爬虫——scrapy,弱引用weakref.ref
- 爬虫框架
- scrapy
- 介绍:
- 组件
- 安装:
- 介绍:
- 步骤
- XPATH用法
- 调试bug
- 安装
- 查看链接
- xpath是否生效
- 弱引用
爬虫框架
爬虫的框架无非就是3步骤:
- 过滤——筛选需要的信息
- 映射——把数据映射想要的形式
- 规约——提取有用的信息
filter——map——reduce
下面这个图很好的解释了什么是这三部的含义
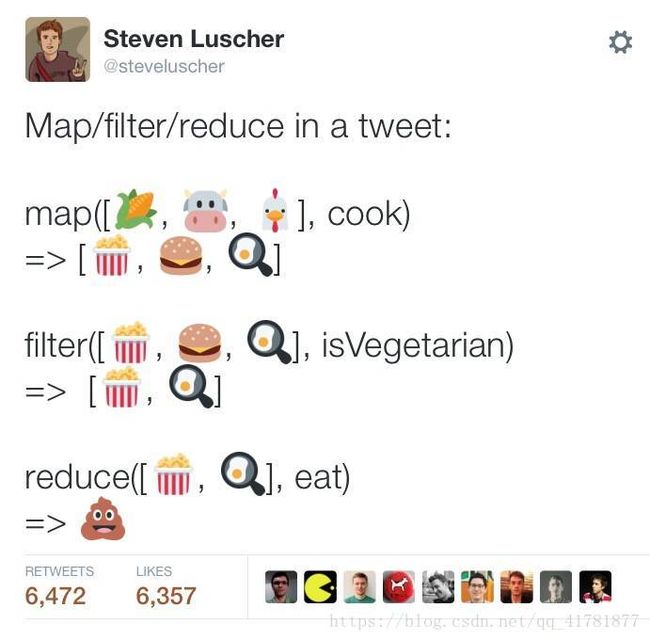
scrapy
前面我们学习了多种包括利用自带的和第三方的插件来进行爬取数据,现在介绍一个简单流行的爬虫框架——scrapy
介绍:
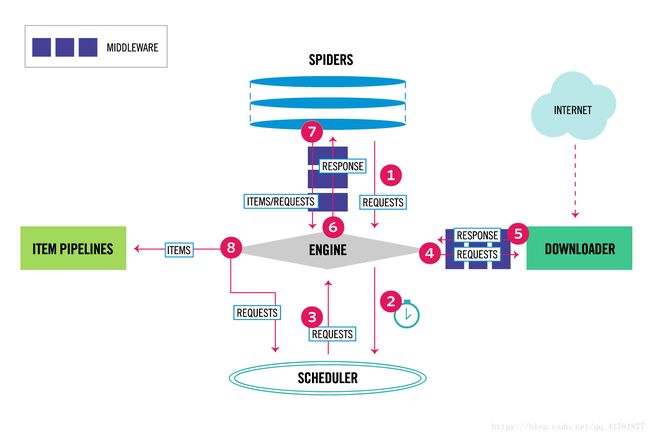
下图展示了Scrapy的基本架构,其中包含了主要组件和系统的数据处理流程(图中带数字的红色箭头)。
组件
1.Scrapy引擎(Engine):Scrapy引擎是用来控制整个系统的数据处理流程。
2.调度器(Scheduler):调度器从Scrapy引擎接受请求并排序列入队列,并在—–Scrapy引擎发出请求后返还给它们。
3.下载器(Downloader):下载器的主要职责是抓取网页并将网页内容返还给蜘蛛(Spiders)。
4.蜘蛛(Spiders):蜘蛛是有Scrapy用户自定义的用来解析网页并抓取特定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名,简单的说就是用来定义特定网站的抓取和解析规则。
5.条目管道(Item Pipeline):条目管道的主要责任是负责处理有蜘蛛从网页中抽取的数据条目,它的主要任务是清理、验证和存储数据。当页面被蜘蛛解析后,将被发送到条目管道,并经过几个特定的次序处理数据。每个条目管道组件都是一个Python类,它们获取了数据条目并执行对数据条目进行处理的方法,同时还需要确定是否需要在条目管道中继续执行下一步或是直接丢弃掉不处理。条目管道通常执行的任务有:清理HTML数据、验证解析到的数据(检查条目是否包含必要的字段)、检查是不是重复数据(如果重复就丢弃)、将解析到的数据存储到数据库(关系型数据库或NoSQL数据库)中。
6.中间件(Middlewares):中间件是介于Scrapy引擎和其他组件之间的一个钩子框架,主要是为了提供自定义的代码来拓展Scrapy的功能,包括下载器中间件和蜘蛛中间件。
安装:
同样最好配置虚拟环境
然后更新一些pip
安装scrapy
安装的时候会报错缺少c++主键去下载然后安装
执行scrapy
scrapy startporject NAME .(注意这里需要打一个“.”)
根据提示:敲如下命令:scrapy genspider NAME 主url –template=crawl
上述步骤如下图

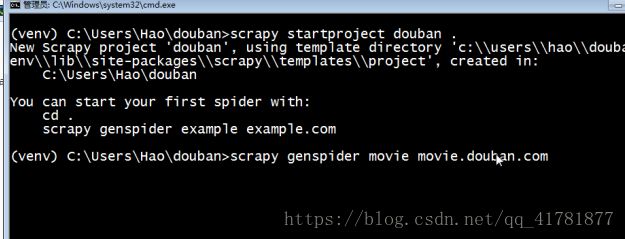
如果在创建genspider的时候没有加 –template=crawl,spiders文件中就会使用scrapy.Spider类而不是CrawlSpider,主要区别在于使用rules,只有Craw能使用,节约时间和效率,但是如果要写具体的复杂url还是需要改写,这个我们下一篇来说明
步骤
在items.py文件中定义字段,这些字段用来保存数据,方便后续的操作。
xxx = scrapy.Field()
xxxx = scrapy.Field()在spiders文件夹中编写自己的爬虫。
这里会运用到xpath,
xpath类似find和select同样表示在前端筛选爬取的数据
其中rules表示自动根据写入的url来爬取,简单点说遇到你写的url如果写了回滚函数(callback)就去执行,如果没写就表示在该url中继续爬取a标签
import scrapy
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from douban.items import DoubanItem
class MovieSpider(CrawlSpider):
name = 'movie'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
rules = (
Rule(LinkExtractor(allow=(r'https://movie.douban.com/top250\?start=\d+.*'))),
Rule(LinkExtractor(allow=(r'https://movie.douban.com/subject/\d+')), callback='parse_item'),
)
def parse_item(self, response):
sel = Selector(response)
item = DoubanItem()
item['name']=sel.xpath('//*[@id="content"]/h1/span[1]/text()').extract()
item['year']=sel.xpath('//*[@id="content"]/h1/span[2]/text()').re(r'\((\d+)\)')
return item3.在pipelines.py中完成对数据进行持久化的操作。
4. 修改settings.py文件对项目进行配置。
# -*- coding: utf-8 -*-
# Scrapy settings for qiche project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'qiche'
SPIDER_MODULES = ['qiche.spiders']
NEWSPIDER_MODULE = 'qiche.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True #需要打开
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 3 #和下面都要打开
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3 #和上面都要打开避免封杀IP
RANDOMIZE_DOWNLOAD_DELAY = True
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
# 将持久化写这里方便调用修改
MONGODB_SERVER = '180.76.154.142'
MONGODB_PORT = 27017
MONGODB_DB = 'qiche'
MONGODB_COLLECTION = 'car'
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'qiche.middlewares.QicheSpiderMiddleware': 543, #如果在middle中设置了隐藏ip就需要打开这里
}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'qiche.middlewares.QicheDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qiche.pipelines.QichePipeline': 300,# 持久化处理需要打开
}
LOG_LEVEL = 'DEBUG'
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True # 固定需要打开
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
XPATH用法
直接在浏览器中选中然后复制,so easy嘛~!
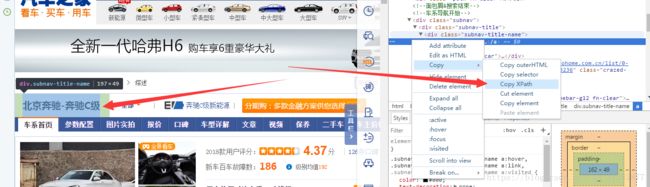
最后在后面写入extract,否则不能提取出来
调试bug
在scrapy中可以用shell调试所截取的内容是否截取到
安装
pip install pypiwin32
查看链接
然后scrapy shell url
查看网页是否连接上了
如果返回200表示成功接下来就可以调试了
xpath是否生效
犹豫无法查看是否写正确,可以在这里调试
xel.xpath(‘xxxxxxxx’)

弱引用
如果在写程序的时候遇到类方法相互调用不能直接写a=b,b=a
这样会导致内存无法释放,因此需要用到weakref
循环引用容易导致内存无法释放
可以用弱引用weakref.ref
import weakref
import gc
class A
class B
while True:
a = A()
b = B()
a.mgr = b
#正确
b.dept = weakref.ref(a)
print(gc.garbage)# 查看状态
del a
del b
print(gc.garbage)