPN网络拥有更高的准确率。
FPN出现的目的就是为了利用卷积神经网络特性构建所有尺度上都具有强大语义的特征金字塔。为了实现这一目标,作者通过一个个横向连接,将低分辨率、语义强的特征图和高分辨率、语义弱的特征图连接了起来。结果形成了所有层次都具有丰富语义的特征金字塔。它可以取代非饱和图像金字塔而不牺牲表征能力、速度及内存。
下面我还是补充一下FPN网络是如何实现的吧!

卷积网络一般包含多个卷积层,每经过一定的卷积层会通过降采样把图片一步步缩小(例如VGG16),再自上而下,通过升采样把图片一步步放大,然后将分辨率相同的图像用短连接连接起来,从不同维度进行预测。
聊完FPN网络接下来是FCN网络
FCN网络大有来头,全称叫Fully Convolutional Networks for Semantic Segmentation,语义分割开山之作,同样适用于目标检测。
哈哈,开玩笑的啦
我一开始也以为是这个,后来找到原论文发现FCN就是Fully Convolutional Networks的简写。作者从每个FPN网络后面添加两条FCN网络,第一条FCN网络由4个3x3xC的卷积层组成,激活函数为ReLU。(C表示输入特征图的通道数)再紧跟着1个3x3xKA,激活函数为sigmoid,用来预测每个位置的种类。(A为anchors数量,K为种类)
第二条FCN网络和上一条类似,唯一不同的是输出是4A,也就是每个anchor输出4个位置偏移量。
至于为什么要用两条网络?作者说这样可以减少参数,实验结果表明效果都是一样的。
算法细节补充
anchor:采取了与RCNN类似的锚点框,在不同的金字塔水平上其面积从 3 2 2 32^2 322到 51 2 2 512^2 5122,三个长宽比为{1:2, 1:1, 2:1}。如果锚点框的IOU大于阈值0.5,那么将把这个锚点框分配给这个ground-truth。如果在[0,0.4],那么归类为背景。一个锚点框只能匹配一个目标。如果一个锚点框没有被分配,那它的IOU可能处于[0.4,0.5]。
写了差不多两天,写的时候断断续续的,可能还有一些细节没有写上去。如果有什么错误或者不妥的地方,帮忙指正一下!