【进阶之路】Java代码性能调优(一)
导言
大家好,我是南橘,从接触java到现在也有差不多两年时间了,两年时间,从一名连java有几种数据结构都不懂超级小白,到现在懂了一点点的进阶小白,学到了不少的东西。知识越分享越值钱,我这段时间总结(包括从别的大佬那边学习,引用)了一些平常学习和面试中的重点(自我认为),希望给大家带来一些帮助
第一件事还是把思维导图贴给大家,因为用的是免费版,所以有水印,如果需要原始版本的话,可以加我的微信:


一、字符串的优化
1、String优化
String对象是java中重要的数据类型,在大部分情况下我们都会用到String。在java语言漫长的进化过程中,开发人员也对String做了大量的优化,其中字符串的不变性和常量池复用也是String的重要特点
- 1、不变性
String类以final进行了修饰,在系统中就不可能有String的子类,同时String对象的状态在其被创建之后就不在发生变化。在一个对象被多线程共享,而且被频繁的访问时,可以省略同步和锁的时间,从而提高性能。它也保证 hash 属性值不会频繁变更,确保了唯一性,使得类似 HashMap 容器才能实现相应的 key-value 缓存功能。所以这一点也是出于对系统安全性的考虑。
- 2、常量池优化
当两个String对象拥有同一个值的时候,他们都只是引用了常量池中的同一个拷贝。所以当程序中某个字符串频繁出现时,这个优化技术就可以节省大幅度的内存空间了。
大家都知道
String a ="abc";
String b ="abc";
a == b
既然如此,那为什么在String中还存在“+”之类的操作呢?
2、字符串拼接
String通过+号来拼接字符串的时候,如果有字符串变量参与,实际上底层会转成通过StringBuilder的append( )方法来实现。

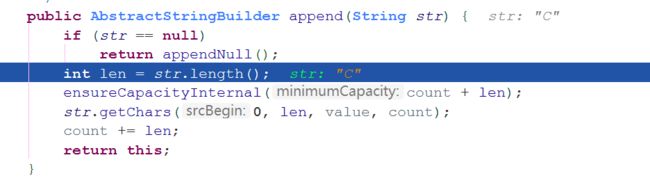
我们再继续分析"+",StringBuilder和StringBuffer的运行效率:


通过上面的例子我们可以看出,使用+号拼接字符串,其效率明显低于使用StringBuffer和StringBuilder的append()方法进行拼接。同时StringBuffer的效率比StringBuilder低些,这是由于StringBuffer实现了线程安全,效率较低也是不可避免的。所以在字符串的累加操作中,建议结合线程问题选择,应避免使用+号拼接字符串。
StringBuffer和StringBuilder的是对String的封装,String是对char数组的封装。是数组就有大小,就有不够用的时候,不够用只能扩容,也就是把原来的再复制到新的数组中。合适的容量参数自然能够减少扩容的次数,达到提高效率的目的。
3、数据类型转换
我们在开发的过程中应该知道,要尽量使用toString()方法而不是使用String.valueOf()方法进行转化。why?

从这边的代码就能看出来,String.valueOf()直接调用了底层的obj.toString()方法,不过在这之前会先判断是否为空。
所以,在大多数场景,可以直接使用toString()方法就直接使用吧。
4、intern方法
大多数情况,字符串是应用中占用内存最多的一部分。虚拟机提供了字符串池,用于存放公共的字符串。可以调用String.intern方法,返回一个字符串池中同样内容的字符串,不过这种方调用是耗时的。

JVM提供了一个新的特性,在虚拟机中添加如下参数可以开启消除重复字符串的功能:
-xx:+UseG1GC -XX:+UseStringDeduplication
JVM将尝试在垃圾收集过程中消除重复的字符串。在垃圾收集过程中,JVM会检查内存中所有的对象,识别重复字符串并尝试消除它。UseStringDeduplication不会消除重复的字符串对象本身,它只替换了底层的char[]。
5、其他字符串优化的关注点
除了之前那些比较明显的修改点,其实字符串优化中还有不少需要注意的地方。
- 1、字符串变量和字符串常量equals的时候将字符串常量写在前面
这一点很好理解,防止变量的值为空出现空指针异常。
- 2、尽量重用对象
String对象的使用,出现字符串连接时应该使用StringBuilder/StringBuffer代替。由于Java虚拟机不仅要花时间生成对象,以后可能还需要花时间对这些对象进行垃圾回收和处理,因此,生成过多的对象将会给程序的性能带来很大的影响。
- 3、字符串分割与查找
原始的String.split()方法使用简单,功能强大,支持正则表达式,但是,在性能敏感的系统中频繁的使用这个方法是不可取的。我们可以使用效率更高的StringTokenizer类分割字符串。

其中str是要分割的字符串,delim是分割符,returnDelims是否返回分隔符,默认false。
- 4、在初始化时,容量参数默认是16个字节。在构造方法中指定容量参数,减少扩容次数。
二、数字优化
1、数字装箱
Java中,将原始的数字类型转换为对应的Number对象的机制叫做装箱。将Number对象转化为对应原始类的机制叫做拆箱。在Java拆箱和装箱的机制是自动完成的。
int被装箱为Integer,在性能方面是要付出一些代价的,JDK为了避免每次int类型装箱都需要创建一个新的Integer对象,内部使用了缓存,其代码如下:

IntegerCache的cache是一个Integer数组,默认保存了int值从-128到127的所有的Integer对象。
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
其中high的值默认是127,可以通过-XX: AutoBoxCacheMax =? 进行调整。
装箱对性能的影响不是很大,但创建过多的对象会加大垃圾回收的复旦。有很多开源工具提供了避免自动装箱的int专有集合类,比如著名的开源工具Jodd,提供了IntHashMap类、IntArrayList类。
2、金额计算
浮点型变量在进行计算的时候会出现丢失精度的问题。
System.out.println(0.05+2.01); -->2.0599999999999996
进行商品价格计算的时候,出现这种问题往往会导致很严重的事物,比如下单的时候账单不正确导致无法下单,或者出现对账问题。
通常有两种办法来解决这个问题,一是用long来表示金额(以分为单位),这是效率最高的,二是使用BigDecimal来解决这类问题。
BigDecimal能保证精度,但计算会有一定的性能影响,但是差距不是特别大。所以在项目中,如果涉及精度结算,可以考虑使用BigDecimal,也可以使用long。在分布式或者微服务场景中,考虑到序列化与反序列化,long也是可以被所有的序列化框架识别的。
三、集合的优化
首先把集合的继承图摆上来。
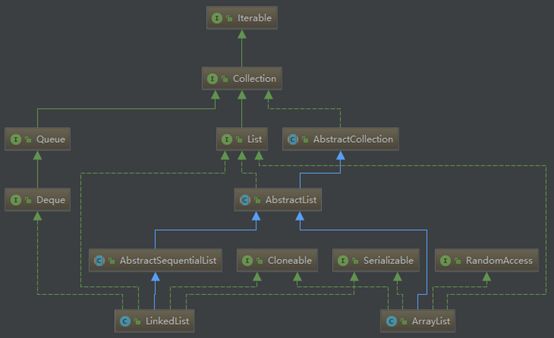
- List和Set继承自Collection接口。
- Set无序不允许元素重复。
- HashSet和TreeSet是两个主要的实现类。
- List有序且允许元素重复,支持null对象。ArrayList、LinkedList和Vector是三个主要的实现类。

- Map也属于集合系统,但和Collection接口没关系。Map是key对value的映射集合,其中key列就是一个集合。key不能重复,但是value可以重复。HashMap、TreeMap和Hashtable是三个主要的实现类。
对集合的优化,更多的其实是在适合的情况使用适合的数据结构,与字符串不同,对于集合来说,不同的数据结构之间的差异是非常巨大的。
1、ArrayList与LinkList
I、在知道初始值大小的情况下尽量赋上初始值大小。
看源码就会发现,构造具有指定初始容量的空列表事实上是初始化一个空的数组列表,拿ArrayList来说,我们都知道它的底层是用数组进行存储的,它的默认大小是10,如果没有根据预期来设置一个初始值大小,那么它就会在使用过程中不断地扩容(以下为扩容方法),每次扩容大小是1.5倍。

II、ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
III、对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
2、Map
I、HashTable和HashMap都是基于链表+数组实现的(HashMap还有红黑树)。HashTable做了同步操作,HashMap没有,因此HashMap是线程不安全类。HashTable的key和Value是不允许存Null的。HashMap的底层是native+位运算实现的,因此效率很高。
II、HashMap是无序的,LinkedHashMap是有序的,它有2种排序方式,一种是基于存储顺序,另一种是基于访问顺序。
III、TreeMap是基于红黑树实现的,平衡查找树查找效率优于平衡二叉树。它不同于LinkedHashMap,它是根据key来排序的,使用TreeMap必须实现Comparable或在构造器中注入Comparator。如果需要排序,使用TreeMap的效率更高。
3、Set
I、Set的特点就是不允许有重复元素,HashMap封装为HashSet、LinkedHashMap封装为LinkedHashSet、TreeMap封装为TreeSet。比起封装前的类,Set因为要进行比较,性能会比较明显的下降,所以如果不考虑去重情况一般不用Set。
4、RandomAccess类接口
I、随机访问接口,基于数组实现的如ArrayList和Vector都实现了此接口,而基于链表实现Linkedist未实现此接口,因此在进行随机访问操作时,链表的性能会相差几个数量级,是由于LinkedList在进行随机访问时需要依据元素所在位置而由前向后或从后向前遍历集合,而数组则直接通过索引标即可找到。
II、实现RandomAccess接口的集合比如ArrayList,应当使用最普通的for循环而不是foreach循环来遍历。
这是JDK中推荐给用户的。JDK的API对于RandomAccess接口的解释是:实现RandomAccess接口用来表明其支持快速随机访问,此接口的主要目的是允许一般的算法更改其行为,从而将其应用到随机或连续访问列表时能提供良好的性能。实际经验表明,实现RandomAccess接口的类实例,假如是随机访问的,使用普通for循环效率将高于使用foreach循环;反过来,如果是顺序访问的,则使用Iterator会效率更高。
具体情况可以参考Java语法糖1:可变长度参数以及foreach循环原理
结语
这篇文章也是这些日子对性能调优的一些思考,参杂着《Java系统性能优化实战》这本书上第二章的内容一起写了出来。在日常的编码中,很多地方的代码都存在着优化的可能,这里改一点,那里修一点,不仅代码会变得更漂亮,效率也会更高。
同时需要思维导图的话,可以联系我,毕竟知识越分享越香!
