【Python】记录生产编程小tips(字符串处理、列表删除、字典、csv、excel操作)持续更新
文章目录
- 一.for循环删除列表元素
-
- 1.删除list元素方法
- 2.直接删除往往结果与期望不一致
- 3.循环删除元素的正确方法:
-
- 方法1:while循环+i减
- 方法2:使用copy
- 方法3:倒叙遍历
- 二.字符串处理库
- 三.dict字典
-
- 1.dict运用
- 2.循环删除dict的键值对
-
- 1. 使用 for 循环和 del 语句
- 2. 使用字典推导式(创建新字典)
- 3. 使用 popitem() 方法(在 Python 3.7+ 中有序)
- 4. 使用 items() 和 while 循环(不常用)
- 四.csv操作
- 五.excel操作
-
- 1.读xls——xlrd
- 2.写xls——xlwt
- 3.使用 openpyxl 来读写xlsx
- 4.使用Pandas库来处理excel数据
- 六.mysql操作
- 七.http请求操作
- 八.判断不同操作系统类型
- 九.获取指定目录下的所有文件名
- 十.判断文件是否存在
- 十一.在Python中打开一个桌面程序(或任何外部程序)
-
- 1.subprocess模块通常是Python中打开桌面程序的首选方法
- 2. 使用os.system()(不推荐)
- 3.使用webbrowser模块(适用于打开网页或特定类型的文件)
- 遍历字典(Dictionary)
-
- 1. 遍历字典的键(Keys)
- 2. 遍历字典的值(Values)
- 3. 遍历字典的键值对(Items)
- 4. 遍历字典时保持顺序(Python 3.7+)
- 注意事项
一.for循环删除列表元素
1.删除list元素方法
-
pop方法:是删除第一个或者是指定删除元素的下标。返回被删除的值。
list.pop(i) -
remove方法:直接指定要删除的元素值,删除首个匹配的值。
list.remove(item)list2=[1,2,3,4,5,6,7,5] list2.remove(5) print(list2) -
结果:
[1, 2, 3, 4, 6, 7, 5]- del 元素方法
-
可以删除指定下标的元素,删除指定下标范围内的多个元素,删除整个对象
list2=[1,2,3,4,5,6,7,5] del list2[1] print(list2) #[1, 3, 4, 5, 6, 7, 5] list2=[1,2,3,4,5,6,7,5] del list2[2:4] #删除3,4 print(list2) #[1, 2, 5, 6, 7, 5] list2=[1,2,3,4,5,6,7,5] del list2 print(list2) #NameError: name 'list2' is not defined
2.直接删除往往结果与期望不一致
python 使用for循环删除列表元素,容易出现结果与期望不一致问题。
- 例如代码:要删除列表中的3或者4,但是最后结果是4未删除掉。
list = [1, 2, 3, 4, 5]
print(list)
for ele in list:
if ele == 3 or ele == 4:
list.remove(ele)
else:
print(ele)
print(list)
结果:
[1, 2, 3, 4, 5]
1
2
5
[1, 2, 4, 5]
- 因为删除3后,3之后的[4,5]前移,4占了3原来的位置。下次循环是取3之后的数,即现在4之后的数(因为4去3的位置顶替了),也就是继续去判断5了。
3.循环删除元素的正确方法:
方法1:while循环+i减
- 使用while循环时刻监测数组长度,控制数组索引i,当i 遇到删除元素时候就往回移动一个元素位置,即减1
list=[1,2, 3, 4, 5]
i=0
#不能使用for i in range(0,len(num_list))会导致最后index溢出
while i < len(list):
if list[i] == 3 or list[i]==4:
list.pop(i)
i-=1
else:
print("num_list[{}]={}".format(i,list[i]))
i+=1
print(list)
结果:
num_list[0]=1
num_list[1]=2
num_list[2]=5
[1, 2, 5]
- 注意:while循环不可以换成for,for i in range(0,len(num_list))会导致最后索引i溢出
方法2:使用copy
- 切片是生成数组的copy方式之一
list = [1, 2, 3, 4, 5]
# num_list[:]是对num_list的拷贝
for item in list[:]:
if item == 3 or item==4:
list.remove(item)
else:
print(item)
print(list)
结果:
1
2
5
[1, 2, 5]
方法3:倒叙遍历
倒叙遍历,删除某个元素后,后面元素向前顶替位置,后面的元素是已经check过的,所以不会导致元素遗漏问题。
list = [1, 2, 3, 4, 5]
for i in range(len(list)-1, -1, -1):
if list[i] == 3 or list[i] == 4:
list.pop(i)
else:
print("num_list[{}]={}".format(i,list[i]))
print(list)
结果:
num_list[4]=5
num_list[1]=2
num_list[0]=1
[1, 2, 5]
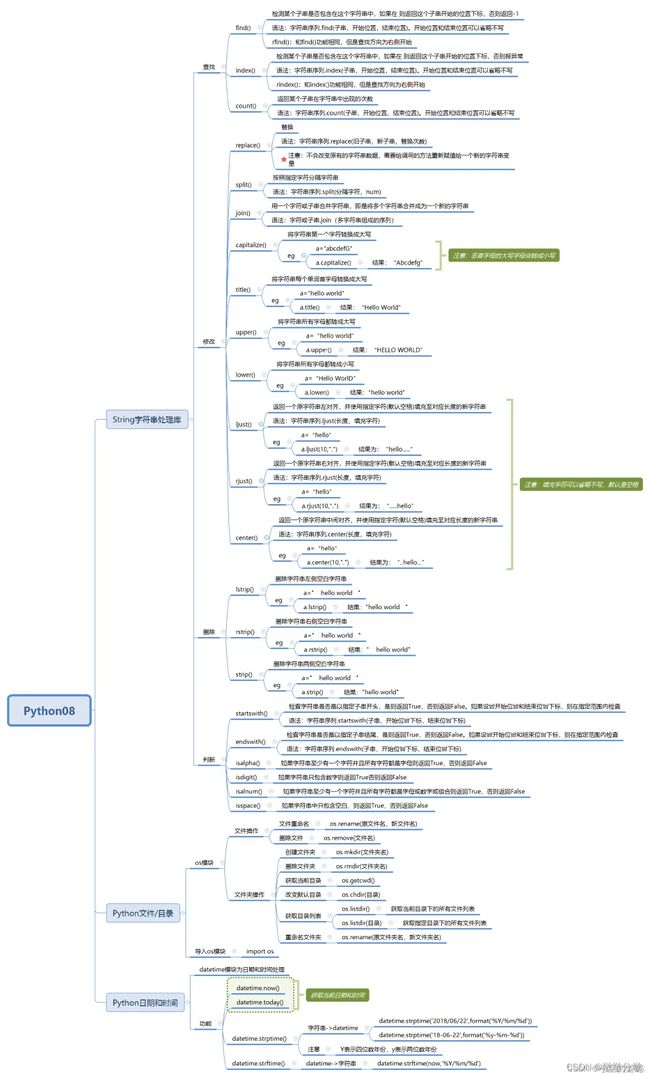
二.字符串处理库
三.dict字典
1.dict运用
创建字典
# 使用花括号创建字典
my_dict = {'a': 1, 'b': 2, 'c': 3}
# 使用 dict() 函数创建字典
another_dict = dict(a=1, b=2, c=3)
# 从键值对列表创建字典
list_of_tuples = [('a', 1), ('b', 2), ('c', 3)]
from_list = dict(list_of_tuples)
访问字典元素
# 通过键访问值
value = my_dict['a'] # 输出: 1
# 使用 get() 方法访问值,如果键不存在则返回 None 或指定的默认值
value_or_default = my_dict.get('d', 'default_value') # 输出: 'default_value'
修改字典元素
# 通过键修改值
my_dict['a'] = 10
# 添加新的键值对
my_dict['d'] = 4
删除字典元素
# 使用 del 语句删除键值对
del my_dict['b']
# 使用 pop() 方法删除键值对并获取其值
value = my_dict.pop('c') # 输出: 3,my_dict 中不再包含键 'c'
# 使用 popitem() 方法删除并返回字典中的最后一个键值对(在 Python 3.7+ 中按插入顺序)
key, value = my_dict.popitem() # 输出: 可能是 ('d', 4),取决于字典的当前状态
遍历字典
# 遍历键
for key in my_dict:
print(key)
# 遍历值
for value in my_dict.values():
print(value)
# 遍历键值对
for key, value in my_dict.items():
print(key, value)
检查键或值是否存在于字典中
# 检查键是否存在
key_exists = 'a' in my_dict # 输出: True 或 False
# 检查值是否存在(需要遍历)
value_exists = 4 in my_dict.values() # 输出: True 或 False
获取字典的大小
size = len(my_dict) # 输出字典中键值对的数量
字典的合并
# 使用 update() 方法合并两个字典
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
dict1.update(dict2) # dict1 现在变为 {'a': 1, 'b': 3, 'c': 4}
# 使用解包合并两个字典(Python 3.5+)
merged_dict = {**dict1, **dict2} # 注意:如果键重复,则后面的字典的值会覆盖前面的
字典推导式
# 使用字典推导式创建字典
squared_dict = {x: x**2 for x in range(5)} # 输出: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
2.循环删除dict的键值对
1. 使用 for 循环和 del 语句
你可以直接使用 for 循环遍历字典的键,并使用 del 语句来删除满足特定条件的元素。
my_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 删除所有值小于 3 的元素
keys_to_delete = [k for k, v in my_dict.items() if v < 3]
for key in keys_to_delete:
del my_dict[key]
print(my_dict) # 输出: {'c': 3, 'd': 4}
- 收集了要删除的键的列表,然后再进行删除。这是因为直接在遍历过程中修改字典(比如删除当前迭代的键)可能会导致不可预测的行为(比如跳过某些元素或抛出异常)。
2. 使用字典推导式(创建新字典)
虽然这不是“循环删除”的传统意义上的方法,但字典推导式是一种非常 Pythonic 的方式来过滤字典中的元素。
my_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 创建一个只包含值大于或等于 3 的元素的新字典
filtered_dict = {k: v for k, v in my_dict.items() if v >= 3}
#如果你想要修改原始字典,可以将结果重新赋值给原始变量。
print(filtered_dict) # 输出: {'c': 3, 'd': 4}
3. 使用 popitem() 方法(在 Python 3.7+ 中有序)
虽然 popitem() 方法通常用于从字典中移除并返回一个键值对(在 Python 3.7+ 中是按照插入顺序的),但你可以通过某种逻辑来控制调用它的次数和条件,从而实现循环删除的效果。不过,这种方法通常不如前两种方法直观或高效。
my_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 假设你想删除前两个元素(这种方法不常用,仅作示例)
for _ in range(2):
my_dict.popitem()
print(my_dict) # 输出: {'c': 3, 'd': 4}(注意顺序)
#请注意,popitem() 方法在 Python 3.6 及更早版本中是无序的,因此不建议在这些版本中使用它来控制删除顺序。
4. 使用 items() 和 while 循环(不常用)
虽然不常见,但你也可以结合 items() 方法和 while 循环来删除元素。这种方法通常不如使用 for 循环和 del 语句或字典推导式来得直接或高效。
my_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
keys = list(my_dict.keys()) # 创建键的副本以避免在迭代时修改字典
# 使用 while 循环和 del 语句删除元素
i = 0
while i < len(keys):
if my_dict[keys[i]] < 3:
del my_dict[keys[i]]
# 由于删除了元素,我们需要调整索引或重新遍历
# 这里我们选择简单地重新遍历剩余元素(效率较低)
keys = list(my_dict.keys()) # 更新键列表
i = 0 # 重置索引
else:
i += 1 # 继续到下一个元素
print(my_dict) # 输出: {'c': 3, 'd': 4}(假设没有错误)
由于上述 while 循环方法效率极低且容易出错,因此通常不建议使用。相反,你应该优先考虑使用 for 循环和 del 语句或字典推导式来删除字典中的元素。
四.csv操作
读取CSV文件,打开文件并创建一个csv.reader对象来读取文件的内容
import csv
with open(r'C:\Users\87772\Desktop\asr_text_20240223.csv', 'r') as file:
# 创建CSV读取器
reader = csv.reader(file)
# 遍历每一行
for row in reader:
print(row)
写入CSV文件,需要创建一个csv.writer对象,并将要写入的数据传递给它。
import csv
data = [
['Name', 'Age', 'Country'],
['John', 25, 'USA'],
['Alice', 30, 'Canada'],
['Bob', 35, 'UK']
]
#指定了参数newline='',以防止在写入文件时出现空行
with open(r'C:\Users\87772\Desktop\asr_text_20240223.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)
- 在Python 2中,open函数并不支持
newline参数
五.excel操作
1.读xls——xlrd
# 导入xlrd库,用于读取Excel文件
import xlrd
#xlrd2.0.0开始,xlrd库默认只支持.xls格式,不支持.xlsx格式。
book = xlrd.open_workbook('test.xls')#获取工作薄对象
names = book.sheet_names() # 获取所有工作表名称,结果为列表
mySheets = book.sheets() # 获取工作表list
sheet = mySheets[0] #通过索引获取工作表
sheet = book.sheet_by_index(0) #通过索引获取工作表
sheet = book.sheet_by_name('Sheet1') #通过索引获取工作表
# 获取工作表的行数和列数
nrows = sheet.nrows # 获取行数
ncols = sheet.ncols # 获取列数
# 获取一行和一列的数据
i = 0 #行
j = 0 #列
row = sheet.row_values(i) # 获取指定行的数据,返回List对象
col = sheet.col_values(j) # 获取指定列的数据,返回List对象
# 读取单元格数据
cell = sheet.cell_value(i, j) # 直接获取指定单元格的数据
cell_obj = sheet.cell(i, j) #获取指定单元格对象
cell_value = cell_obj.value # 获取单元格对象的值
示例1:Python读取Excel文件特定数据
import xlrd
# 打开名为'test.xls'的Excel文件
data = xlrd.open_workbook('test.xls')
# 选择第一个工作表
table = data.sheets()[0]
# 获取表的行数
nrows = table.nrows
# 循环逐行输出
for i in range(nrows):
if i == 0: # 跳过第一行
continue
# 打印出每一行的前五列值(注意修正了print函数和row_values方法的调用)
print(table.row_values(i)[:5]) # 取前五列数据,注意修正了括号和切片的使用
示例2:Python读取Excel文件所有数据
import xlrd
# 打开一个xlsx文件
workbook = xlrd.open_workbook('test.xls')
# 抓取所有sheet页的名称
worksheets = workbook.sheet_names()
print('worksheets is %s' % worksheets)
# 如果存在sheet1文件则定位到sheet1
worksheet1 = workbook.sheet_by_name('Sheet1')
# 遍历所有sheet对象
for worksheet_name in worksheets:
worksheet = workbook.sheet_by_name(worksheet_name)
# 遍历sheet1中所有行row
num_rows = worksheet1.nrows
for curr_row in range(num_rows):
row = worksheet1.row_values(curr_row)
print('row %s is %s' % (curr_row, row))
# 遍历sheet1中所有列col
num_cols = worksheet1.ncols
for curr_col in range(num_cols):
col = worksheet1.col_values(curr_col)
print('col %s is %s' % (curr_col, col))
# 遍历sheet1中所有单元格cell
for rown in range(num_rows):
for coln in range(num_cols):
cell = worksheet1.cell_value(rown, coln)
print(cell)
2.写xls——xlwt
xlwt模块只能写xls文件,不能写xlsx文件(写xlsx程序不会报错,但最后文件无法直接打开,会报错)。
import xlwt
# 创建Excel工作簿 encoding:设置编码,默认是ascii,一般设置为utf-8,可支持中文;
myWorkbook = xlwt.Workbook(encoding='utf-8')
# 创建一个工作表,并命名为"New Sheet"
sheet = myWorkbook.add_sheet('New Sheet')
# 定义一个样式对象myStyle,设置字体为"Times New Roman"(注意:这不是中文字体,若需显示中文应更改为中文字体),颜色为红色,加粗,数字格式为带两位小数的格式
myStyle = xlwt.easyxf('font: name Times New Roman, color-index red, bold on', num_format_str='#,##0.00')
# 向单元格写入内
# 写入(1, 1)单元格,内容为2022,应用自定义样式
sheet.write(1, 1, 2022, myStyle)
# 写入(2, 0)单元格,即A3单元格,数值等于1
sheet.write(2, 0, 1)
# 写入(2, 1)单元格,即B3单元格,数值等于1
sheet.write(2, 1, 1)
# 写入(2, 2)单元格,即C3单元格,内容为A3+B3的公式结果,xlwt支持写入公式
sheet.write(2, 2, xlwt.Formula("A3+B3"))
# 保存工作簿到指定路径,注意文件扩展名应为.xls
myWorkbook.save('excelFile.xls')
示例:新建excel文件并写入数据
import xlwt
# 创建workbook和sheet对象
workbook = xlwt.Workbook(encoding='utf-8')
# 向sheet写入数据
sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)
sheet2 = workbook.add_sheet('sheet2', cell_overwrite_ok=True)
# 向sheet页中写入数据
sheet1.write(0, 0, 'Sheet1')
sheet1.write(0, 1, 'Sheet1 Content')
sheet2.write(0, 0, 'Sheet2')
sheet2.write(1, 2, 'Sheet2 Content')
# 保存该Excel文件,有同名文件时直接覆盖
workbook.save('test.xls')
print('创建excel文件完成!')
3.使用 openpyxl 来读写xlsx
openpyxl模块可实现对xlsx文件的读、写和修改 不能处理xls文件。
from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.writer.excel import ExcelWriter
wb = load_workbook(u"output.xlsx") # 加载excel
sheetnames = wb.sheetnames # 获得表单名字
print(sheetnames)
sheet1 = wb.get_sheet_by_name("Sheet1") #根据名字获取工作表
title = sheet1.title # 获取工作表名称
rows = sheet1.max_row # 获取工作表行数
cols = sheet1.max_column # 获取工作表列数
sheet1 = wb[sheetnames[0]] # 获取第一个sheet
print(sheet1.cell(row=3, column=3).value)
sheet1['A1'] = 'grade'
wb.save(u"output_new.xlsx") # 修改元素值并另存为 xlsx
sheet = wb.active # 获取活动表
print(sheet)
print(sheet.dimensions) # 获取表格的尺寸大小
cell = sheet['A1'] # 获取 A1 单元格的数据
print(cell.value) # cell1.value 获取单元格 A1 中的值
print(sheet['a2'].value) # 使用 excel 单元格的表示法,字母不区分大小写 获取第 2 行第 1 列的数据
print(cell.value, cell.row, cell.column, cell.coordinate) # 获取某个格子的行数、列数以及坐标
cells = sheet['A1:A5'] # 使用 sheet ['A1:A5'] 获取 A1 到 A5 的数据
print (cells)
#打印A1到A5的数据
for i in cells:
for j in i:
print(j.value)
# openpyxl读取xlsx文件
book = openpyxl.Workbook(encoding = 'utf-8') # 创建工作簿 如果写入中文为乱码,可添加参数encoding = 'utf-8'
sheet = book.create_sheet('Sheet_name',0) # 创建工作表,0表示创建的工作表在工作簿最前面
sheet.cell(m,n,'content1') # 向单元格写入内容:
#分别表示第m行、第n列前面插入行、列
sheet.insert_rows(m) 和 sheet.insert_cols(n)
#分别表示删除第m行、第n列
sheet.delete_rows(m) 和 sheet.delete_cols(n)
#修改单元格内容:
sheet.cell(m,n) = '内容1'或者sheet['B3'] = '内容2'
#在最后追加行:
sheet.append(可迭代对象)
# 保存工作簿,默认保存在py文件相同路径下,如果该路径下有相同文件,会被新创建的文件覆盖。
book.save('excelFile')
4.使用Pandas库来处理excel数据
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
import pandas as pd
mydata = {
'sites': ["SZ", "BJ", "SS"],
'number': [1, 2, 3]
}
myvar = pd.DataFrame(mydata)
print(myvar)
"""
sites number
0 SZ 1
1 BJ 2
2 SS 3
"""
import pandas as pd
file_path = r'example.xlsx'
df = pd.read_excel(file_path, sheet_name = "test") # sheet_name不指定时默认返回全表数据
print(df) # 打印表数据,如果数据太多,会略去中间部分
print(df.head()) # 打印头部数据,仅查看数据示例时常用
print(df.columns) # 打印列标题
print(df.index) # 打印行
print(df["ave"]) # 打印指定列
# 描述数据
print(df.describe())
写excel
from pandas import DataFrame
# 创建一个字典,包含三列数据:'name'(姓名)、'age'(年龄)和'gender'(性别)
data = {
'name': ['zs', 'ls', 'ww'],
'age': [11, 12, 13],
'gender': ['man', 'man', 'woman']
}
# 使用这个字典创建一个DataFrame对象
df = DataFrame(data)
# 将这个DataFrame对象保存到一个名为'new.xlsx'的Excel文件中
df.to_excel('new.xlsx')
修改excel–以修改原Excel文件中gender列数据为例,把girl修改为female,boy修改为male:
# 导入pandas库,并给它一个别名pd
import pandas as pd
# 从pandas库中再次导入DataFrame类(这一步其实是多余的,因为已经通过pd别名可以访问DataFrame)
from pandas import DataFrame
# 定义Excel文件的路径
file_path = r'new.xlsx'
# 使用pandas的read_excel函数读取Excel文件,并将其内容存储在DataFrame对象df中
df = pd.read_excel(file_path)
# 将性别为'woman'的行中的性别值更改为'girl'
df.loc[df['gender'] == 'woman', 'gender'] = 'girl'
# 将性别为'man'的行中的性别值更改为'boy'
df.loc[df['gender'] == 'man', 'gender'] = 'boy'
# 打印修改后的DataFrame
print(df)
# 新增一行,并设置该行的每个单元格值
row1 = '41' # 第一个值(例如ID)
row2 = '42' # 第二个值(例如姓名)
row3 = '43' # 第三个值(例如年龄)
row4 = '44' # 第四个值(例如性别,但这里可能会与现有列不匹配)
row_index = 4 # 定义新行的索引位置
# 注意:这里尝试添加新行时,提供的值列表必须与DataFrame的列完全匹配,否则会引发错误
df.loc[row_index] = [row1, row2, row3, row4]
# 打印添加新行后的DataFrame
print(df)
# 新增一列,列名为'sex'
column_name = "sex"
df[column_name] = None # 为新列'sex'设置所有行的值为None
# 将修改后的DataFrame保存回Excel文件,覆盖原有内容
# 注意:这里的DataFrame(df)是多余的,因为df已经是一个DataFrame对象,直接调用to_excel方法即可
df.to_excel(file_path, sheet_name='Sheet1', index=False, header=True)
示例1:读取excel数据
# 导入pandas模块
import pandas as pd
# 直接默认读取到这个Excel的第一个表单
sheet = pd.read_excel('test.xlsx')
# 默认读取前5行数据
data=sheet.head()
print("获取到所有的值:\n{0}".format(data)) # 格式化输出
# 也可以通过指定表单名来读取数据
sheet2=pd.read_excel('test.xlsx',sheet_name='test')
data2=sheet2.head() # 默认读取前5行数据
print("获取到所有的值:\n{0}".format(data2)) # 格式化输出
示例2:操作Excel中的行列
# 导入pandas模块
import pandas as pd
sheet=pd.read_excel('test.xlsx') # 这个会直接默认读取到这个Excel的第一个表单
# 读取制定的某一行数据:
data=sheet.loc[0].values # 0表示第一行 这里读取数据并不包含表头
print("读取指定行的数据:\n{0}".format(data))
# 读取指定的多行:
data2=sheet.loc[[0,1]].values
print("读取指定行的数据:\n{0}".format(data2))
# 获取行号输出:
print("输出行号列表",sheet.index.values)
# 获取列名输出:
print("输出列标题",sheet.columns.values)
六.mysql操作
【Python】从入门到上头—mysql数据库操作模块mysql-connector和PyMySQL应用场景 (15)
七.http请求操作
【Python】从入门到上头—网络请求模块urlib和reuests的应用场景(12)
八.判断不同操作系统类型
- 使用os.name
- os.name字符串会给出你正在使用的操作系统名称的泛化描述。但它并不直接给出操作系统的名称(如"Windows"、“Linux"或"macOS”),而是给出了一些较为通用的标识符,如’posix’(表示类Unix系统,包括Linux和macOS)或’nt’(表示Windows)。
import os
if os.name == 'nt':
print("Windows系统")
elif os.name == 'posix':
print("类Unix系统(如Linux或macOS)")
else:
print("未知系统")
- 使用sys.platform
sys.platform属性给出了更具体的系统信息,可以直接用来判断Windows、Linux或macOS。
import sys
if sys.platform.startswith('win'):
print("Windows系统")
elif sys.platform == "linux" or sys.platform == "linux2":
print("Linux系统")
elif sys.platform == "darwin":
print("macOS系统")
else:
print("未知系统")
九.获取指定目录下的所有文件名
def readFilesName(self, file_folder):
arr = []
# 读取所有文件
for file_name in os.listdir(file_folder):
arr.append(file_name)
return arr
十.判断文件是否存在
if not os.path.exists(directory_name):
os.makedirs(directory_name)
print(f'Directory "{directory_name}" created successfully.')
十一.在Python中打开一个桌面程序(或任何外部程序)
1.subprocess模块通常是Python中打开桌面程序的首选方法
在Python中打开一个桌面程序(或任何外部程序),你可以使用subprocess模块。这个模块允许你启动新的应用程序和进程,连接到它们的输入/输出/错误管道,并获取它们的返回码。
- 以下是一个使用subprocess.run()函数来打开桌面程序(例如记事本Notepad)的例子:
import subprocess
# 调用系统的'notepad'命令来打开记事本
# 注意:这里的'notepad'是Windows的命令,如果你在Linux或Mac上,你需要使用相应的命令(如'gedit'或'open -a TextEdit')
subprocess.run(['notepad'])
# 如果你需要打开特定的文件,可以传递文件路径作为参数
# 例如,打开C盘根目录下的example.txt文件
subprocess.run(['notepad', 'C:\\example.txt'])
# 对于Mac和Linux,打开TextEdit和gedit的示例(请根据你的实际环境调整路径)
# 对于Mac
subprocess.run(['open', '-a', 'TextEdit', '/path/to/your/file.txt'])
# 对于Linux(使用gedit为例)
subprocess.run(['gedit', '/path/to/your/file.txt'])
# 可以通过在终端中使用 open 命令并指定 -a 选项后跟应用程序的 bundle identifier 或直接通过应用程序的名称(如果它位于你的 /Applications 文件夹中,且已添加到你的 PATH 变量中,但这对于大多数应用程序来说并不常见)来打开。
# 使用 open 命令和谷歌浏览器的应用程序名称
subprocess.run(['open', '-a', 'Google Chrome'])
# 如果你想要打开一个新的浏览器窗口(或标签页)并导航到特定的URL,
# 你可以将URL作为 open 命令的最后一个参数
subprocess.run(['open', '-a', 'Google Chrome', 'https://www.example.com'])
- subprocess.run()函数是
Python 3.5及更高版本中引入的。如果你使用的是较旧的Python版本,可能需要使用subprocess.Popen(),它提供了更多的灵活性和控制,但使用起来也更复杂一些。 - subprocess.run()函数返回一个
CompletedProcess实例,它包含了进程的返回码和其他信息。但如果你只是需要简单地启动一个程序,通常不需要关心这些返回值。
2. 使用os.system()(不推荐)
在较旧的Python代码或一些简单脚本中,你可能会看到使用os.system()函数来执行系统命令以打开桌面程序。然而,这种方法通常不推荐用于生产环境,因为它不如subprocess模块灵活和安全。
import os
# 使用os.system()打开记事本(Windows)
os.system("notepad")
# 注意:这种方法会将命令的输出直接打印到Python脚本的输出中,
# 并且它不如subprocess模块那样易于控制和管理。
3.使用webbrowser模块(适用于打开网页或特定类型的文件)
import webbrowser
# 尝试使用默认程序打开文件(如果文件与某个桌面程序关联)
webbrowser.open('C:\\path\\to\\your\\file.txt')
# 注意:这不会直接打开桌面应用程序,而是尝试打开与文件类型相关联的程序。
- webbrowser.open()函数的行为(是在新标签页还是新窗口中打开URL)可能会因用户的浏览器设置和偏好而有所不同。
- webbrowser.open_new()函数通常会在新的浏览器窗口中打开URL,但这也可能受到浏览器设置的影响。
- webbrowser.open_new_tab()函数旨在在新的浏览器选项卡中打开URL,但并非所有浏览器都支持这一行为。在某些情况下,它可能会退回到webbrowser.open_new()的行为。
遍历字典(Dictionary)
在Python中,遍历字典(Dictionary)可以通过几种不同的方式来实现,具体取决于你想要访问字典的键(keys)、值(values)还是键值对(items)。以下是一些常用的遍历字典的方法:
1. 遍历字典的键(Keys)
你可以使用dict.keys()方法获取字典中所有的键,并使用一个循环来遍历它们。
my_dict = {'a': 1, 'b': 2, 'c': 3}
for key in my_dict.keys():
print(key)
# 或者更简洁地
for key in my_dict:
print(key)
2. 遍历字典的值(Values)
类似地,使用dict.values()方法可以获得字典中所有的值,并通过循环遍历它们。
my_dict = {'a': 1, 'b': 2, 'c': 3}
for value in my_dict.values():
print(value)
3. 遍历字典的键值对(Items)
如果你需要同时访问字典的键和值,可以使用dict.items()方法,它会返回一个包含所有(键,值)对的视图对象,你可以遍历这个对象来访问每个键值对。
my_dict = {'a': 1, 'b': 2, 'c': 3}
for key, value in my_dict.items():
print(key, value)
4. 遍历字典时保持顺序(Python 3.7+)
在Python 3.7及以后的版本中,字典是按照插入顺序进行排序的,这意味着当你遍历字典时,元素会按照它们被添加到字典中的顺序出现。这在之前的Python版本中不是总能保证的。
my_dict = {'b': 2, 'a': 1, 'c': 3}
for key, value in my_dict.items():
print(key, value) # 输出将按照 'b', 'a', 'c' 的顺序
注意事项
- 在Python中,字典的迭代顺序在·Python 3.7及以后的版本中是有序的·,但如果你使用的是·Python 3.6或更早的版本,则不应依赖此行为。·
- 使用 dict.keys(), dict.values(), 和 dict.items()返回的都是视图对象(view objects), 它们反映字典的当前状态,但并不构成字典的副本。因此,这些视图对象支持迭代和成员测试,但不支持索引和切片操作。