我们在爬虫时时常会遇到一些网页上的中文无法爬取到文件的问题,因为会出现乱码,本文就简要说明一些可能出现的中文编码问题。
获取网页的中文显示乱码
先放一个实例,我们爬取w3school官网上的一小段文字。

import requests
from bs4 import BeautifulSoup
url = 'http://w3school.com.cn/'
r = requests.get(url)
soup = BeautifulSoup(r.text, "lxml")
xx = soup.find('div', id = 'd1').h2.text
print(xx)
print(r.encoding)
'''
输出结果
ÁìÏ鵀 Web ¼¼Êõ½Ì³Ì - È«²¿Ãâ·Ñ
ISO-8859-1
'''
显然这不是我们想要的东西,这是因为我们代码中获得的网页响应体r和网站编码的编程方式不同,从上面我们可以看到Requests基于HTTP头部推测的文本编码是ISO-8859-1。
这时我们回到网页源码,发现此网页使用的编码方式是gbk,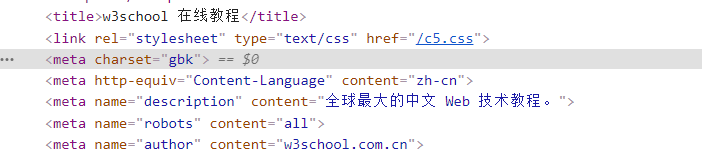
因此,我们只需要给r加一个声明,即加上r.encoding = 'gbk'这段代码,再次运行代码,我们就能发现可以得到正确结果了。
但是,我们会发现大多数网页都是不需要加声明编码的,这是因为大多数网页的编码方式都是UTF-8,而Requests会自动解码来自服务器的内容,大多数Unicode字符都能无缝的被解码,这里面就包括UTF-8,如图,淘宝网就声明的是UTF-8的编码方式。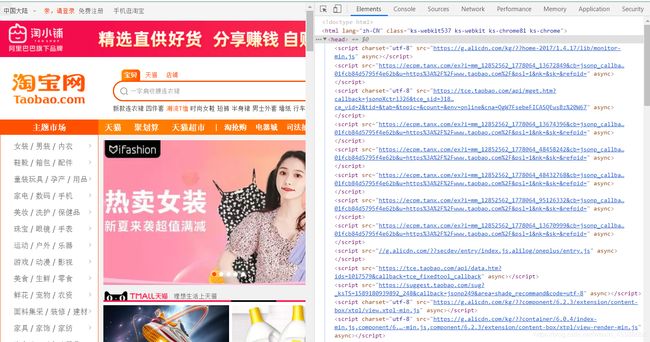
非法字符抛出异常
有时我们在爬虫时可能会因为网页中的某个非法字符的出现而使整个程序报错,这是由于这些网站的变法不规范造成的。我们看空格其实都差不多,但
是全角的空格还有多种不同的表现方式,\xa3\xa0、\xa4\x57和普通的中文输入法下的空格(\xa1\xa1)基本没有区别,但它就是一个非法字符,这是最令人头大的,但是解决方法也很简单,一行代码。
str1.decode('GBK', 'ignore')
在decode方法中,decode的函数模型是decode([encoding],[errors='strict']),第二个变量为控制错误处理的防水,默认为strict,遇到非法字符爆出异常,我们有三种方法设置第二个变量。
1.ingore,忽略其中的非法字符,仅显示有效字符。
2.replace,使用符号代替非法字符,如“?”。
3.xmlcharrefreplace,使用XML字符引用待敌非法字符。
网页使用gzip压缩
等我们使用Requests获取新浪网首页时,我们先去网页源码了解一下编码,很简单,我们发现是UTF-8编码,我们直接去爬取
import requests
url = 'http://www.sina.com.cn/'
r= requests.get(url)
print(r.text)
得到如下图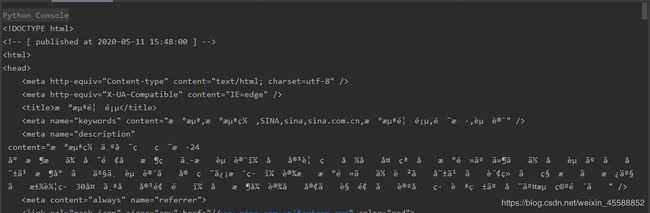
中文部分全部乱码,是不是满脸的疑惑,使用的编码方式也没有错呀,为什么还是全乱码。这是因为新浪网使用gzip将网页压缩了,要先解码才行,使用r.content会自动解码gzip和delate传输编码的响应数据。
import chardet
after_gzip = r.content
print(chardet.detect(after_gzip))
print(after_gzip.decode('UTF-8'))
在上面的代码中,首先使用r.content解压gzip,然后使用Charset找到该字符串的编码为UTF-8,最后把字符串解码为unicode,结果为