大数据手册(Hive)--HiveQL
文章目录
- Hive交互
- Hive内置运算符
- Hive数据类型
- Hive的数据存储
- HiveQL常用语句
- 创建/删除数据库
- 创建/删除表
- 修改表结构
- 导入导出数据
- 插入数据
- 查询语句
- 表连接
- 表联合
- 其他常用命令
- Hive常用内置函数
- Hive视图和索引
- Hive 中变量的使用
- 其他
Hive是一个数据仓库基础工具,在Hadoop中用来处理结构化数据。
Hive交互
hive启动
hive [--database dbname] ##进入CLI交互界面,默认进入default数据库
hive -v ##冗余verbose模式,额外打印出执行的HQL语句
hive -S ##静默Slient模式,不显示转化MR-Job的信息,只显示最终结果
hive -i 'hive-init.sql' ##进入Hive交互Shell时候先执行脚本中的HQL语句
#-----web管理
hive --service serviceName ##启动web服务
#打开web页面
#-----hive 远程服务
hive --serve hiveserve &
hive命令行交互模式
hive> select * from dummy #执行HiveQL语句
hive> source ./hive-script.sql ##执行HQL脚本
hive> !echo 'hello hive' ##执行shell命令,前面加 !即可
shell窗口执行hive语句
hive -e 'show tables;' ##从命令行执行指定的HQL
hive -f 'hive-script.sql' ##执行HQL脚本
hive -S -e 'show tables;' ##静默模式
Hive内置运算符
| 关系运算符 | 说明 |
|---|---|
| A = B | 等于 |
| A != B | 不等于 |
| A < B | 小于 |
| A <= B | 大于等于 |
| A > B | 大于 |
| A >= B | 大于等于 |
| A IS NULL | 空值 |
| A IS NOT NULL | 非空 |
| A LIKE B | 如果字符串模式A匹配到B,使用通配符,例如% |
| A RLIKE B | 如果A任何子字符串匹配正则表达式B |
| A REGEXP B | 字符串,同于RLIKE. |
| 算数运算符 | 描述 |
|---|---|
| A + B | |
| A - B | |
| A * B | |
| A / B | |
| A % B | 余数 |
| A & B | A和B的按位与结果 |
| A | B | A和B的按位或结果 |
| A ^ B | A和B的按位异或结果 |
| ~A | A按位非的结果 |
| 逻辑运算符 | 描述 |
|---|---|
| A AND B | |
| A && B | 类似于 A AND B. |
| A OR B | |
| A || B | 类似于 A OR B. |
| NOT A | |
| !A | 类似于 NOT A. |
| 复杂运算符 | 操作 | 描述 |
|---|---|---|
| A[n] | A是一个数组,n是一个int | 它返回数组A的第n个元素,第一个元素的索引0。 |
| M[key] | M 是一个 Map |
它返回对应于映射中关键字的值。 |
| S.x | S 是一个结构 | 它返回S的s字段 |
Hive数据类型
| 数据类型 | 说明 |
|---|---|
| tinyint/smallint/int/bigint | 整数类型 |
| float/double | 浮点型 |
| Boolean | 布尔类型 |
| string varchar(n)/char(n) |
字符串类型 |
array |
数组类型,同一类型[val1,val2,...] |
map |
集合类型, |
struct |
结构类型,包含不同类型 |
| 时间类型 | |
| date | 只有日期部分 |
| timestamp | 时间戳 |
Hive的数据存储
- 基于HDFS
- 内部表 table:我们删除表的时候在hdfs上对应的目录及数据文件一同被删除了
- 分区表 partition:对于数据库中的超大型表,可以通过把它的数据分成若干个小表,从而简化数据库的管理活动
- 外部表 external:受控表在删除一个表的时候,会把hdfs中的目录给删除掉,外部表是你在删除这个表的时候只删除了表定义,对于h
- 桶表 bucket:经过hash运算后方在不同的桶中
HiveQL常用语句
HiveQL是Hive支持的类似于SQL的查询语言。HiveQL大体可以分成下面两种类型
- DDL(data definition language) 比如创建数据库(create database),创建表(create table),数据库和表的删除
- DML(data manipulation language) 数据的添加,查询
- UDF(user defined function) Hive还支持用户自定义查询函数
创建/删除数据库
CREATE DATABASE [IF NOT EXISTS] userdb;
DROP DATABASE [IF EXISTS] userdb;
创建/删除表
-------创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] userdb.table_name (
id string COMMENT '主键',
name string COMMENT '字符',
age int COMMENT '整数',
married boolean COMMENT '布尔类型',
arr array<map<string,int>> COMMENT 'map数组',
info struct<addr:string,height:double,birth:date> COMMENT '结构类型',
)
COMMENT '表注释'
PARTITIONED BY(
date STRING COMMENT '日期分区',
sex STRING COMMENT '性别分区'
)
CLUSTERED BY(id) SORTED BY(num) INTO 32 BUCKETS
ROW FORMAT DELIMITED '\t'
FIELDS TERMINATED BY '\t'
STORED AS SEQUENCEFILE;
LOCATION 'hdfs_path';
--加上EXTERNAL时,建立外部表
--PARTITIONED BY 关键字建分区表
--CLUSTERED BY 关键字建Bucket表
--STORED AS 存储类型{SEQUENCEFILE:需要压缩,TEXTFILE:纯文本,RCFILE}
--LOCATION添加外部表存储路径
--------创建空表,复制表结构
CREATE TABLE [IF NOT EXISTS] empty_tablename
LIKE other_tablename;
--------直接导入数据
CREATE TABLE [IF NOT EXISTS] table_name
AS
SELECT ...;
--------删除表
DROP TABLE [IF EXISTS] table_name;
修改表结构
ALTER TABLE table_name
ADD COLUMNS (column_name [string COMMENT '新列'],...),
DROP [COLUMN] column_name,
RENAME TO new_name, --重命名表名
CHANGE column_name new_name new_type,
REPLACE COLUMNS (...); --替换表中所有字段
--添加/删除分区
ALTER TABLE table_name
ADD [IF NOT EXISTS] PARTITION (y='2018',m='07'),
DROP [IF EXISTS] PARTITION (y='2018',m='07');
--重命名分区
ALTER TABLE table_name PARTITION (y='2018',m='07')
RENAME TO PARTITION (y='18',m='07');
导入导出数据
--LOAD命令可以导入本地数据或者hdfs数据
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE table_name
PARTITION (
date='2018-07-03',
sex='M'
);
--LOCAL是标识符指定本地路径。它是可选的
--OVERWRITE是可选的,覆盖表中的数据
--PARTITION分区
--将hive数据导出到本地
INSERT OVERWRITE LOCAL DIRECTORY 'hdfs_path'
row format delimited fields terminated by '\t'
select ...;
--将hive数据放到hdfs文件系统中
INSERT OVERWRITE DIRECTORY 'hdfs_path'
SELECT ...;
插入数据
--将查询结果插入Hive表
INSERT OVERWRITE|INTO table table_name
PARTITION (y='2018',m='07')
SELECT ...;
--插入单条数据 (Hive 已支持单条插入)
INSERT INTO table_name VALUES('num',10086);
--将查询结果写入HDFS文件系统
INSERT OVERWRITE DIRECTORY 'hdfs_path'
SELECT ...;
查询语句
select查询支持正则表达式(select `patt`)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition] --可筛选聚合后结果
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]]
[ORDER BY col_list]
[LIMIT number];
#hive特殊用法,提出部分字段
set hive.support.quoted.identifiers=none;
select `(y|m|d)?+.+` from employee;
表连接
只支持等值连接
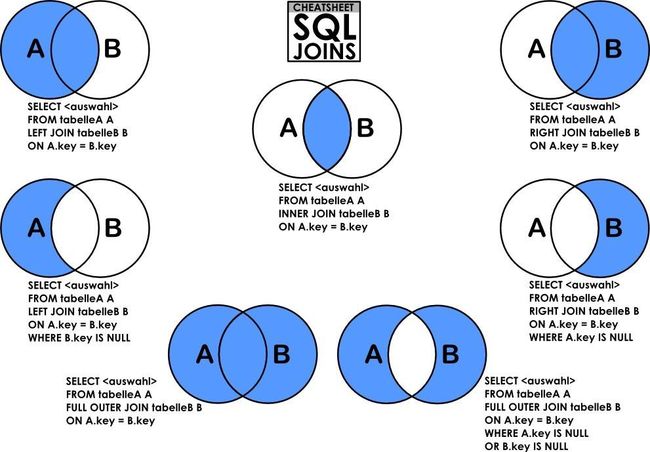
select column,... from tableA
--内连接
[INNER] JOIN tableB [ON join_condition]
--左/右/全连接
{LEFT|RIGHT|FULL} [OUTER] JOIN tableB ON join_condition
--差集连接
LEFT SEMI JOIN tableB ON join_condition
--笛卡儿积(on语句可以去除)
CROSS JOIN tableB [ON join_condition]
Example
购物记录表(shopping_records),节假日表(holidays),输出节假日购物记录
hive> SELECT * FROM shopping_records limit 3;
+------+--------+-------------+------------+--------+
| id | userid | channel | date | amount |
+------+--------+-------------+------------+--------+
| 001 | u1005 | wechart | 2018-11-11 | 1024 |
| 002 | u1005 | alipay | 2018-10-03 | 5050 |
| 003 | u1203 | credit_card | 2018-12-12 | 2048 |
+------+--------+-------------+------------+--------+
hive> SELECT * FROM holidays limit 3;
+-----------------+------------+------------+
| name | start_date | end_date |
+-----------------+------------+------------+
| Spring Festival | 2018-02-15 | 2018-02-21 |
| National Day | 2018-10-01 | 2018-10-07 |
| New Year's Day | 2017-12-30 | 2018-01-01 |
+-----------------+------------+------------+
hive> --JOIN...ON语句
hive> SELECT DISTINCT a.*
hive> FROM shopping_records a
hive> JOIN holidays b ON 1=1 --ON语句可以省略
hive> WHERE date BETWEEN start_date AND end_date;
hive> --CROSS JOIN笛卡儿积
hive> SELECT DISTINCT a.*
hive> FROM shopping_records a
hive> CROSS JOIN holidays b
hive> WHERE date BETWEEN start_date AND end_date;
hive> --直接select笛卡儿积
hive> SELECT DISTINCT a.* FROM shopping_records a,holidays b
hive> WHERE date BETWEEN start_date AND end_date;
hive> --输出
+------+--------+-------------+------------+--------+
| id | userid | channel | date | amount |
+------+--------+-------------+------------+--------+
| 002 | u1005 | alipay | 2018-10-03 | 5050 |
| ... | ... | ... | ... | ... |
+------+--------+-------------+------------+--------+
表联合
--联合语句(加上all不会自动去重)
select_statement
UNION [ALL] select_statement
UNION [ALL] select_statement
... ... ;
其他常用命令
SHOW DATABASES/TABLES; --查看数据库/表
SHOW DATABASES/TABLES LIKE "*keyword*";
USE db_name; --连接数据库db_name
SHOW PARTITIONS test_table; --查看分区
SHOW FUNCTIONS; --查看内置函数
SHOW CREATE TABLE table_name; -- 查看建表语句
DESC table_name; -- 表结构
DESC formatted table_name --查看表更新时间
DESC formatted table_name partition(name=value) --查看分区更新时间
EXPLAIN select * from dual; -- 解释语句
TRUNCATE TABLE table_name; -- 清空表
Hive常用内置函数
Hive2.0函数大全(中文版)
| 创建 | 描述 |
|---|---|
| array(value1,value2,…) | 创建数组 |
| map(key1,value1,key2,value2,…) | 创建字典 |
--将学生按score随机平均分配班级
hive> desc students;
id string
score string
hive> create table tmp
hive> as
hive> select id,score,
hive> case when score='A' then array('class 1','class 2')
hive> when score='B' then array('class 3','class 4')
hive> when score='C' then array('class 5','class 6')
hive> else null end as class
hive> from students;
hive> select id,score,
hive> case when rn%2=0 then class[0] else class[1] end as class
hive> from
hive> (select *,row_number() over(partition by score order by rand()) as rn from tmp) a
| 数学函数 | 描述 |
|---|---|
| count/sum/max/min/avg | 聚合函数 |
| exp(a) | ea |
| pow(a,b) | ab |
| sqrt(a) | 平方根 |
| ln/log2/log10/log(base,a) | 对数 |
| round(num,n) | 四舍五入 |
| floor(num) | 地板 |
| ceil(num) | 天花板 |
| rand(), rand(int,seed) | 随机数 |
| abs(a) | 绝对值 |
| sign(a) | 如果a是正数则返回1.0,是负数则返回-1.0,否则返回0.0 |
| e()/pi() | 常数e/pi |
| greatest(T v1, T v2, …) | 最大值 |
| least(T v1, T v2, …) | 最小值 |
| 集合函数 | 描述 |
|---|---|
size(Map |
它返回在映射类型的元素的数量。 |
size(Array |
它返回在数组类型元素的数量。 |
| collect_set(col) | 行转数组(去重) |
| collect_list(col) | 行转数组(不去重) |
array_contains(Array |
数组中是否包含value |
| explode(ARRAY) | 数组转行 |
explode(Map |
每行对应每个map的key-value,返回key,value两个字段 |
map_keys(Map |
返回所有的keys |
map_values(Map |
返回所有的values |
sort_array(Array |
对数据进行排序返回 |
| concat_ws(sep,array) | 将array中的元素合并成字符 |
hive> desc student;
id string
chinese float
math float
english float
hive> desc student2;
col_name data_type comment
id string
course string
score float
hive> select id,array(chinese,math,english) as score from student1;
id score
001 [90,95,80]
002 [70,65,83]
... ...
hive> select id,map('c',chinese,'m',math,'e',english) as score from student1;
id score
001 {'c':90,'m':95,'e':80}
002 {'c':70,'m':65,'e':83}
... ...
hive> select id,collect_set(score) as score from student2; --行收集成数组
id score
001 [90,95,80]
002 [70,65,83]
... ...
hive> SELECT id, avg(score) FROM
hive> (select id,array(chinese,math,english) as score from student1) a
hive> LATERAL VIEW explode(score) adTable AS score GROUP BY id; --数组分解成行,并聚合运算
hive> select id,course,score from
hive> (select id,map('c',chinese,'m',math,'e',english) as dict from student1) a
hive> LATERAL VIEW explode(dict) adTable AS course,score;
hive> ---分解字典并转行,重命名时逗号分隔(union函数替代品)
id course score
001 c 90
001 m 95
001 e 80
... ...
| 常用 | 描述 |
|---|---|
| corr(col1, col2) | 相关系数 |
| length(string) | 字符串长度 |
| concat(string A, string B,…) | 它返回从A后串联B产生的字符串 |
| concat_ws(sep,string A, string B,…) | 指定分隔符合并 |
| concat_ws(sep,array) | 将array中的元素合并成字符 |
| substr(string A, int start, int length) | 取子集 |
| upper(string A)/lower | |
| trim(string A) | 删除两侧空格 |
| ltrim(string A)/rtrim(string A) | 删除左/右空格 |
| regexp_replace(string A, string B, string C) | 用C替换B |
| split(str,pat) | 分割字符串,返回array |
| percentile_approx(col, p,B) | 百分位数 |
cast( |
将表达式的结果转换类型 |
| case when … then…else…end | |
| between…and… | |
| if(condition,valueTrue,valueFalseorNull) | 条件判断 |
| nvl(value,default_value) | 如果value值为NULL就返回default_value,否则返回value |
| coalesce(T v1, T v2, …) | 返回第一非null的值,如果全部都为NULL就返回NUL |
| isnull( a )/isnotnull( a ) | 判断返回boolean |
| row_number() over | 分组排序 |
select *,row_number() OVER (partition by deptid order by salary desc) as rk from employee;
# 备份
empl=(`hive -e "show partitions employee;"`)
emp2=(`hive -e "show partitions employee_backup;"`)
for((i=1;i<${#empl[@]};i++))
do
update=${#empl[@]}
tmp=(`echo ${emp2[@]} | grep ${update}`)
if [ -z ${tmp} ]
then
hive "
insert overwrite table tmp2 partition(${update})
select `(y|m|d)?+.+` from employee where ${update}
;"
printf "%-20s\n" ${update} > info
fi
done
| 日期时间函数 | 说明 |
|---|---|
| from_unixtime(int unixtime) | 转换的秒数从Unix纪元(1970-01-0100:00:00 UTC) |
| to_date(string timestamp) | 返回一个字符串时间戳的日期部分 |
| date_format(date,format) | 按制定格式返回日期 Format参考文献 |
| year(string date) | |
| quarter(string date) | 季度 |
| month(string date) | |
| day(string date) | |
| current_date() | 当前日期 |
| weekofyear(string date) | |
| datediff(start,end) | 返回相差天数 |
| months_between(date,date) | 相差月份 |
| date_add()/date_sub() | 日期加/减若干天数 |
| add_months(date,int) | 日期加若干月 |
| last_day(date) | 这个月最后一天 |
| trunc(date,format) | 年(“YY”)或月(“MM”)的第一天 |
| next_day(date,string day_of_week) | 下个周X对应的日期 |
| get_json_object(string json_string, string path) |
Hive视图和索引
- 视图: 逻辑表,不存储实际数据
- 索引:
--创建视图
CREATE VIEW [IF NOT EXISTS] view_name
(column_name COMMENT '列说明', ...)
TBLPROPERTIES (property_name = property_value, ...)
COMMENT '视图注释'
AS SELECT ...;
--删除试图
DROP VIEW view_name;
--创建索引
CREATE INDEX index_name
ON TABLE base_table_name (col_name, ...)
AS 'index.handler.class.name'
[WITH DEFERRED REBUILD]
[IDXPROPERTIES (property_name=property_value, ...)]
[IN TABLE index_table_name]
[PARTITIONED BY (col_name, ...)]
[ ROW FORMAT ...] [STORED AS ...| STORED BY ...]
[LOCATION hdfs_path]
[TBLPROPERTIES (...)];
--删除索引
DROP INDEX <index_name> ON <table_name>
Hive 中变量的使用
- shell中设置变量,hive -e中直接使用
#!/bin/bash tablename="student" limitcount="8" hive -e "select * from ${tablename} limit ${limitcount};" - 使用-hiveconf定义,在SQL文件中使用
SQL文件内容如下hive -hiveconf tablename='student' -hiveconf limitcount=8 -f test.sql
注意,hiveconf不能在 hive -e中使用select * from ${hiveconf:tablename} limit ${hiveconf:limitcount}; - 使用用户自定义变量 hivevar
hiveconf 变量也可以在SQL文件中以类似的方式设置,引用时必须加上hiveconf前缀hive > set hivevar: tablename="student"; hive > set hivevar: limitcount="8"; hive > set ${hivevar: tablename}; --hivevar 使用前缀查看变量 tablename="student" hive > select * from ${tablename} limit ${limitcount}; --不使用前缀也可以引用使用
其他
Hive性能调优
部分Hadoop命令
参考链接:
易百教程 | Hive教程
HiveQL基础知识及常用语句总结
Hive Shell常用操作