Python爬虫实现12306火车票查询
昨天早上,突发奇想想要给基友弄一个火车票查询工具,顺便熟悉一下html、json、js格式,为之后制作微信小程序做准备,于是便开始了爬虫的道路。
12306网站想要爬跟之前爬静态网页并不一样,首先由于是一个查询工具,必须要先把网页设置为查询页,才能够爬取网页的信息
打开12306网站 查询北京到上海的火车票
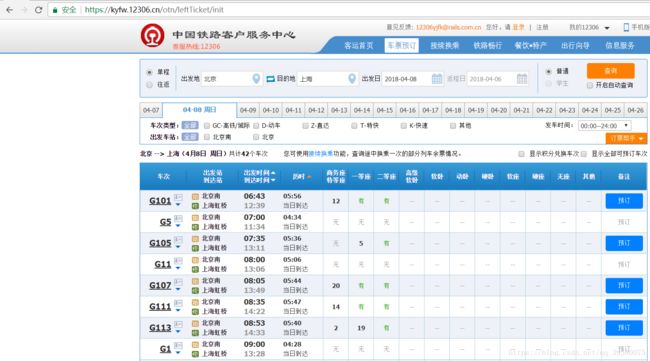 看起来网页地址并没有任何变化
看起来网页地址并没有任何变化
这个时候就需要用到浏览器的一些工具,这里使用的是chrome浏览器
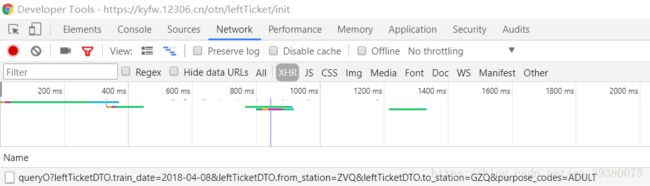
打开工具查看到XHR请求处出现了日期、出发站、到达站的信息
此时便可以通过复制粘贴这段网址来获取相应的火车信息
但是会发现我们输入的站点为中文,而网页代码是站点的英文编号,那么如何进行站点的中英文切换呢
这个时候就需要去查询中英文对应的“字典”
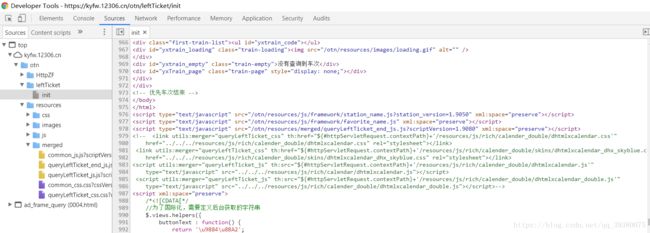
在这里的976行找到了station_version=1.9050,这是火车站版本号,复制这个后缀,在12306网址后加上,便可以到达这个页面

已经可以看到火车站中文名与英文编号,此时就要使用requests库来提取网页信息
关于requests库:https://www.cnblogs.com/zhaof/p/6915127.html
对于信息的提取可以看到我们要提取的信息是大写英文字母以及中文,因此可以使用正则表达式(Re)
关于Re库:https://blog.csdn.net/i_chaoren/article/details/62264414
除此以外此网站会有如此提示:
requests\packages\urllib3\connectionpool.py:843: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
因此加入
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)这段代码来禁止出现警告提示
这就是提取火车站中英文对照的完整代码
import requests
import re
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9050'
r = requests.get(url,verify=False) #提取网页信息,不判断证书
pattern = u'([\u4e00-\u9fa5]+)\|([A-Z]+)' #正则表达式提取中文以及大写英文字母
result = re.findall(pattern,r.text) #进行所需要的信息的提取
station = dict(result) #把所获信息设置为一一对应(有点像是c++里的map)
print(station.keys()) #随后打印
print(station.values())随后将输出的数据保存到另一个文件(stations1.py)中
这个时候就可以使用这个文件来进行中文站名和英文代码的切换了
由于涉及到中文,在使用这个station1.py文件时有可能报以下错误:
![]()
此时只需要在文件的开头加入
# coding=gbk即可
除此以外定义两函数进行中文名字和英文代码的对应获取

在这个过程中还有其他很多奇怪的错误,时间都用来debug就对了
![]()
chrome也开满了各种查错误进行debug的网页
随后使用一个PrettyTable库来进行信息对齐表格美化(这个库要注意大小写)
关于PrettyTable库:https://blog.csdn.net/codeway3d/article/details/52798804
随后要在查询到的网址中找到不同火车票的信息

这真是找得生无可恋...
找到以后进行信息的对照,一个一个对应网页上的坐席进行对照,确定每一个对应的是什么坐席
pt = PrettyTable()
pt._set_field_names('车次 车站 时间 历时 商务座 一等座 二等座 动卧 软卧 硬卧 硬座 无座'.split())
for raw_train in raw_trains:
data_list = raw_train.split('|')
train_no = data_list[3]
initial = train_no[0].lower()
if not options or initial in options:
from_station_code = data_list[6]
to_station_code = data_list[7]
from_station_name = ''
to_station_name = ''
start_time = data_list[8]
arrive_time = data_list[9]
time_duration = data_list[10]
business_seat = data_list[32] or '--'
first_class_seat = data_list[31] or '--'
second_class_seat = data_list[30] or '--'
pneumatic_sleep = data_list[33] or '--'
soft_sleep = data_list[23] or '--'
hard_sleep = data_list[28] or '--'
hard_seat = data_list[29] or '--'
no_seat = data_list[26] or '--'
pt.add_row([train_no,
'\n'.join([stations1.get_name(from_station_code), stations1.get_name(to_station_code)]),
'\n'.join([start_time, arrive_time]),
time_duration,
business_seat,
first_class_seat,
second_class_seat,
pneumatic_sleep,
soft_sleep,
hard_sleep,
hard_seat,
no_seat
])关键的PrettyTable模块
以下是所有代码:
import requests
import stations1
from prettytable import PrettyTable
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def cli():
str = input("请输入出发站: ");
str1 = input("请输入到达站: ");
date = input("请输入出发日期(格式xxxx-xx-xx): ");
options = input("请输入列车类型(格式g、d、t、k、z): ");
from_station = stations1.get_telecode(str)
to_station = stations1.get_telecode(str1)
url = ('https://kyfw.12306.cn/otn/leftTicket/queryO?'
'leftTicketDTO.train_date={}&'
'leftTicketDTO.from_station={}&'
'leftTicketDTO.to_station={}&'
'purpose_codes=ADULT').format(date,from_station,to_station)
headers = {
"Cookie": "自己先在浏览器输入一个url,看cookie拉下来用"
}
r = requests.get(url,headers=headers,verify=False)
raw_trains = r.json()['data']['result']
pt = PrettyTable()
pt._set_field_names('车次 车站 时间 历时 商务座 一等座 二等座 动卧 软卧 硬卧 硬座 无座'.split())
for raw_train in raw_trains:
data_list = raw_train.split('|')
train_no = data_list[3]
initial = train_no[0].lower()
if not options or initial in options:
from_station_code = data_list[6]
to_station_code = data_list[7]
from_station_name = ''
to_station_name = ''
start_time = data_list[8]
arrive_time = data_list[9]
time_duration = data_list[10]
business_seat = data_list[32] or '--'
first_class_seat = data_list[31] or '--'
second_class_seat = data_list[30] or '--'
pneumatic_sleep = data_list[33] or '--'
soft_sleep = data_list[23] or '--'
hard_sleep = data_list[28] or '--'
hard_seat = data_list[29] or '--'
no_seat = data_list[26] or '--'
pt.add_row([train_no,
'\n'.join([stations1.get_name(from_station_code), stations1.get_name(to_station_code)]),
'\n'.join([start_time, arrive_time]),
time_duration,
business_seat,
first_class_seat,
second_class_seat,
pneumatic_sleep,
soft_sleep,
hard_sleep,
hard_seat,
no_seat
])
print(pt)
if __name__ == '__main__':
cli()其中colorama库执行不成功,不知道原因是什么,会出来一些乱码
执行结果(由于打算端午节自己去黄山溜溜,于是查的是到黄山的火车)
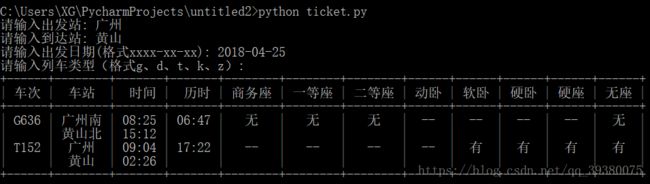
加上中午出去吃饭以及晚上回乡下吃饭的时间,制作用时10h
--------------------------------------------------分割线--------------------------------------------------------
2020.04.09测试截图
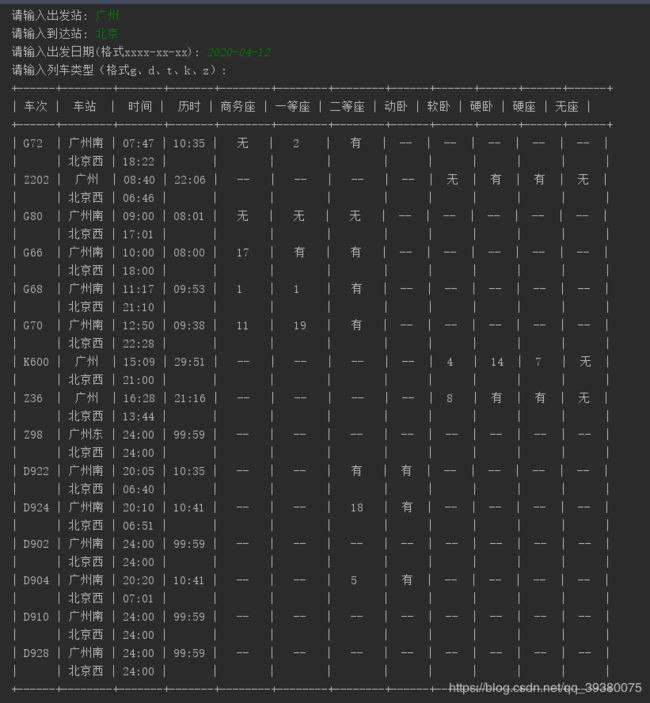
制作参考文章:
Python爬取12306实现火车票查询——https://blog.csdn.net/tigaoban/article/details/78558417?locationNum=4&fps=1
从零开始写Python爬虫 --- 爬虫应用: 12306火车票信息查询——https://zhuanlan.zhihu.com/p/27969976
制作参考视频:
【公开课】实验楼带你学爬虫——Python实现火车票爬虫工具——https://www.bilibili.com/video/av12380578/