爬虫笔记整理1 - 基础原理总结
2.0 网络框架
to be continued
2.1 HTTP基本原理
1 简介
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML©页面的方法。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。在2015年已推出HTTP/2版本,并被主要的web浏览器和web服务容器支持。但目前使用最广泛的还是HTTP/1.1版本。
HTTP协议的主要特点可概括如下:
1)支持客户/服务器模式(request/response模式)。
2)简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、POST、HEAD、OPTIONS。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3)灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4)无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
5)无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
2 URL
URL(Uniform Resource Locator,统一资源定位符)是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
HTTP 是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式,HTTP1.1版本中给出一种持续连接的机制,绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。
HTTP URL (URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息)的
格式如下:
http://host[":“port][abs_path]?参数A=value1&参数2=value2
或
https://host[”:"port][abs_path] ?参数A=value1&参数2=value2
http表示要通过HTTP协议来定位网络资源;host表示合法的Internet主机域名或者IP地址;port指定一个端口号,为空则使用缺省端口80(https是443);abs_path指定请求资源的URI;如果URL中没有给出abs_path,那么当它作为请求URI时,必须以“/”的形式给出,通常这个工作浏览器自动帮我们完成。
eg:
a)输入:www.guet.edu.cn
浏览器自动转换成:http://www.guet.edu.cn/
b)http:192.168.0.116:8080/index.jsp
3 http请求
http请求由三部分组成,分别是:请求行、消息报头、请求正文
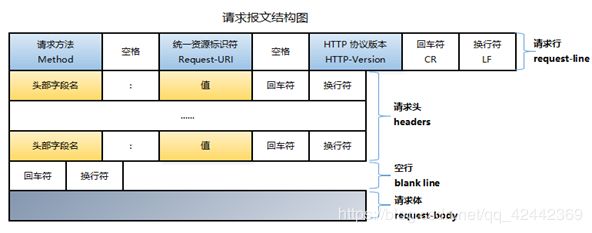
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:Method Request-URI HTTP-Version CRLF
其中 Method表示请求方法;Request-URI是一个统一资源标识符;HTTP-Version表示请求的HTTP协议版本;CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
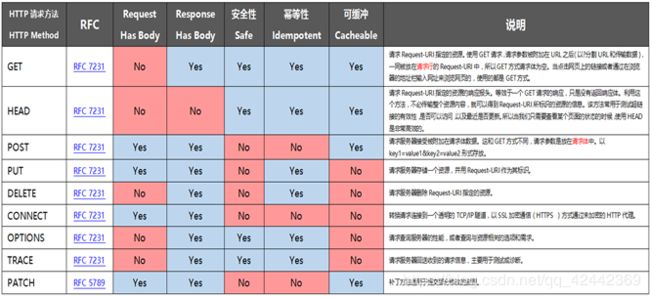
关于HTTP请求GET和POST的区别
(1) 提交形式:
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456.
POST方法是把提交的数据放在HTTP包的Body中.
(2) 传输数据的大小:
HTTP协议本身没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。 而在实际开发中存在的限制主要有:
GET: 特定浏览器和服务器对URL长度有限制,例如IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
因此对于GET提交时,传输数据就会受到URL长度的限制。
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
(3) 安全性:
POST的安全性要比GET的安全性高,具有真正的Security的含义。而且通过GET提交数据,用户名和密码将明文出现在URL上,因为登录页面有可能被浏览器缓存,其他用户浏览历史纪录就可以拿到账号和密码了。
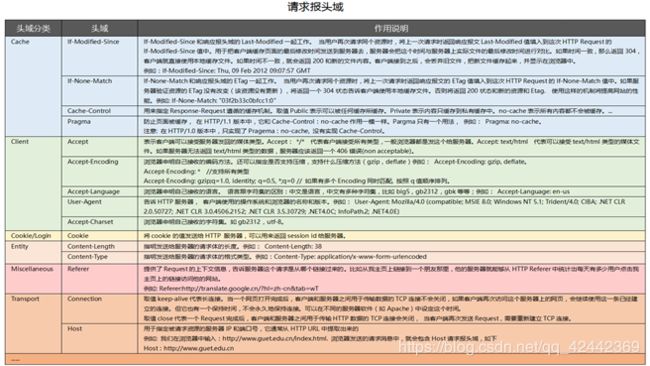
请求头
4 http响应
在接收和解释请求消息后,服务器返回一个HTTP响应消息。
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
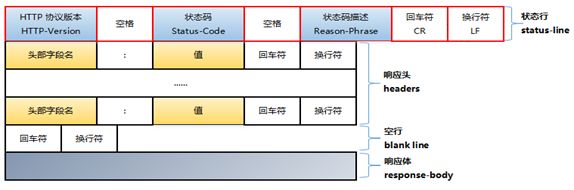
状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
eg:HTTP/1.1 200 OK (CRLF)
状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
eg:HTTP/1.1 200 OK (CRLF)
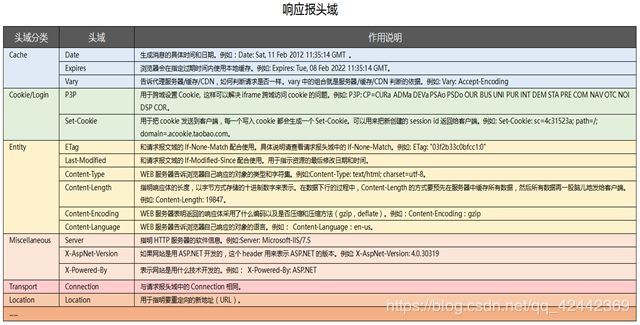
响应报头域
5 案例
利用python自带的库模拟http请求,为以后利用python做API测试做准备。只讲述模拟http的过程,具体到自己用的时候,要以自己的应用为准做出适当的调整。
http是一个包,里面含有多个模块:http.client,http.server,http.cookies,http.cookiejar。
客户端:
Get请求
import http.client
conn = http.client.HTTPSConnection("www.python.org")
conn.request("GET", "/")
r1 = conn.getresponse()
print(r1.status, r1.reason)
data1 = r1.read() # This will return entire content.
# The following example demonstrates reading data in chunks.
conn.request("GET", "/")
r1 = conn.getresponse()
while not r1.isclosed():
print(r1.read(200)) # 200 bytes
# Example of an invalid request
conn.request("GET", "/parrot.spam")
r2 = conn.getresponse()
print(r2.status, r2.reason)
data2 = r2.read()
conn.close()
Post请求
import http.client, urllib.parse
params = urllib.parse.urlencode({'@number': 12524, '@type': 'issue', '@action': 'show'})
headers = {"Content-type": "application/x-www-form-urlencoded",
"Accept": "text/plain"}
conn = http.client.HTTPConnection("bugs.python.org")
conn.request("POST", "", params, headers)
response = conn.getresponse()
print(response.status, response.reason)
data = response.read()
print(data)
conn.close()
2.2 网页基础(HTML + CSS + JavaScript)
另辟博文分类
2.3 爬虫的基本原理
一、 爬虫原理/基础/入门
1、 什么是爬虫
请求网站,并提取数据的自动化程序
2、 爬虫工作流程
第一步:发起请求。一般是通过HTTP库,对目标站点进行请求。等同于自己打开浏览器,输入网址。
第二步: 获取响应内容(response)。如果请求的内容存在于服务器上,那么服务器会返回请求的内容,一般为:HTML,二进制文件(视频,音频),文档,Json字符串等。
第三步:解析内容。对于用户而言,就是寻找自己需要的信息。对于Python爬虫而言,就是利用正则表达式或者其他库提取目标信息。
第四步:保存数据。解析得到的数据可以多种形式,如文本,音频,视频保存在本地。
3、 请求与响应
4、 爬虫与反爬虫

二、 开发工具
Charles
Chrome、firefox等浏览器
Pycharm
三、 Python爬虫基础篇
1、 Urllib库使用详解与项目实战
Urllib库的基本使用
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url 解析模块
urllib.robotparser 解析robots.txt协议模块
使用 urllib 抓取http://www.luoo.net 落网歌曲信息,并用正则表达式提取相关文本数据,保存成TXT文本文件
2、 Urllib3库的使用
第三方库,最终也是使用python自带的http模块发送数据包给服务器
requests使用了urllib3
pip也使用了urllib3
多次请求中可重复利用同一socket连接,应用了keepalive特性,减少TCP握手次数和慢启动次数
支持File传输
内置重定向和重试
支持gzip和deflate解码
线程安全
支持代理
3、 Requests库安装使用与项目实战
to be continued
4、 Pyquery解析库详解与基本使用
to be continued
5、 BeautifulSoup解析库安装使用
to be continued
四、 Python爬虫进阶篇
破解反爬技术
1、 JS渲染与参数加密
to be continued
2、 模拟浏览器
Selenium(webdriver)
Phantomjs
3、 Pyexecjs引擎解析JS
4、 验证码识别
图形验证码识别
极验验证码识别
点触验证码识别
微博宫格验证码识别
打码平台对接
5、 IP代理池实现
to be continued
6、 pyspider框架
to be continued
7、 APP的抓取
to be continued
8、 Scrapy框架
to be continued
9、 分布式爬虫
to be continued
10、 分布式爬虫部署
to be continued
笔记:
1、http的无连接&长连接
客户端每次请求都会新建一个连接,发送请求到服务器,服务器返回一个响应,确定客户端接收,服务器就会断开连接
优点:会释放 服务器的资源占用,节省服务器资源
缺点:每次请求都会建立新的连接,效率会比较低,频繁的建立连接会耽误时间
http1.1
进行了修改
Connection: keep-alive
当设置 request 的headers 中 connection 为 keep-alive 时,保持一个长连接(会有一个超时时间,很多都是30分钟)
2、http的无状态
服务器不记录客户端的任何信息,每次客户端发送请求时,服务器都当做是一个新的客户端
http1.1
在服务器中,引入一个 session 对象,保存当前连接的所有需要保存的信息
服务器通过 返回的响应中, 进行 Set-Cookie: session_id=142678abc245;
客户端接收到服务器的 set-cookie 时,就知道,需要保存这个 cookie的值, 保存到硬盘中
下次客户端继续访问同一个网站时,
传递参数 Cookie:session_id=142678abc245 给服务器
服务器就会检测这个 session_id=142678abc245
如果没有检测到 这个 session_id ,那么就会把 客户端当做一个全新的请求
如果检测到了这个 session_id ,那么服务器就把之前对应的信息全部提取出来,并且可以识别出客户端是之前进行过通信的对象
cookie 是有时效的
3、http的url
https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E8%BD%AF%E7%9B%98&oq=%25E5%2588%2580%25E7%2589%2587%25E6%259C%258D%25E5%258A%25A1%25E5%2599%25A8&rsv_pq=ba85e6d50000ce3d&rsv_t=cfaafeb5t1CbvRz%2FCY%2FY3dVGug%2F3KgZjBZKNl9aknSocSGhtzmaDODpzgUA&rqlang=cn&rsv_enter=1&inputT=3972&rsv_sug3=17&rsv_sug1=33&rsv_sug7=101&bs=%E5%88%80%E7%89%87%E6%9C%8D%E5%8A%A1%E5%99%A8
https: 协议, 两种: http和https
:// : 固定分隔符, 分割 协议 和 域
www.baidu.com: 域,或者是 ip:port
/s : 路径 path
? : 固定分隔符,分割 路径 和 参数
ie=utf-8&f=3 : 参数
补充:
# : 锚点, 用于前端网页定位到一个特定的 位置
4、域名的分级
baidu.com : 一级域名、顶级域名
www.baidu.com : 二级域名, 比较特殊, 和 顶级域名对应同一个应用
index.baidu.com : 二级域名
image.baidu.com : 二级域名
test.image.baidu.com : 三级域名
5、http request的 headers:
Host: passport.tianya.cn # 域, 不用处理
Connection: keep-alive # 保持长连接
Content-Length: 424 # 请求的字节长度, 不用处理
Cache-Control: max-age=0 # 缓存, 不用处理
Origin: https://passport.tianya.cn # 来源网址, 不用理会
Upgrade-Insecure-Requests: 1 # 不用理会
Content-Type: application/x-www-form-urlencoded # 内容 类型
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36 # 客户端的 系统和浏览器版本
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 # 通知服务器,客户端接收的内容格式
Referer: https://passport.tianya.cn/m/login.jsp # 上一个url地址,
Accept-Encoding: gzip, deflate, br # 通知服务器,客户端支持的压缩格式, response 如果发现不管怎么处理都是乱码的话,
Accept-Language: zh-CN,zh;q=0.9 # 语言, 固定写法
Cookie: time=ct=1542961667.772; # cookie值, 通知服务器我是谁
需要关注的headers:
五大常用的headers:
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
Accept: text/html, */*
Accept-Encoding: gzip, deflate, br # 一般都需要发送这个header,但是如果服务器真的返回 压缩数据给我们,就去掉
Accept-Language: zh-CN,zh;q=0.9
重要,但不是每个请求都发送到:
Referer: https://passport.tianya.cn/m/login.jsp
Cookie: time=ct=1542961667.772;
6、 http request的 请求体
GET 请求是没有 请求体的!
常见的几种:
1、form : vwriter=mumuloveshine&action=b41 # form表单数据, key=value&key1=value 这样的格式
2、json : {'key': 'value', 'key1': 111} # json字符串
3、file :
zkS5V1qKkWmpsl+6jqxawKIbmPJkBvKMHPr1Xc0T2AF302CyDY3wkICQCxweS6kb
------WebKitFormBoundarygP5khbKIQx6S9Bk4
Content-Disposition: form-data; name="filename"; filename="hehua.jpg"
Content-Type: application/octet-stream
����
# 类似这样的格式,相对使用会比较少
7、 http response 的headers
需要关注的:
Set-Cookie : 最重要的,获取cookie, 但是一般不需要手动处理,网络请求库都会自动处理
Accept-Encoding: gzip # 服务器通知客户端, 内容的压缩格式
8、响应中,最需要关注的是 响应体
常见的:
1、html: html网页内容
2、json: json字符串
3、js: js文件,有些数据会藏在JS文件中,但是很少
4、图片: 除非是下载图片,保存到文件, 或者 验证码,需要识别图片内容
9、并发
同时发生
多进程:
是真实的同时发生,但是能够同时进行几个进程,取决于服务器的 cpu 的核数
多线程:
依附于 进程存在
由于 GIL 的存在, 是一个伪多线程
GIL 全局解释器锁
CPU密集型: 大量的CPU操作的程序, 多线程没意义,甚至会降低速度!
IO密集型: 大量的IO操作的程序, 多线程是有意义的, 爬虫直接使用 多线程
协程 :
微线程
依附于 线程 存在
我们自己编写的python程序控制 需要并发的代码之间的 执行顺序
10、 python 中的 http 库
所有的网络请求库,除了 aiohttp(协程实现并发访问), 其他的最后都调用的 http 库进行网络请求
11、request 中 headers
headers
Referer: 上一个url地址, 抓取浏览器提交的参数, 程序也提交一样的参数
UserAgent : 模拟浏览器的, 设置多个useragent,每次随机提交
cookie : 一般都是用于需要登录的网页, 争取和浏览器提交一样的cookie
IP被封 : 单位时间内,请求数超过 阈值 ,就会拒绝该 IP 的后续请求, 更换IP 即可解决
验证码 : 进行图片识别,提交对应的信息, 最多的是 打码平台
JS渲染 : js后台程序在后台发送请求,获取数据,并且将数据显示在前端网页上,
找到这个js发送的http请求,发送同样的请求,就可以得到想要的信息了
接口加密与JS混淆:
最复杂的部分,需要js功底比较深厚,要求能够看懂js加密算法,并且使用python实现同样的加密算法
数据混淆
在隐藏的地方查找相应数据
行为分析
必须分析出服务器的分析规则,实现和普通用户一样的行为,最后获取数据
尽量不要有固定的参数
12、 urllib、 urllib2、 urllib3
urllib: py2和py3 都有, python官方一个网络请求库
urllib2: py2 特有的库, py3已经没有了
urllib3: 非官方的,是第三方的网络请求库, 比较完善的库(requests、pip 使用urllib3)
13、robots.txt
网站设置的允许爬虫访问的资源
User-agent: Baiduspider # 爬虫对象
Disallow: /baidu # 不允许访问的 路径
allow: /imgs # 允许访问的 路径
User-agent: * # 所有其他爬虫
Disallow: / # 禁止爬所有资源
14、urllib库
基本不会直接使用该库做网络请求
如果出现调用,也是最简单的(一行代码搞定的网络请求):
from urllib import request
text = request.urlopen(r'http://www.baidu.com').read().decode()
使用频率最高的是 urllib 中的 parse 模块
3个方法:
quote
unquote
urlencode
15、 http协议中编码集
request 的 请求行、请求头、 允许的 编码集是 ISO-8859-1
16、代理
机器A 访问 机器B, 机器B是可以查看到 机器A的 ip地址
机器A 访问 代理E ,通过 代理E 再访问 机器B, 那么 机器B 查看到的来访IP就是 代理E 的ip
项目:
使用 urllib3 访问任意的 10个 网页,
并且通过 re 获取 想要的数据,进行打印
2.4 会话和cookies
to be continued
2.5 代理的基本原理
to be continued