prometheus+grafana+node_exporter+alertmanager监控主机及报警
prometheus+grafana+node_exporter+alertmanager监控主机及报警
- 安装prometheus
- 安装node_exporter
- 安装grafana
- 安装alertmanager
- 参考文档
安装prometheus
- prometheus安装
各个版本的Prometheus https://prometheus.io/download/
以linux系统为例,下载编译好的二进制包,解压使用:
$ wget https://github.com/prometheus/prometheus/releases/download/v2.11.1/prometheus-2.11.1.linux-amd64.tar.gz
$ tar xzvf prometheus-2.11.1.linux-amd64.tar.gz
$ mv prometheus-2.11.1.linux-amd64 /usr/local/prometheus
- 验证安装是否成功
$ cd /usr/local/prometheus
$ ./prometheus --version
prometheus, version 2.11.1 (branch: HEAD, revision: e5b22494857deca4b806f74f6e3a6ee30c251763)
build user: root@d94406f2bb6f
build date: 20190710-13:51:17
go version: go1.12.7
- 编辑prometheus配置文件
prometheus默认配置文件在prometheus目录下,文件名为prometheus.yml,默认配置文件内容如下:
$ cat /usr/local/prometheus/prometheus.yml
# Prometheus全局配置项
global:
scrape_interval: 15s # 设定抓取数据的周期,默认为1min
evaluation_interval: 15s # 设定更新rules文件的周期,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
external_labels: # 额外的属性,会添加到拉取得数据并存到数据库中
monitor: 'codelab_monitor'
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] # 设定alertmanager和prometheus交互的接口,即alertmanager监听的ip地址和端口
# rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载
rule_files:
- "alertmanager_rules.yml"
- "prometheus_rules.yml"
# scape配置
scrape_configs:
- job_name: 'prometheus' # job_name默认写入timeseries的labels中,可以用于查询使用
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs: # 静态配置
- targets: ['localdns:9090'] # prometheus所要抓取数据的地址,即instance实例项
- 创建新用户运行prometheus,家目录为/var/lib/prometheus,用作存放prometheus的数据。
$ groupadd prometheus
$ useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus
- 创建systemd服务
$ vim /lib/systemd/system/prometheus.service
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus/data \
--web.enable-admin-api \
--web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
- 创建prometheus数据目录
$ mkdir /var/lib/prometheus/data
- 启动prometheus
$ systemctl daemon-reload
$ systemctl start prometheus
- 验证是否启动成功
默认监听端口为9090
$ systemctl status prometheus
$ netstat -lnpt|grep 9090
- 访问自带的web
prometheus自带web界面,可以查看表达式搜索结果、报警配置、prometheus配置、exporter信息等。web界面默认为 http://ip:9090。
也可以访问http://ip:9090/metrics,查看默认抓取的数据。
上面就是简单启动Prometheus,prometheus启动时还有一些启动选项。 - Prometheus相关启动选项
–config.file 指定启动的配置文件。 例: --config.file=“prometheus.yml”
–web.listen-address 指定监听ip及端口。 例:–web.listen-address=“0.0.0.0:9090”
–web.enable-admin-api 为管理控制操作启用API端点。
–web.enable-lifecycle 通过HTTP请求启用关机和重新加载。
–storage.tsdb.path 指定prometheus数据存储路径。例: --storage.tsdb.path="/data/"
–storage.tsdb.retention.time 指定Prometheus数据存储时间,默认存在15天。例:–storage.tsdb.retention.time=“24h” - 删除prometheus数据信息
控制管理 API 启用后,可以使用下面的语法来删除与某个标签匹配的所有时间序列指标:
$ curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={kubernetes_name="prometheus"}'
如果要删除一些 job 任务或者 instance 的数据指标,则可以使用下面的命令:
$ curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={job="prometheus"}'
$ curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={instance="prometheus"}'
要从 Prometheus 中删除所有的数据,可以使用如下命令:
$ curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={__name__=~".+"}'
清理某个时间段的数据(清理的时间戳区间:1557903714 到 155790395 ),用以下命令:
curl -X POST -g 'http://127.0.0.1:9090/api/v1/admin/tsdb/delete_series?start=1557903714&end=1557903954&match[]={instance="prometheus",job="prometheus"}'
不过需要注意的是上面的 API 调用并不会立即删除数据,实际数据任然还存在磁盘上,会在后面进行数据清理。
安装node_exporter
prometheus通过node_exporter提供的接口收集主机信息。
- 安装node_exporter
github上node_exporter相关文档 https://github.com/prometheus/node_exporter
各个版本的node_exporter https://github.com/prometheus/node_exporter/releases
下载编译好的二进制包,解压使用:
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
$ tar -xvf node_exporter-0.18.1.linux-amd64.tar.gz
$ mv node_exporter-0.18.1.linux-amd64 /usr/local/node_exporter
- 验证安装是否成功
$ ./node_exporter --version
node_exporter, version 0.18.1 (branch: HEAD, revision: 3db77732e925c08f675d7404a8c46466b2ece83e)
build user: root@b50852a1acba
build date: 20190604-16:41:18
go version: go1.12.5
- 创建systemd服务
$ vim /lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
- 启动node_exporter
$ systemctl daemon-reload
$ systemctl start node_exporter
- 验证是否启动成功
默认监听端口为9100
$ systemctl status node_exporter
$ netstat -lnpt|grep 9100
- prometheus.yml中加入node_exporter的配置
$ vim prometheus.yml
- job_name: node_exporter #自定义
static_configs:
- targets: ['127.0.0.1:9090']
labels:
instance: node_exporter #自定义
group: node_exporter #自定义
- 重新加载prometheus的配置
$ systemctl reload prometheus
或
$ curl -X POST http://localhost:9090/-/reload (启用了--web.enable-lifecycle选项)
- 查看是否配置成功
访问 http://127.0.0.1:9090。

点击Targets,查看添加的node信息。

访问 http://127.0.0.1:9100/metrics 查看抓取的节点信息。
安装grafana
Grafana是用于可视化大型测量数据的开源程序,它提供了强大和优雅的方式去创建、共享、浏览数据。Dashboard中显示了不同metric数据源中的数据。
grafana官网 https://grafana.com
grafana各个版本 https://grafana.com/grafana/download
- 安装grafana
以ubuntu系统安装为例:
$ wget https://dl.grafana.com/oss/release/grafana_6.3.1_amd64.deb
$ dpkg -i grafana_6.3.1_amd64.deb
- 查看是否安装成功
$ grafana-server -v
Version 6.3.1 (commit: f2fffad, branch: HEAD)
- 启动grafana
$ service grafana-server start
- 验证是否启动成功
默认监听端口为3000
$ service grafana-server status
$ netstat -lnpt|grep 3000
- 访问grafana
访问 http://127.0.0.1:3000 默认用户名和密码都为admin。

- 添加数据源
点击Data Sources。

数据源选择Prometheus。
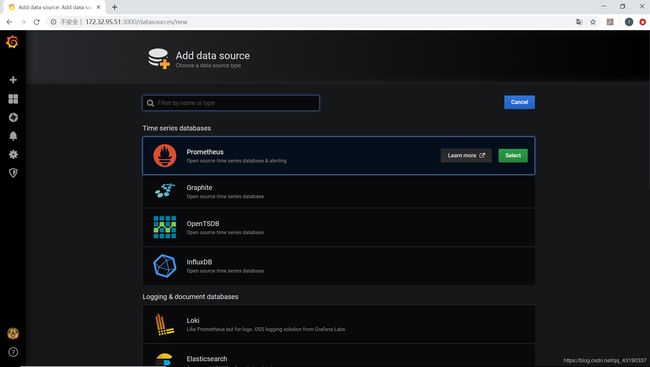
名字为Prometheus,URL为 http://localhost:9090,其他默认就可以,保存。
在Dashboards页面导入Prometheus Status模板,这里选择导入官网的模板。
点击import,可以输入模板的id,也可以上传json文件。
官网模版 https://grafana.com/grafana/dashboards
这里用405号模板,Prometheus选择Prometheus,点击import。
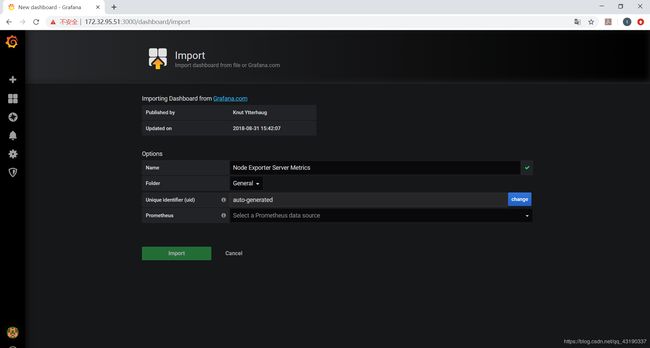
时间选择最近5分钟,此时会有数据。

根据自身需求可以导入其他模板,也可以自己做仪表盘。
一些模板需要依赖相应插件,可以去官网下载,安装说明官网文档都有记载。
官网插件下载网址 https://grafana.com/grafana/plugins
安装alertmanager
- 安装alertmanager
报警可以使用grafana自带的报警,也可以通过alertmanager实现报警。
各个版本的alertmanager https://github.com/prometheus/alertmanager/releases
下载编译好的二进制文件,解压使用:
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.18.0/alertmanager-0.18.0.linux-amd64.tar.gz
$ tar -xvf alertmanager-0.18.0.linux-amd64.tar.gz
$ mv alertmanager-0.18.0.linux-amd64 /usr/local/alertmanager
- 查看是否安装成功
$ cd /usr/local/alertmanager
$ ./alertmanager --version
alertmanager, version 0.18.0 (branch: HEAD, revision: 1ace0f76b7101cccc149d7298022df36039858ca)
build user: root@868685ed3ed0
build date: 20190708-14:31:49
go version: go1.12.6
- 修改主配置文件
主配置文件为alertmanager.yml
$ vim alertmanager.yml
# 全局配置项
global:
resolve_timeout: 5m #处理超时时间,默认为5min
smtp_smarthost: 'smtp.qq.com:587' # 邮箱smtp服务器代理
smtp_from: '******@qq.com' # 发送邮箱名称
smtp_auth_username: '******@qq.com' # 邮箱名称
smtp_auth_password: '******' # 授权码
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' # 企业微信地址
# 定义模板信息
templates:
- 'template/*.tmpl'
# 定义路由树信息
route:
group_by: ['alertname'] # 报警分组依据
group_wait: 20s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 20s # 在发送新警报前的等待时间
repeat_interval: 5m # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'email' # 发送警报的接收者的名称,以下receivers name的名称
# 定义警报接收者信息
receivers:
- name: 'email' # 警报
email_configs: # 邮箱配置
- to: '******@163.com,******@qq.com' # 接收警报的email配置,多个邮箱用“,”分隔
html: '{{ template "test.html" . }}' # 设定邮箱的内容模板
headers: { Subject: "[WARN] 报警邮件"} # 接收邮件的标题
webhook_configs: # webhook配置,不需要可以注释掉
- url: 'http://127.0.0.1:5001'
send_resolved: true
wechat_configs: # 企业微信报警配置,不需要可以注释掉
- send_resolved: true
to_party: '1' # 接收组的id
agent_id: '1000002' # (企业微信-->自定应用-->AgentId)
corp_id: '******' # 企业信息(我的企业-->CorpId[在底部])
api_secret: '******' # 企业微信(企业微信-->自定应用-->Secret)
message: '{{ template "test_wechat.html" . }}' # 发送消息模板的设定
上述配置了email、webhook和wechat三种报警方式。
注:
1)repeat_interval配置项,对于email来说,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝。
2)企业微信注册地址:https://work.weixin.qq.com
- .tmpl模板配置
- 邮件报警
$ mkdir template
$ vim template/test.tmpl
{{ define "test.html" }}
项目组
报警项
实例
报警阀值
开始时间
详情
{{ range $i, $alert := .Alerts }}
{{ index $alert.Labels "group" }}
{{ index $alert.Labels "alertname" }}
{{ index $alert.Labels "instance" }}
{{ index $alert.Annotations "value" }}
{{ $alert.StartsAt }}
{{ index $alert.Annotations "summary" }}
{{ end }}
{{ end }}
上述Labels项,表示prometheus里面的可选label项。annotation项表示报警规则中定义的annotation项的内容。
- 企业微信报警
$ vim template/test_wechat.tmpl
{{ define "cdn_live_wechat.html" }}
{{ range $i, $alert := .Alerts.Firing }}
[报警项]:{{ index $alert.Labels "alertname" }}
[实例]:{{ index $alert.Labels "instance" }}
[报警阀值]:{{ index $alert.Annotations "value" }}
[开始时间]:{{ $alert.StartsAt }}
{{ end }}
{{ end }}
此处range遍历项与email模板中略有不同,只遍历当前没有处理的报警(Firing)。此项如果不设置,则在Alert中已经Resolved的报警项,也会被发送到企业微信。
- 定义报警规则
$ cd /usr/local/prometheus
$ vim rule.yml
groups:
- name: node_status
rules:
- alert: node_status # 告警名称
expr: probe_success == 0 # 告警的判定条件,参考Prometheus高级查询来设定
for: 1m # 满足告警条件持续时间多久后,才会发送告警
labels: #标签项
status: 严重
annotations: # 解析项,详细解释告警信息
summary: "group:{{$labels.group}},instance:{{$labels.instance}} has been down "
description: "group:{{$labels.group}},instance:{{$labels.instance}} has been down "
value: "{{$value}}"
- name: CPU
rules:
- alert: CPU使用率
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[6m]))) by (instance) * 100 > 80
for: 1m
labels:
status: 一般
annotations:
summary: "group:{{$labels.group}},instance:{{$labels.instance}}:CPU使用率大于80%"
value: "{{$value}}"
报警规则可以根据自己的需求进行添加修改。
- 告警信息生命周期的3种状态
- inactive:表示当前报警信息即不是firing状态也不是pending状态。
- pending:表示在设置的阈值时间范围内被激活的。
- firing:表示超过设置的阈值时间被激活的。
- 修改prometheus配置文件
$ vim prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
rule_files:
- "rules.yml"
- 创建systemd服务
$ vim /lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target
- 启动alertmanager
$ systemctl daemon-reload
$ systemctl start alertmanager
- 验证是否启动成功
alertmanager默认监听端口为9093
$ systemct status alertmanager
$ netstat -lnpt|grep 9093
- 重新加载prometheus配置
$ systemctl reload prometheus
或
$ curl -X POST http://localhost:9090/-/reload (启用了--web.enable-lifecycle选项)
- 查看报警
访问web页面 http://127.0.0.1:9090/alerts,http://127.0.0.1:9090/rules 查看添加的报警规则。
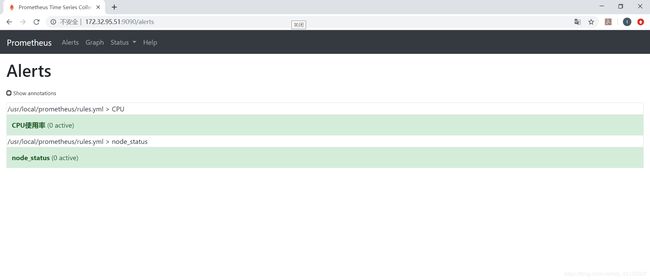

当监控的指标数值到达规定的阈值,且满足定义的报警时间后就会发送警报,在web界面也可以看到相应状态的变化。
参考文档
https://www.hi-linux.com/posts/25047.html#%E5%AE%89%E8%A3%85prometheus
https://www.qikqiak.com/post/prometheus-delete-metrics/
https://www.cnblogs.com/longcnblogs/p/9620733.html