利用Python+matplotlib对泰坦尼克号进行数据分析
主要分析有
- 数据接:https://pan.baidu.com/s/1jn88GiOr7uWA8BDQocFXxg 密码: s0e0
- 不同舱位等级中幸存者和遇难者的乘客比例
- 不同性别的幸存比例
- 幸存和遇难旅客的票价分布
- 幸存和遇难乘客的年龄分布
- 不同上船港口的乘客仓位等级分布
- 幸存和遇难乘客堂兄弟姐妹的数量分布
- 幸存和遇难旅客父母子女的数量分布
- 单独乘船与否和幸存之间有没有联系
- 是否成年男性和幸存之间有没有联系
数据接:https://pan.baidu.com/s/1jn88GiOr7uWA8BDQocFXxg 密码: s0e0
首先做准备(导入库,读入数据集)
import matplotlib.pyplot as plt
import seaborn as sns
# data = pd.read_csv('titanic.csv')
# print(data.head())
data = sns.load_dataset("titanic", data_home="titanic")
不同舱位等级中幸存者和遇难者的乘客比例
classes = []
survived_s = [[], []]
for pclass, items in data.groupby(by=['class']):
classes.append(pclass)
count0 = items[items['survived'] == 0]['survived'].count()
count1 = items[items['survived'] == 1]['survived'].count()
survived_s[0].append(count0)
survived_s[1].append(count1)
# 绘制图形
plt.bar(classes, survived_s[0], color='r', width=0.3)
plt.bar(classes, survived_s[1], bottom=survived_s[0], color='g', width=0.3)
# 添加文字
for i, pclass in enumerate(classes):
totals = survived_s[0][i] + survived_s[1][i]
plt.text(pclass, survived_s[0][i] // 2, '%.2f%%' % ((survived_s[0][i]) / totals * 100), ha='center')
plt.text(pclass, survived_s[0][i] + survived_s[1][i] // 2, '%.2f%%' % ((survived_s[1][i]) / totals * 100),
ha='center')
plt.xticks(classes, classes)
plt.ylim([0, 600])
plt.legend(['die', 'survive'], loc='upper right')
plt.grid(axis='y', color='gray', linestyle=':', linewidth=2)
plt.xlabel("class")
plt.ylabel("number")
plt.show()
绘图效果:

从绘图结果来看:舱位级别越高,死亡人数越少。
不同性别的幸存比例
temp = data.groupby(by=['survived', 'sex']).count()
# 非幸存者 女性
t1 = temp.loc[0, :].loc['female', :].max()
# 非幸存者 男性
t2 = temp.loc[0, :].loc['male', :].max()
# 幸存者 女性
t3 = temp.loc[1, :].loc['female', :].max()
# 非幸存者 男性
t4 = temp.loc[1, :].loc['male', :].max()
sexs = ['female', 'male']
plt.bar(sexs, [t1, t2], color='r', width=0.3)
plt.bar(sexs, [t3, t4], bottom=[t1, t2], color='g', width=0.3)
survived = {'female': [t1, t3], 'male': [t2, t4]}
for i, pclass in enumerate(sexs):
total = sum(survived[pclass])
plt.text(pclass, survived[pclass][0] // 2, '%.2f%%' % ((survived[pclass][0] / total) * 100), ha='center')
plt.text(pclass, survived[pclass][0] + survived[pclass][1] // 2, '%.2f%%' % ((survived[pclass][1] / total) * 100),
ha='center')
plt.xticks(sexs, sexs)
plt.ylim([0, 600])
plt.legend(['die', 'survive'], loc='upper left')
plt.grid(axis='y', color='gray', linestyle=':', linewidth=2)
plt.show()
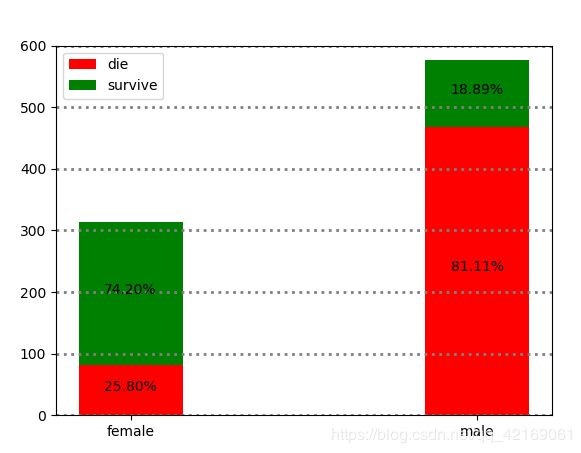
从绘图结果来看:女性生存的几率的较高。
幸存和遇难旅客的票价分布
survived_s = []
fares = []
for survived, item in data.groupby(by=['survived']):
# print(survived)
survived_s.append(survived)
fares.append(item['fare'])
str_sur = ['die', 'survived']
plt.boxplot(x=fares, patch_artist=True, labels=str_sur, showmeans=True,
medianprops={'linestyle': '--', 'color': 'orange'})
plt.show()

从绘图结果来看:从盒形图来看,存活下来的人票价较高与死亡的人。
幸存和遇难乘客的年龄分布
survived_s = []
fares = []
# 删除年龄为NaN的行数据
temp = data.dropna(subset=['age'], how='any')
for survived, items in temp.groupby(by=['survived']):
survived_s.append(survived)
fares.append(items['age'])
str_sur = ['die', 'survived']
plt.ylabel("numbers")
plt.title("survived and die about age")
plt.boxplot(x=fares, patch_artist=True, labels=str_sur, showmeans=True,
medianprops={'linestyle': '--', 'color': 'orange'})
plt.show()
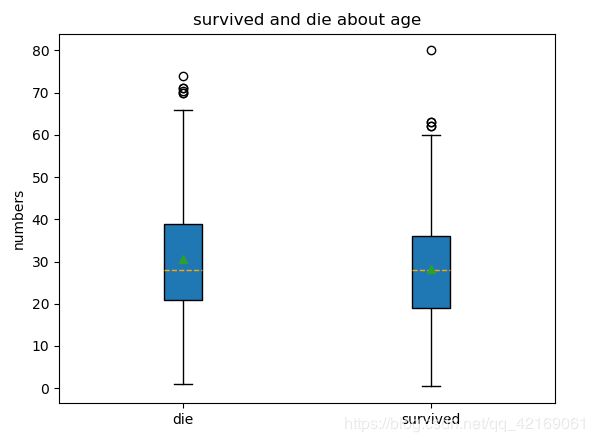
从绘图结果来看:幸存者与死亡者的年龄分布基本相同。
不同上船港口的乘客仓位等级分布
embarkeds = []
pclasses = []
# print(data['embarked'].drop_duplicates())
for embarked, items in data.groupby(by=['embarked']):
embarkeds.append(embarked)
p_class_s = []
for p_class, values in items.groupby(by=['class']):
p_class_s.append(values['class'].count())
pclasses.append(p_class_s)
x = np.array(range(len(embarkeds)))
plt.bar(x - 0.25, [i[0] for i in pclasses], width=0.2, color='r')
plt.bar(x, [i[1] for i in pclasses], width=0.2, color='g')
plt.bar(x + 0.25, [i[2] for i in pclasses], width=0.2, color='b')
for i, val in enumerate(x):
item = pclasses[i]
plt.text(val - 0.25, item[0] + 5, '%s' % item[0], ha='center')
plt.text(val, item[1] + 5, '%s' % item[1], ha='center')
plt.text(val + 0.25, item[2] + 5, '%s' % item[2], ha='center')
plt.xticks(x, embarkeds)
plt.legend(['First', 'Second', 'Third'])
plt.grid(axis='y', color='gray', linestyle=':')
plt.xlabel("embarked")
plt.ylabel("class")
plt.show()

从绘图结果来看:其中C、Q、S代表三个港口,总体来看,S港口中人数最多、C次之、Q最少,其中S港口中三等舱最多、二等舱次之、一等舱最少,C港口中一等舱最多,三等舱次之,二等舱最少,Q港口中,三等舱最多,二等舱次之,一等舱最少。
幸存和遇难乘客堂兄弟姐妹的数量分布
sibsps = []
survived = []
for survive, items in data.groupby(by=['survived']):
survived.append(survive)
sibsps.append(items['sibsp'])
plt.boxplot(x=sibsps, patch_artist=True, labels=survived, showmeans=True,
meanprops={'linestyle': '--', 'color': 'orange'})
plt.xlabel('survived')
plt.ylabel('sibsp')
plt.show()

从绘图结果来看:幸存和死亡人数中是否为堂兄姐妹人数相当,但在死亡人数中有一个最高点八人均为堂兄姐妹。
幸存和遇难旅客父母子女的数量分布
sibsps = []
survived = []
for survive, items in data.groupby(by=['survived']):
survived.append(survive)
sibsps.append(items['parch'])
plt.boxplot(x=sibsps, patch_artist=True, labels=survived, showmeans=True,
meanprops={'linestyle': '--', 'color': 'orange'})
plt.xlabel('alive')
plt.ylabel('parch')
plt.show()
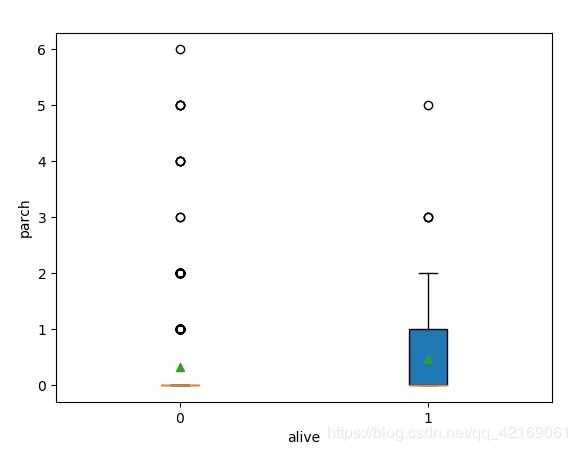
从绘图结果来看:存活人数中大多为父母子女。
单独乘船与否和幸存之间有没有联系
survived = np.array([0, 1])
temp = data.groupby(by=['alone', 'survived']).count()
# 单独上船并且没有幸存
t1 = temp.loc[False, :].loc[0, :].max()
t2 = temp.loc[False, :].loc[1, :].max()
t3 = temp.loc[True, :].loc[0, :].max()
t4 = temp.loc[True, :].loc[1, :].max()
width = 0.1
plt.bar(survived - width, [t1, t3], color='r', width=width * 2)
plt.bar(survived + width, [t2, t4], color='g', width=width * 2)
plt.xlabel('Alone')
plt.ylabel('Alive')
plt.xticks(survived, ['No Alone', 'Alone'])
plt.legend(['die', 'survive'])
plt.show()
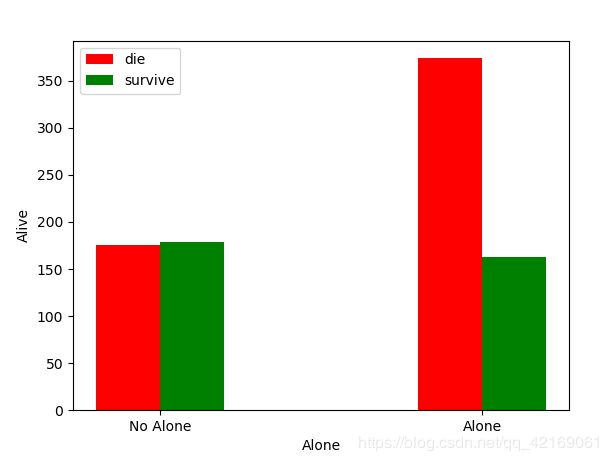
从绘图结果来看:独自上船的人占据了大多数,并且死亡占比较高,但不是独自上船中,幸存和死亡占比相当。
是否成年男性和幸存之间有没有联系
temp = data.groupby(by=['adult_male', 'alive']).count()
# 非成年死亡
t1 = temp.loc[False, :].loc['no', :].max()
# 非成年死亡
t2 = temp.loc[False, :].loc['yes', :].max()
# 非成年死亡
t3 = temp.loc[True, :].loc['no', :].max()
# 非成年死亡
t4 = temp.loc[True, :].loc['yes', :].max()
sexs = ['Not Adult', 'Adult']
plt.bar(sexs, [t1, t3], color='r', width=0.3)
plt.bar(sexs, [t2, t4], bottom=[t1, t3], color='g', width=0.3)
survived = {"Not Adult": [t1, t2], 'Adult': [t3, t4]}
for i, class_s in enumerate(sexs):
total = sum(survived[class_s])
plt.text(class_s, survived[class_s][0] // 2, '%.2f%%' % ((survived[class_s][0] / total) * 100), ha='center')
plt.text(class_s, survived[class_s][0] + survived[class_s][1] // 2,
'%.2f%%' % ((survived[class_s][1] / total) * 100), ha='center')
plt.xticks(sexs, sexs)
plt.ylim([0, 600])
plt.legend(['die', 'survive'], loc='upper left')
plt.grid(axis='y', color='gray', linestyle=':', linewidth=2)
plt.show()
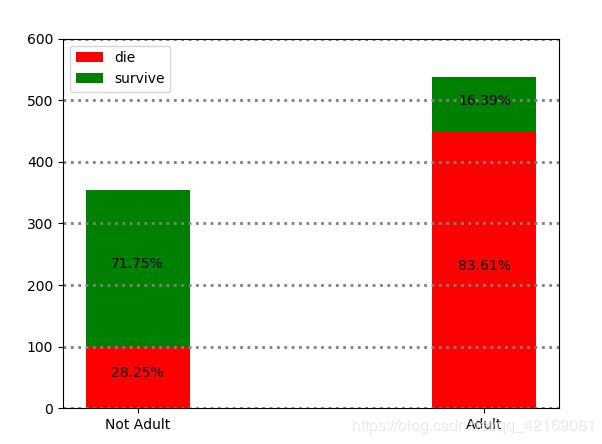
从绘图结果来看:未成年人占比较低但存活率叫成年人高。