Python手册(Machine Learning)--statsmodels(TimeSeries)
TimeSeries
- Time Series analysis tsa(时间序列分析)
- 常用模型
- ARIMA模型运用的流程
- Example: ARMA example: Sunspots data
- Time Series Analysis by State Space Methods statespace(基于状态空间方法的时间序列分析)
- 模型意义
- 状态空间模型的建立和预测的步骤
- Vector Autoregressions tsa.vector_ar(矢量自动回归)
- VAR进程(VAR processes)
- 模型拟合(Model fitting)
- 滞后顺序选择(Lag order selection)
- 预测(Forecasting)
- 脉冲响应分析(Impulse Response Analysis)
- 预测误差方差分解(FEVD)
- 统计检验(Statistical tests)
- 动态矢量自动回归(Dynamic Vector Autoregressions)
Python手册(Machine Learning)–statsmodels(GettingStarted)
Python手册(Machine Learning)–statsmodels(Regression)
Python手册(Machine Learning)–statsmodels(ANOVA)
Python手册(Machine Learning)–statsmodels(Tables+Imputation)
Python手册(Machine Learning)–statsmodels(MultivariateStatistics)
Python手册(Machine Learning)–statsmodels(TimeSeries)
Python手册(Machine Learning)–statsmodels(Survival)
Python手册(Machine Learning)–statsmodels(Graphics)
时间序列分析是根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。它一般采用曲线拟合和参数估计方法(如非线性最小二乘法)进行。时间序列分析常用在国民经济宏观控制、区域综合发展规划、企业经营管理、市场潜量预测、气象预报、水文预报、地震前兆预报、农作物病虫灾害预报、环境污染控制、生态平衡、天文学和海洋学等方面。
Time Series analysis tsa(时间序列分析)
http://www.statsmodels.org/stable/tsa.html
参考链接:
python时间序列分析之ARIMA
AR(I)MA时间序列建模过程——步骤和python代码
https://www.ziiai.com/blog/638
https://www.analyticsvidhya.com/blog/2015/12/complete-tutorial-time-series-modeling/
from statsmodels import tsa
| 子模块 | 说明 |
|---|---|
| stattools | 经验属性和测试,acf,pacf,granger-causality,adf单位根测试,kpss测试,bds测试,ljung-box测试等。 |
| ar_model | 单变量自回归过程,使用条件和精确最大似然估计和条件最小二乘 |
| arima_mode | 单变量ARMA过程,使用条件和精确最大似然估计和条件最小二乘法 |
| vector_ar,var | 向量自回归过程(VAR)估计模型,脉冲响应分析,预测误差方差分解和数据可视化工具 |
| kalmanf | 使用卡尔曼滤波器的ARMA和其他具有精确MLE的模型的估计类 |
| arma_process | 具有给定参数的arma进程的属性,包括在ARMA,MA和AR表示之间进行转换的工具以及acf,pacf,频谱密度,脉冲响应函数和类似 |
| sandbox.tsa.fftarma | 类似于arma_process但在频域工作 |
| tsatools | 额外的辅助函数,用于创建滞后变量数组,构造趋势,趋势和类似的回归量。 |
| filters | 过滤时间序列的辅助函数 |
| regime_switching | 马尔可夫切换动态回归和自回归模型 |
常用模型
常用的时间序列模型有四种:自回归模型 A R ( p ) AR(p) AR(p)、移动平均模型 M A ( q ) MA(q) MA(q)、自回归移动平均模型 A R M A ( p , q ) ARMA(p,q) ARMA(p,q)、自回归差分移动平均模型 A R I M A ( p , d , q ) ARIMA(p,d,q) ARIMA(p,d,q)
ARMA模型
自回归滑动平均模型(英语:Autoregressive moving average model,简称:ARMA模型)。是研究时间序列的重要方法,由自回归模型(简称AR模型)与移动平均模型(简称MA模型)为基础“混合”构成。
基本原理: Y t = β 1 Y t − 1 + β 2 Y t − 2 + . . . + β p Y t − p + Z t Y_t=\beta_1Y_{t-1}+\beta_2Y_{t-2}+...+\beta_pY_{t-p}+Z_t Yt=β1Yt−1+β2Yt−2+...+βpYt−p+Zt
误差项: Z t = ε t + α 1 ε t − 1 + α 2 ε t − 2 + . . . + + α q ε t − q Z_t=\varepsilon_t+\alpha_1\varepsilon_{t-1}+\alpha_2\varepsilon_{t-2}+...++\alpha_q\varepsilon_{t-q} Zt=εt+α1εt−1+α2εt−2+...++αqεt−q
ARIMA模型
ARIMA模型(英语:AutoregressiveIntegratedMovingAverage model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),时间序列预测分析方法之一。ARIMA(p,d,q)中,AR是"自回归",p为自回归项数;MA为"滑动平均",q为滑动平均项数,d为使之成为平稳序列所做的差分次数(阶数)。
当时间序列本身不是平稳的时候,如果它的增量,即一次差分,稳定在零点附近,可以将看成是平稳序列。在实际的问题中,所遇到的多数非平稳序列可以通过一次或多次差分后成为平稳时间序列,则可以建立模型。
ARIMA模型运用的流程
- 根据时间序列的散点图、自相关函数和偏自相关函数图识别其平稳性。
- 对非平稳的时间序列数据进行平稳化处理。直到处理后的自相关函数和偏自相关函数的数值非显著非零。
- 根据所识别出来的特征建立相应的时间序列模型。平稳化处理后,若偏自相关函数是截尾的,而自相关函数是拖尾的,则建立AR模型;若偏自相关函数是拖尾的,而自相关函数是截尾的,则建立MA模型;若偏自相关函数和自相关函数均是拖尾的,则序列适合ARMA模型。
- 参数估计,检验是否具有统计意义。
- 假设检验,判断(诊断)残差序列是否为白噪声序列。
- 利用已通过检验的模型进行预测
Example: ARMA example: Sunspots data
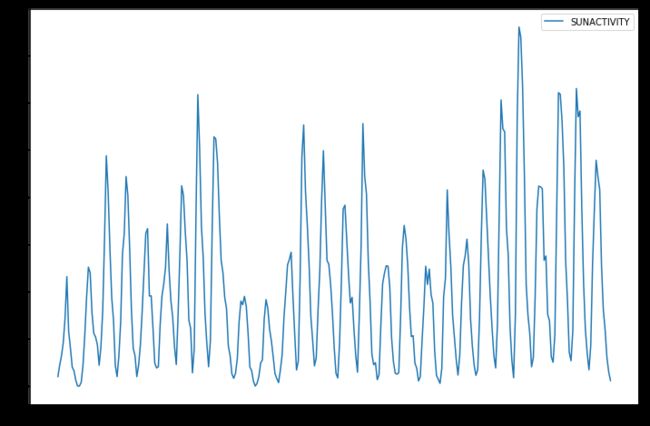
导入数据并作图
from __future__ import print_function
import numpy as np
from scipy import stats
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.api import qqplot
dta = sm.datasets.sunspots.load_pandas().data
dta.index = pd.Index(sm.tsa.datetools.dates_from_range('1700', '2008'))
del dta["YEAR"]
dta.plot(figsize=(12,8))
plt.show()
参数估计
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta.values.squeeze(), lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta, lags=40, ax=ax2)

拟合模型并评估
>>> arma_mod20 = sm.tsa.ARMA(dta, (2,0)).fit(disp=False)
>>> print(arma_mod20.params)
const 49.659542
ar.L1.SUNACTIVITY 1.390656
ar.L2.SUNACTIVITY -0.688571
dtype: float64
/Users/taugspurger/sandbox/statsmodels/statsmodels/tsa/base/tsa_model.py:171: ValueWarning: No frequency information was provided, so inferred frequency A-DEC will be used.
% freq, ValueWarning)
>>> arma_mod30 = sm.tsa.ARMA(dta, (3,0)).fit(disp=False)
/Users/taugspurger/sandbox/statsmodels/statsmodels/tsa/base/tsa_model.py:171: ValueWarning: No frequency information was provided, so inferred frequency A-DEC will be used.
% freq, ValueWarning)
>>> print(arma_mod20.aic, arma_mod20.bic, arma_mod20.hqic)
2622.636338065809 2637.5697031734 2628.606725911055
>>> print(arma_mod30.params)
const 49.749936
ar.L1.SUNACTIVITY 1.300810
ar.L2.SUNACTIVITY -0.508093
ar.L3.SUNACTIVITY -0.129650
dtype: float64
>>> print(arma_mod30.aic, arma_mod30.bic, arma_mod30.hqic)
2619.4036286964474 2638.0703350809363 2626.866613503005
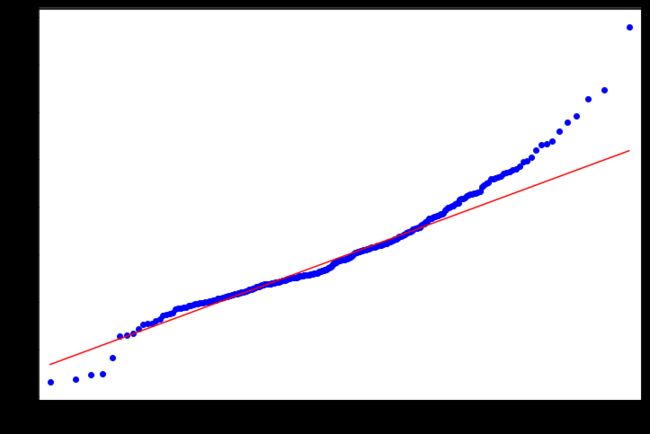
假设检验
>>> sm.stats.durbin_watson(arma_mod30.resid.values) #D-W检验
1.9564807635787604
>>> fig = plt.figure(figsize=(12,8))
>>> ax = fig.add_subplot(111)
>>> ax = arma_mod30.resid.plot(ax=ax) #残差正态
>>> resid = arma_mod30.resid
>>> stats.normaltest(resid)
NormaltestResult(statistic=49.845019661107585, pvalue=1.5006917858823576e-11)
>>> fig = plt.figure(figsize=(12,8))
>>> ax = fig.add_subplot(111)
>>> fig = qqplot(resid, line='q', ax=ax, fit=True)

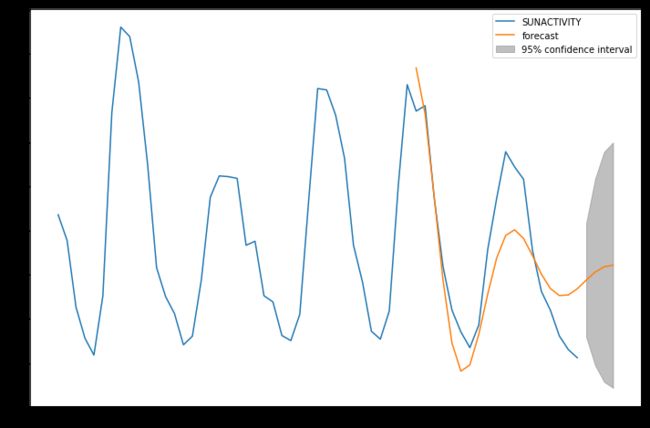
模型预测
predict_sunspots = arma_mod30.predict('1990', '2012', dynamic=True)
fig, ax = plt.subplots(figsize=(12, 8))
ax = dta.loc['1950':].plot(ax=ax)
fig = arma_mod30.plot_predict('1990', '2012', dynamic=True, ax=ax, plot_insample=False)
Time Series Analysis by State Space Methods statespace(基于状态空间方法的时间序列分析)
http://www.statsmodels.org/stable/statespace.html
statsmodels.tsa.statespace
模型意义
状态空间模型起源于平稳时间序列分析。当用于非平稳时间序列分析时需要将非平稳时间序列分解为随机游走成分(趋势)和弱平稳成分两个部分分别建模。 含有随机游走成分的时间序列又称积分时间序列,因为随机游走成分是弱平稳成分的和或积分。当一个向量值积分序列中的某些序列的线性组合变成弱平稳时就称这些序列构成了协调积分(cointegrated)过程。 非平稳时间序列的线性组合可能产生平稳时间序列这一思想可以追溯到回归分析,Granger提出的协调积分概念使这一思想得到了科学的论证。 Aoki和Cochrane等人的研究表明:很多非平稳多变量时间序列中的随机游走成分比以前人们认为的要小得多,有时甚至完全消失。百度百科
状态空间模型的建立和预测的步骤
为了避免由于状态空间模型的不可控制性而导致的错误的分解形式,当对一个单整时间序列建立状态空间分解模型并进行预测,应按下面的步骤执行:
(1) 对相关的时间序列进行季节调整,并将季节要素序列外推;
(2) 对季节调整后的时间序列进行单位根检验,确定单整阶数,然后在ARIMA过程中选择最接近的模型;
(3) 求出ARIMA模型的系数;
(4) 用ARIMA模型的系数准确表示正规状态空间模型,检验状态空间模型的可控制性;
(5) 利用Kalman滤波公式估计状态向量,并对时间序列进行预测。
(6) 把外推的季节要素与相应的预测值合并,就得到经济时间序列的预测结果
Vector Autoregressions tsa.vector_ar(矢量自动回归)
http://www.statsmodels.org/stable/vector_ar.html
from statsmodels.tsa.api import VAR
向量自回归(VAR)是基于数据的统计性质建立模型,VAR模型把系统中每一个内生变量作为系统中所有内生变量的滞后值的函数来构造模型,从而将单变量自回归模型推广到由多元时间序列变量组成的“向量”自回归模型。VAR模型是处理多个相关经济指标的分析与预测最容易操作的模型之一,并且在一定的条件下,多元MA和ARMA模型也可转化成VAR模型,因此近年来VAR模型受到越来越多的经济工作者的重视。
VAR进程(VAR processes)
VAR(p)建立 T × K T \times K T×K多变量时间序列Y,T为观测数量,K为变量数量。
估计时间序列与其滞后值之间关系的向量自回归过程为:
Y t = A 1 Y t − 1 + . . . + A p Y t − p + u t u t = N ( 0 , Σ u ) Y_t=A_1Y_{t-1}+...+A_pY_{t-p}+u_t \\ u_t=N(0,\Sigma_u) Yt=A1Yt−1+...+ApYt−p+utut=N(0,Σu)
A i A_i Ai 是一个 K×K 系数矩阵
模型拟合(Model fitting)
statsmodels.tsa.api
# some example data
In [1]: import numpy as np
In [2]: import pandas
In [3]: import statsmodels.api as sm
In [4]: from statsmodels.tsa.api import VAR, DynamicVAR
In [5]: mdata = sm.datasets.macrodata.load_pandas().data
# prepare the dates index
In [6]: dates = mdata[['year', 'quarter']].astype(int).astype(str)
In [7]: quarterly = dates["year"] + "Q" + dates["quarter"]
In [8]: from statsmodels.tsa.base.datetools import dates_from_str
In [9]: quarterly = dates_from_str(quarterly)
In [10]: mdata = mdata[['realgdp','realcons','realinv']]
In [11]: mdata.index = pandas.DatetimeIndex(quarterly)
In [12]: data = np.log(mdata).diff().dropna()
# make a VAR model
In [13]: model = VAR(data)
In [14]: results = model.fit(2)
In [15]: results.summary()
注意:本VAR类假定通过时间序列是静止的。非静态或趋势数据通常可以通过第一差分或一些其他方法变换为静止的。对于非平稳时间序列的直接分析,标准稳定VAR(p)模型是不合适的。
In [16]: results.plot()
Out[16]: <Figure size 1000x1000 with 3 Axes>

绘制时间序列自相关函数:
In [17]: results.plot_acorr()
Out[17]: <Figure size 1000x1000 with 9 Axes>
滞后顺序选择(Lag order selection)
滞后顺序的选择可能是一个难题。标准分析采用可能性测试或基于信息标准的顺序选择。我们已经实现了后者,可通过VAR模型访问:
In [18]: model.select_order(15)
Out[18]: <statsmodels.tsa.vector_ar.var_model.LagOrderResults at 0x10c89fef0>
# 调用fit函数时,可以传递最大滞后数和order标准以用于order选择
In [19]: results = model.fit(maxlags=15, ic='aic')
预测(Forecasting)
The linear predictor is the optimal h-step ahead forecast in terms of mean-squared error:
y t ( h ) = ν + A 1 y t ( h − 1 ) + ⋯ + A p y t ( h − p ) y_t(h)=ν+A_1y_t(h−1)+⋯+A_py_t(h−p) yt(h)=ν+A1yt(h−1)+⋯+Apyt(h−p)
我们可以使用预测函数来生成此预测。请注意,我们必须为预测指定“初始值”:
In [20]: lag_order = results.k_ar
In [21]: results.forecast(data.values[-lag_order:], 5)
Out[21]:
array([[ 0.0062, 0.005 , 0.0092],
[ 0.0043, 0.0034, -0.0024],
[ 0.0042, 0.0071, -0.0119],
[ 0.0056, 0.0064, 0.0015],
[ 0.0063, 0.0067, 0.0038]])
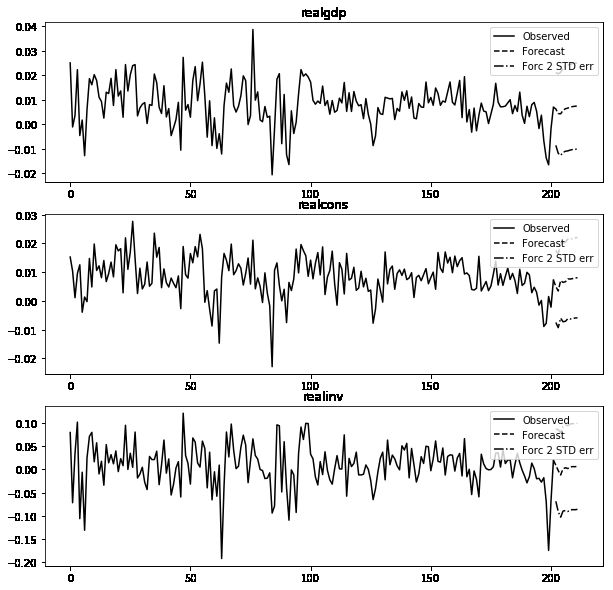
In [22]: results.plot_forecast(10)
Out[22]: <Figure size 1000x1000 with 3 Axes>
脉冲响应分析(Impulse Response Analysis)
在计量经济学研究中,脉冲响应是有意义的:它们是对其中一个变量中单位脉冲的估计响应。它们是在实践中使用 M A ( ∞ ) MA(\infty) MA(∞)计算 V A R ( p ) VAR(p) VAR(p)过程:
Y t = μ + ∑ i = 0 ∞ Φ i u t − i Y_t=\mu + \displaystyle\sum_{i=0}^{\infty} \Phi_i u_{t-i} Yt=μ+i=0∑∞Φiut−i
我们可以通过调用VARResults对象上的irf函数来执行脉冲响应分析:
In [23]: irf = results.irf(10)
#这些可以使用绘图函数以正交或非正交形式可视化。
#默认情况下,渐近标准误差绘制在95%显着性水平,可由用户修改。
In [24]: irf.plot(orth=False)
Out[24]: <Figure size 1000x1000 with 9 Axes>
#绘图功能非常灵活,如果需要,只能绘制感兴趣的变量
In [25]: irf.plot(impulse='realgdp')
Out[25]: <Figure size 1000x1000 with 3 Axes>
累积效应 Ψ n = ∑ i = 0 n Φ i \Psi_n=\sum_{i=0}^n \Phi_i Ψn=∑i=0nΦi 可以用长期运行效果绘制:
In [26]: irf.plot_cum_effects(orth=False)
Out[26]: <Figure size 1000x1000 with 9 Axes>
预测误差方差分解(FEVD)
可以使用正交化脉冲响应来分解在i-step预测中k上的分量j的预测误差 Θ i \Theta_i Θi:
通过fevd函数向前总计步数计算
In [27]: fevd = results.fevd(5)
In [28]: fevd.summary()
FEVD for realgdp
realgdp realcons realinv
0 1.000000 0.000000 0.000000
1 0.864889 0.129253 0.005858
2 0.816725 0.177898 0.005378
3 0.793647 0.197590 0.008763
4 0.777279 0.208127 0.014594
FEVD for realcons
realgdp realcons realinv
0 0.359877 0.640123 0.000000
1 0.358767 0.635420 0.005813
2 0.348044 0.645138 0.006817
3 0.319913 0.653609 0.026478
4 0.317407 0.652180 0.030414
FEVD for realinv
realgdp realcons realinv
0 0.577021 0.152783 0.270196
1 0.488158 0.293622 0.218220
2 0.478727 0.314398 0.206874
3 0.477182 0.315564 0.207254
4 0.466741 0.324135 0.209124
它们也可以通过返回的FEVD对象可视化
In [29]: results.fevd(20).plot()
Out[29]: <Figure size 1000x1000 with 3 Axes>
统计检验(Statistical tests)
提供了许多不同的方法来进行关于模型结果的假设检验以及模型假设的正确性(normality, whiteness / “iid-ness” of errors, etc)
格兰杰因果关系(Granger causality)
- 格兰杰本人在其2003年获奖演说中强调了其引用的局限性,以及“很多荒谬论文的出现”(Of course, many ridiculous papers appeared)。由于其统计学本质上是对平稳时间序列数据一种预测,仅适用于计量经济学的变量预测,不能作为检验真正因果性的判据。
- 在时间序列情形下,两个经济变量X、Y之间的格兰杰因果关系定义为:若在包含了变量X、Y的过去信息的条件下,对变量Y的预测效果要优于只单独由Y的过去信息对Y进行的预测效果,即变量X有助于解释变量Y的将来变化,则认为变量X是引致变量Y的格兰杰原因。
- 进行格兰杰因果关系检验的一个前提条件是时间序列必须具有平稳性,否则可能会出现虚假回归问题。因此在进行格兰杰因果关系检验之前首先应对各指标时间序列的平稳性进行单位根检验(unit root test)。常用增广的迪基—富勒检验(ADF检验)来分别对各指标序列的平稳性进行单位根检验
In [30]: results.test_causality('realgdp', ['realinv', 'realcons'], kind='f')
Out[30]: <statsmodels.tsa.vector_ar.hypothesis_test_results.CausalityTestResults at 0x10ca15978>
动态矢量自动回归(Dynamic Vector Autoregressions)
注意:要使用此功能, 必须安装pandas
人们通常对估计时间序列数据的移动窗口回归感兴趣,以便在整个数据样本中进行预测。例如,我们可能希望生成由每个时间点估计的VAR(p)模型产生的一系列两步预测。
In [31]: np.random.seed(1)
In [32]: import pandas.util.testing as ptest
In [33]: ptest.N = 500
In [34]: data = ptest.makeTimeDataFrame().cumsum(0)
In [35]: data
Out[35]:
A B C D
2000-01-03 1.624345 -1.719394 -0.153236 1.301225
2000-01-04 1.012589 -1.662273 -2.585745 0.988833
2000-01-05 0.484417 -2.461821 -2.077760 0.717604
2000-01-06 -0.588551 -2.753416 -2.401793 2.580517
2000-01-07 0.276856 -3.012398 -3.912869 1.937644
... ... ... ... ...
2001-11-26 29.552085 14.274036 39.222558 -13.243907
2001-11-27 30.080964 11.996738 38.589968 -12.682989
2001-11-28 27.843878 11.927114 38.380121 -13.604648
2001-11-29 26.736165 12.280984 40.277282 -12.957273
2001-11-30 26.718447 12.094029 38.895890 -11.570447
[500 rows x 4 columns]
In [36]: var = DynamicVAR(data, lag_order=2, window_type='expanding')
动态模型的估计系数作为pandas.Panel对象返回 ,这可以让您轻松地按等式或按日期检查所有模型系数:
In [37]: import datetime as dt
In [38]: var.coefs
Out[38]:
<class 'pandas.core.panel.Panel'>
Dimensions: 9 (items) x 489 (major_axis) x 4 (minor_axis)
Items axis: L1.A to intercept
Major_axis axis: 2000-01-18 00:00:00 to 2001-11-30 00:00:00
Minor_axis axis: A to D
# all estimated coefficients for equation A
In [39]: var.coefs.minor_xs('A').info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 489 entries, 2000-01-18 to 2001-11-30
Freq: B
Data columns (total 9 columns):
L1.A 489 non-null float64
L1.B 489 non-null float64
L1.C 489 non-null float64
L1.D 489 non-null float64
L2.A 489 non-null float64
L2.B 489 non-null float64
L2.C 489 non-null float64
L2.D 489 non-null float64
intercept 489 non-null float64
dtypes: float64(9)
memory usage: 58.2 KB
# coefficients on 11/30/2001
In [40]: var.coefs.major_xs(dt.datetime(2001, 11, 30)).T
Out[40]:
A B C D
L1.A 0.971964 0.045960 0.003883 0.003822
L1.B 0.043951 0.937964 0.000735 0.020823
L1.C 0.038144 0.018260 0.977037 0.129287
L1.D 0.038618 0.036180 0.052855 1.002657
L2.A 0.013588 -0.046791 0.011558 -0.005300
L2.B -0.048885 0.041853 0.012185 -0.048732
L2.C -0.029426 -0.015238 0.011520 -0.119014
L2.D -0.049945 -0.025419 -0.045621 -0.019496
intercept 0.113331 0.248795 -0.058837 -0.089302
可以使用forecast函数生成前面给定步骤的动态预测,并返回pandas.DataMatrix对象:
In [41]: var.forecast(2)
Out[41]:
A B C D
2000-01-20 -260.325888 -23.141610 104.930427 -134.489882
2000-01-21 -52.121483 -11.566786 29.383608 -15.099109
2000-01-24 -54.900049 -23.894858 40.470913 -19.199059
2000-01-25 -7.493484 -4.057529 6.682707 4.301623
2000-01-26 -6.866108 -5.065873 5.623590 0.796081
... ... ... ... ...
2001-11-26 31.886126 13.515527 37.618145 -11.464682
2001-11-27 32.314633 14.237672 37.397691 -12.809727
2001-11-28 30.896528 15.488388 38.541596 -13.129524
2001-11-29 30.077228 15.533337 38.734096 -12.900891
2001-11-30 30.510380 13.491615 38.088228 -12.384976
[487 rows x 4 columns]
可以使用plot_forecast显示预测:
In [42]: var.plot_forecast(2)
