YOLO v3算法详解
论文地址:YOLOv3: An Incremental Improvement
YOLO算法详解,YOLO v2算法详解
1.The Deal
接下来,从头梳理整个网络,如果对YOLO和YOLO v2不熟悉,可以看一下我之前的博客。
1.1 Bounding Box Prediction
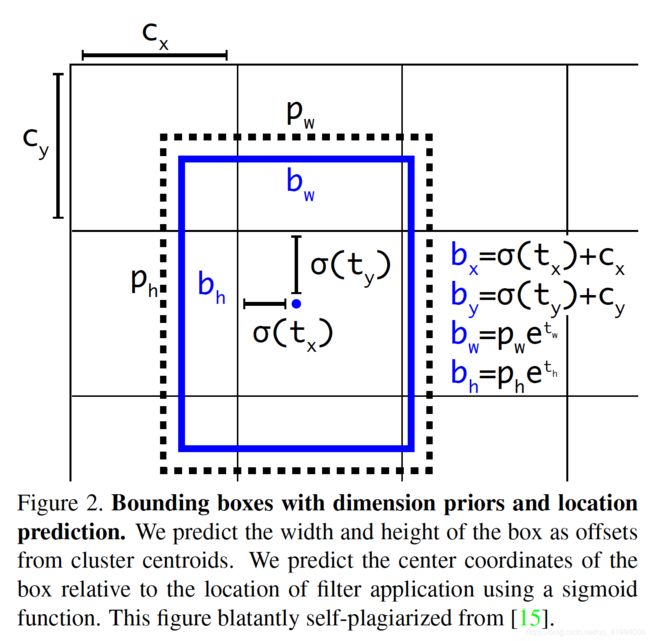
YOLO v3沿用YOLO9000预测bounding box的方法,通过尺寸聚类确定anchor box。对每个bounding box网络预测4个坐标偏移![]() 。如果feature map某一单元偏移图片左上角坐标
。如果feature map某一单元偏移图片左上角坐标![]() ,bounding box预选框尺寸为
,bounding box预选框尺寸为![]() ,即anchor尺寸,那么生成对预测坐标为
,即anchor尺寸,那么生成对预测坐标为![]() ,此为feature map层级.而
,此为feature map层级.而![]() 为真值在feature map上的映射,通过预测偏移
为真值在feature map上的映射,通过预测偏移![]() 使得
使得![]() 与
与![]() 一致。
一致。
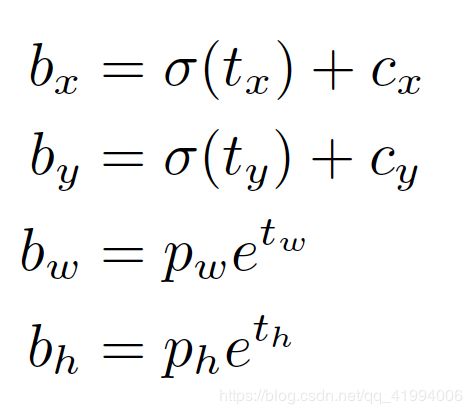
每个bounding box只对应一个目标得分,通过logistic回归计算。目标得分为1的情况:1.某个bounding box与ground truth的重合度比其他bounding box都高;2.某个bounding box与ground truth的重合度不是最大的,但是超过某个阈值(0.5)。
关于正负样本
github链接:https://github.com/eriklindernoren/PyTorch-YOLOv3
在上面链接所提的YOLOV3实现代码中,定义mask以及conf_mask,其中mask负责bbox正样本,conf_mask负责bbox负样本。过程如下:
1、mask初始化为0,conf_mask初始化为1。
2、计算bbox与gt的IOU,当大于某一阈值时,conf_mask相应位置也会设置为0。
3、对于与gt最佳匹配的bbox,mask与相应位置会设置为1,conf_mask相应位置也会设置为1。
对于mask为1的位置都为正样本,而对于conf_mask-mask为1的位置为负样本。因此gt周围大于阈值的bbox会被无视。
1.2 Class Prediction
YOLO v3中每个bounding box都预测一组类别,与YOLO v2相同,与YOLO不同,YOLO在每个网格预测![]() 个参数。作者没有使用softmax损失。当一个目标仅属于一个类时,softnax比较适合,当某一目标分属于多个类时,需要用逻辑回归对每个类做二分类。
个参数。作者没有使用softmax损失。当一个目标仅属于一个类时,softnax比较适合,当某一目标分属于多个类时,需要用逻辑回归对每个类做二分类。
1.3 Predictions Across Scales
YOLO v3中预测3中不同尺寸box,所以在COCO数据集上输出张量为![]() ,4表示4个坐标偏移,1表示包含目标得分,80表示数据集含有80个类别。
,4表示4个坐标偏移,1表示包含目标得分,80表示数据集含有80个类别。
YOLO v2中通过passthrough层增加细粒度特性。YOLO v3中对前面两层得到的feature map进行上采样2倍,将更之前得到的feature map与经过上采样得到的feature map进行连接,这种方法可以让我们获得上采样层的语义信息以及更之前层的细粒度信息,将合并得到的feature map经过几个卷积层处理最终得到一个之前层两倍大小的张量。下面以YOLO v3网络结构图举例说明,原图在之前博客——深度学习-yolov3网络结构
79个卷积层得到13*13*512特征图,经过84卷积层得到13*13*256特征图,79与84卷积层也就是前面说的前两层,得到的13*13*256特征图进行上采样得到26*26*256特征图,与更之前层,也就是61层得到的26*26*512特征图进行合并,得到26*26*768特征图,再经过几个卷积得到26*26*18张量用于预测,尺寸为前一个预测张量13*13*18的两倍。对于COCO数据集,用于检测的卷积层的卷积核个数是255不是18,3*(4+1+80)=255。

我们再次执行相同的操作,预测新的尺寸,对于COCO数据集,YOLO v3预测输出三个尺寸为:18*18*255,26*26*255,52*52*255,因此在预测52*52*255输出时,受益于所有之前的计算以及网络前期的细粒度特性。
YOLO v2有5个尺寸预选框,YOLO v3有3个尺寸预选框,但是YOLO v3有3个输出检测层,所以YOLO v3的bounding box比YOLO v2还是要多,因为(13*13+26*26+52*52)*3 > 13*13*5。
YOLO v3沿用YOLO v2通过聚类的方法获得bounding box预选框尺寸,3种尺寸9个聚类结果,在coco数据集上9个聚类结果为:
(10*13); (16*30); (33*23); (30*61); (62*45); (59*119); (116*90); (156*198); (373*326)。这应该是按照输入图像的尺寸是416*416计算得到的。
1.4 Feature Extractor
YOLO v3所使用的特征提取的新网络集成了YOLO v2中网络 Darknet-19和新流行的残差网络(ResNet的residual结构)。该网络大量使用3*3与1*1卷积层依次连接的形式,并且添加了shortcut连接,所以其网络结构比复杂,有53个卷积层,因此YOLO v3特征提取网络称作Darknet-53.结构如下图:
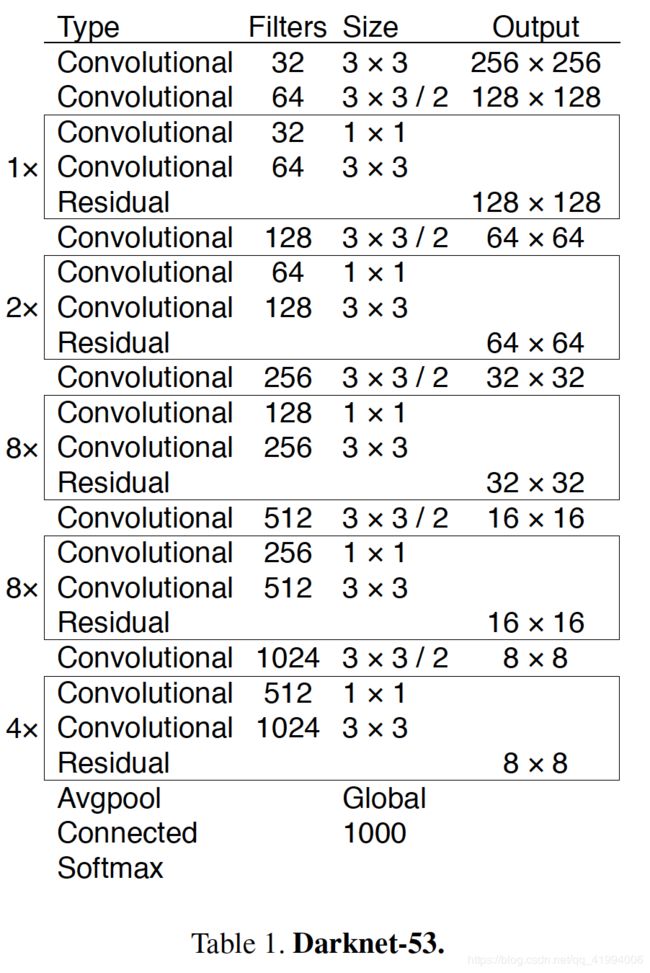
Darknet-53只是特征提取层,源码中只使用了pooling层前面的卷积层来提取特征,因此multi-scale的特征融合和预测支路并没有在该网络结构中体现。
表二为Darknet-53与其他几个网络在ImageNet数据集上效果对比。可以看出 Darknet-53与ResNet-152效果差不多,但是速度快2倍。

1.5 Training
训练过程中作者使用多尺寸,数据增强,BN层等常规操作。
2. 实验结果
YOLO v3在COCO数据集上训练结果与其他检测算法比较如表3。原来YOLO v2对于小目标的检测效果是比较差的,通过引入多尺度特征融合的方式,可以看出YOLO v3的APS要比YOLO v2的APS高出不少。

图三为各个模型在COCO数据集上mAP及速度比较。YOLO v3速度快,准确性高。在coco数据集上,在AP50评估标准上效果不错,但在AP between .5 and .95评估标准上,效果一般。

3. ThingsWe Tried That Didn’t Work
1. 将box宽度与高度与x,y偏移建立线性关系,发现模型不稳定。
2. x,y偏移用线性激活而非logistic激活函数,导致mAP下降。
3.Focal loss,导致mAP下降。
4. 两个IOU阈值设置。 Faster RCNN中,bounding box与ground truth的IOU大于0.7为正样本,小于0.3为负样本。作者使用同样的方法,但是效果并不好。