Java poi操作word及部分源码解析(笔记)
Java poi操作word
前两天做项目写到了一点点关于Java POI操作word的相关内容,今天做一个小总结,poi功能很强大。
目录
- Java poi操作word
- Java读取doc文档
- Java操作Docx
- 总结
Java读取doc文档
doc文档是office 97-03版本的word文档,07年之后是docx格式,旧版本poi支持二进制文件格式,比如doc、xls、ppt等类型文件,自从poi3.5起,POI支持新版本的OOXML文件格式,比如docx、xlsx、pptx等文件。所以笔者使用的是旧版本poi,3.17版本。
先来看看读取并打印doc文档内容的代码,很简单。
public void readAndPrintDoc() throws IOException {
WordExtractor wordExtractor = new WordExtractor(new FileInputStream(new File("doc文件地址")));
String text = wordExtractor.getText();
System.out.println(text);
}
很简单是吧,这里笔者采用的WordExtractor类来操作文档,还有另一种方法,一会儿再谈,先让我们来深入了解一下WordExtractor类。
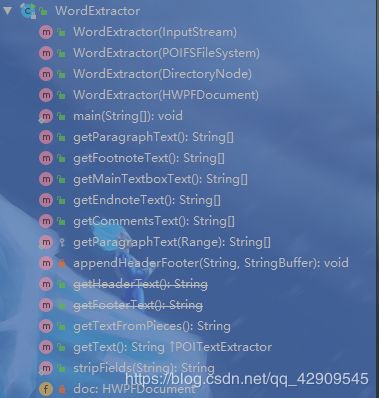
上图是WordExtractor的主要方法,我也懒得打字,就在idea中截图,将就看吧。
前四个是方法是构造方法,可以看到有不同的参数,实质上都是给最下面的HWPFDocument类型参数doc进行赋值,之前提到的另一种操作doc文档的方法也是通过HWPFDocument类进行操作的,那是后话,现在属性doc已经通过构造方法赋完值了,我挑几个方法贴出来看看吧。
main()方法忽略,其实就是通过传进去的数组进行查找word文档,然后把文档中的内容全部输出。代码就不放上来了,很简单,调用如下。
String[] strings = {文档地址};//这是一个数组,源码里通过这个数组的第一位定义到文件地址,所以只填一个就行
WordExtractor.main(strings);
getParagraphText()方法,获取所有的段落文本内容,返回一个字符串数组。
public String[] getParagraphText() {
String[] ret;
// Extract using the model code
try {
Range r = doc.getRange();
ret = getParagraphText( r );
} catch ( Exception e ) {
// Something's up with turning the text pieces into paragraphs
// Fall back to ripping out the text pieces
ret = new String[1];
ret[0] = getTextFromPieces();
}
return ret;
}
protected static String[] getParagraphText( Range r ) {
String[] ret;
ret = new String[r.numParagraphs()];
for ( int i = 0; i < ret.length; i++ ) {
Paragraph p = r.getParagraph( i );
ret[i] = p.text();
// Fix the line ending
if ( ret[i].endsWith( "\r" )) {
ret[i] = ret[i] + "\n";
}
}
return ret;
}
之前提到的另一个方法和这里有些关系,原理是一样的,都是通过HWPFDocument类来获取到Range类对象,它是HWPFDocument的核心,通过它来获取到所有的段落文本字符串,接下来就任我们操作了。
WordExtractor类进行操作获取段落
WordExtractor wordExtractor = new WordExtractor(new FileInputStream(new File("doc文件地址")));
String[] paragraphText = wordExtractor.getParagraphText();
System.out.println("文章标题:" + paragraphText[0]);
System.out.println("文章段落数:" + paragraphText.length);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < paragraphText.length; i++) {
sb.append(paragraphText[i]);
}
System.out.println(sb);
wordExtractor.close();
HWPFDocument操作
HWPFDocument document = new HWPFDocument(new FileInputStream(new File("src\\main\\resources\\templates\\sldkfj.doc")));
Range range = document.getRange();
System.out.println("文章段落数:" + range.numParagraphs());
System.out.println("文章标题:" + range.getParagraph(0).text());
StringBuilder sb = new StringBuilder();
for (int i = 0; i < range.numParagraphs(); i++) {
sb.append(range.getParagraph(i));
}
System.out.println(sb);
getText方法比较墨迹,就记住它是获取全文方法就行。HWPFDocument方法就比较复杂了,功能也更为强大,实际上WordExtractor就是对它进行了一个简单的封装,使用户获取文档内容更简单方便。
使用HWPFDocument进行一些简单操作。
HWPFDocument document = new HWPFDocument(new FileInputStream(new File(文件地址)));
Range range = document.getRange();
//书签操作
Bookmarks bookmarks = document.getBookmarks();
System.out.println("书签数量:" + bookmarks.getBookmarksCount());
for (int i = 0; i < bookmarks.getBookmarksCount(); i++) {
Bookmark bookmark = bookmarks.getBookmark(i);
System.out.println("书签" + i + "名:" + bookmark.getName());
System.out.println("开始位置:" + bookmark.getStart());
System.out.println("结束位置:" + bookmark.getEnd());
}
//表格操作
TableIterator tableIterator = new TableIterator(range);
Table table;
TableRow tableRow;
TableCell tableCell;
while (tableIterator.hasNext()) {
table = tableIterator.next();
int rowNum = table.numRows();
for (int j = 0; j < rowNum; j++) {
tableRow = table.getRow(j);
int cellNum = tableRow.numCells();
for (int k = 0; k < cellNum; k++) {
tableCell = tableRow.getCell(k);
//输出单元格的文本
System.out.println(tableCell.text().trim());
}
}
}
做一个小例子吧,写一个小表格
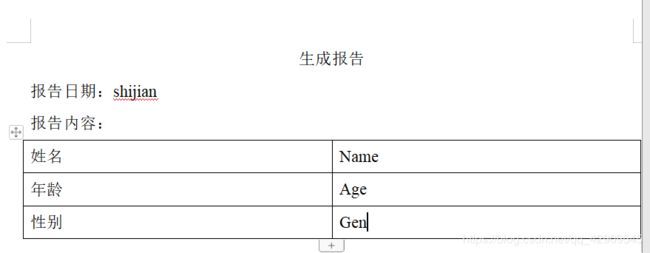
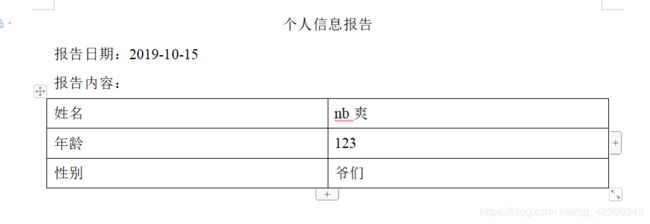
File file = new File(文件路径);
HWPFDocument doc = new HWPFDocument(new FileInputStream(file));
Range range = doc.getRange();
range.replaceText("生成", "个人信息");
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
range.replaceText("shijian",simpleDateFormat.format(new Date()));
range.replaceText("Name", "nb爽");
range.replaceText("Age", "123");
range.replaceText("Gender","爷们");
doc.write(file);
doc.close();
我想去找更多的doc的写入方法,遗憾的是,发现POI对于写入还是比较初级,不能写更复杂的word文档,不过也有一种方式去生成复杂的word文档,是将word另存为xml,然后翻译成FreeMarker模板,通过FreeMarker进行生成Doc文档,还可以通过Jacob去实现,但我还没研究,等研究后再令起一篇博客。
Java操作Docx
Docx文件的简单操作如下
//打印内容及一些信息
XWPFDocument docx = new XWPFDocument(new FileInputStream("src\\main\\resources\\templates\\sldkfj.docx"));
XWPFWordExtractor extractor = new XWPFWordExtractor(docx);
System.out.println(extractor.getText());
POIXMLProperties.CoreProperties coreProperties = extractor.getCoreProperties();
System.out.println("分类:" + coreProperties.getCategory());
System.out.println("创建者:" + coreProperties.getCreator());
System.out.println("创建时间:" + coreProperties.getCreated());
System.out.println("标题:" + coreProperties.getTitle());
docx.close();
上面是通过XWPFWordExtractor进行操作,下面通过XWPFDocument进行简单操作。打印段落,表格内容,页眉页脚。
XWPFDocument docx = new XWPFDocument(new FileInputStream(文件地址));
//段落打印
List paragraphs = docx.getParagraphs();
for (XWPFParagraph paragraph : paragraphs) {
System.out.println(paragraph.getText());
}
//获取表格
List tables = docx.getTables();
List rows;
List cells;
for (XWPFTable table : tables) {
rows = table.getRows();
for (XWPFTableRow row : rows) {
cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
System.out.println(cell.getText());
}
}
}
//页脚
List footerList = docx.getFooterList();
for (XWPFFooter xwpfFooter : footerList) {
System.out.println(xwpfFooter.getText());
}
//页眉
List headerList = docx.getHeaderList();
for (XWPFHeader xwpfHeader : headerList) {
System.out.println(xwpfHeader.getText());
}
docx.close();
写操作比doc文件能好一些,不需要先创建完doc文档再替换值,直接new一个XWPFDocument就行。
XWPFDocument document = new XWPFDocument();
XWPFParagraph paragraph = document.createParagraph();
// 具有相同属性的一个区域
XWPFRun run = paragraph.createRun();
//设置粗体
run.setBold(true);
//设置内容
run.setText("hahahahaha");
run = paragraph.createRun();
//设置红色
run.setColor("FF0000");
run.setText("red color");
//写一个表格 3*3
XWPFTable table = document.createTable(3, 3);
//新增一行
table.createRow();
List rows = table.getRows();
//表格属性
CTTblPr ctTblPr = table.getCTTbl().addNewTblPr();
//表格宽度
CTTblWidth ctTblWidth = ctTblPr.addNewTblW();
ctTblWidth.setW(BigInteger.valueOf(10000));
List cells;
XWPFTableCell cell;
int i = 0;
for (XWPFTableRow row : rows) {
//添加一单元格
row.addNewTableCell();
//行高
row.setHeight(500);
cells = row.getTableCells();
for (XWPFTableCell tableCell : cells) {
tableCell.setColor("FF0000");
//单元格属性
CTTcPr ctTcPr = tableCell.getCTTc().addNewTcPr();
ctTcPr.addNewVAlign().setVal(STVerticalJc.CENTER);
CTTblWidth ctTblWidth1 = ctTcPr.addNewTcW();
ctTblWidth1.setW(BigInteger.valueOf(1000));
tableCell.setText("第" + ++i);
}
}
FileOutputStream fileOutputStream = new FileOutputStream("D:\\writeDocx.docx");
document.write(fileOutputStream);
document.close();
fileOutputStream.close();
和doc类似的小例子

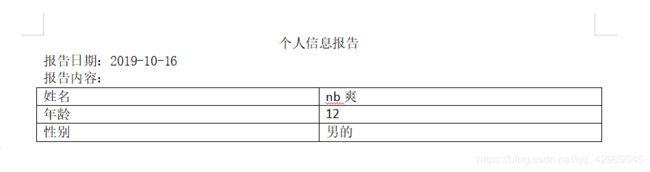
额,两次截图里的拼音就忽略了吧,其实更好的写法是使用${}这样做占位符,更清晰明了,但我这只图个方便就没用使用。
总结
洋洋洒洒也写了不少字,这里有更好的写法,但我没用,还是需要有很多改进的地方,待后续更新吧,就这样吧。