(超详细解答)基于mapreduce在IDEA实现——寻找两两之间的共同好友问题
问题:求出两两之间的好友:
初始数据格式:
用户:该用户的好友
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
过程梳理(一):


对应代码(一):
MAP:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FMap1 extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String lines []=value.toString().split(":");
String usr=lines[0];
Text t1=new Text();
t1.set(usr);
String friend[]=lines[1].split(",");
Text t2=new Text();
for (int i=0;i {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
for (Text value:values){
stringBuffer.append(value).append(",");
}
stringBuffer.deleteCharAt(stringBuffer.length()-1);
context.write(key,new Text(stringBuffer.toString()));
}
}
DRIVER:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FDriver1 {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job =Job.getInstance(conf);
// job.setJarByClass(mapredTest.WDiver.class);
job.setMapperClass(FMap1.class);
job.setReducerClass(FRed1.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("file:\\E:\\game\\Student\\friend.txt"));
FileOutputFormat.setOutputPath(job,new Path("file:\\E:\\game\\Student\\ooput"));
job.waitForCompletion(true);
}
}
这些代码实现的就是我们上面分析的内容。
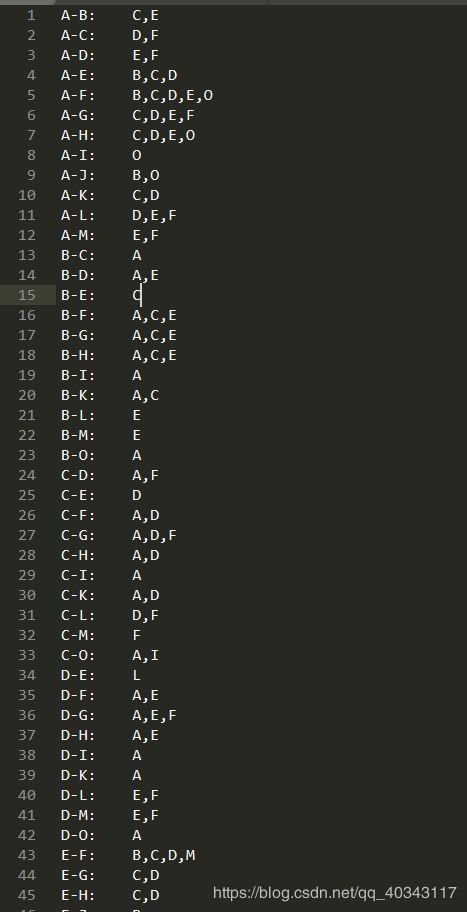
得到的数据(一)
要注意我们上面代码的输出路径一定不能存在,要让系统自己创建,否则会报错,一切正确后执行代码显示
 这些红色不是错误,只是一个jar包的冲突,看不习惯的对着自己的显示,删除一个jar包就可以,注意一定是删除其他文件夹里的,hadoop的不要动,显示0就是正常运行了,我们来到输出路径下会发现已经字啊创建了(其他的是我做别的实验建的)
这些红色不是错误,只是一个jar包的冲突,看不习惯的对着自己的显示,删除一个jar包就可以,注意一定是删除其他文件夹里的,hadoop的不要动,显示0就是正常运行了,我们来到输出路径下会发现已经字啊创建了(其他的是我做别的实验建的)
 打开我们的指定输出文件,打开part-0000这个就可以看我们的结果了
打开我们的指定输出文件,打开part-0000这个就可以看我们的结果了


过程梳理(二):


对应代码(二):
MAP:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Arrays;
public class FMap2 extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String lines[]=value.toString().split("\t");
String usr=lines[0];
String friend[]=lines[1].split(",");
Arrays.sort(friend);
for (int i=0;i {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
Set set=new HashSet();
for (Text value:values){
if (!set.contains(value.toString()))
{
set.add(value.toString());
}
}
for (String s:set){
stringBuffer.append(s).append(",");
}
stringBuffer.deleteCharAt(stringBuffer.length()-1);
context.write(key,new Text(stringBuffer.toString()));
}
}
DRIVER:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FDriver2 {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job =Job.getInstance(conf);
// job.setJarByClass(mapredTest.WDiver.class);
job.setMapperClass(FMap2.class);
job.setReducerClass(FRed2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("file:\\E:\\game\\Student\\ooput\\part-r-00000"));
FileOutputFormat.setOutputPath(job,new Path("file:\\E:\\game\\Studen\\oooput"));
job.waitForCompletion(true);
}
}


得到的数据(二)
注意我们这里的输出路径还是不能存在,没什么好说的,但是输入路径注意,一定是我们第一次mapper得到的数据,要不做两次mapreduce有什么用呢。
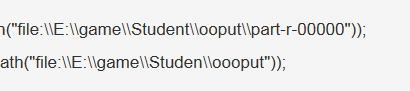
然后执行,就会得到结果