本教程翻译自PyImageSearch英文原文
今天的博客文章是安装和使用Tesseract library 进行OCR识别的两章系列中的第一部分。
OCR可以自动对手写或者印刷字体进行类型转化为机器编码文本字符串,供我们存取和操作。
本系列第一部分将专注于在你的机器上安装和配置Tesseract,其次是利用tesseract命令实现对输入图片的OCR应用。
下一章我们将讲述如何通过Python绑定Tesseract库去实现调用Tesseract方法。
安装 Tesseract
Tesseract,最初是由Hewlett Packard在1980年代开发的,在2005年开源。2006年以后Google开始赞助这个项目。
Tesseract可以处理很多自然语音,英语、葡萄牙语系、意第绪语等。截止到2015年为止支持超过100种书面语言,并且可以通过训练学习轻松掌握其他语言。
最初Tesseract是用C语言写的,在1998年改用C++。Tesseract是无GUI交互的,可以通过命令后被执行。但是有一些其他软件提供GUI对Tesseract进行了封装。
更多Tesseract的介绍可以访问GitHub或者Wikipedia article。
这篇文章分三部分:
- 安装Tesseract
- 验证Tesseract是否正确
- 对输入图片进行OCR识别
学习完这篇文章你将学会使用Tesseract处理你的图片。
步骤1: 安装Tesseract
如果要使用Tesseract库,首先需要安装它到你的机器上。
针对macOS用户,我们使用Homebrew 去安装Tesseract:
$ brew install tesseract
如果使用Ubuntu系统,使用apt-get 安装Tesseract。
$ sudo apt-get install tesseract-ocr

对Windows,请参考 Tesseract documentation PyImageSearch不支持或者不推荐使用Windows去开发。
步骤2: 验证Tesseract是否安装成功
执行如下命令,可以验证Tesseract是否安装成功:
$ tesseract -v
tesseract 3.05.00
leptonica-1.74.1
libjpeg 8d : libpng 1.6.29 : libtiff 4.0.7 : zlib 1.2.8

如果你看到Tesseract的版本和其依赖的库的版本列表,证明你已经安装成功。
如果你安装失败:
-bash: tesseract: command not found
如果看到以上结果,证明你的机器没有安装Tesseract。请返回到步骤1重写开始。或者你需要更新你的PATH环境。
步骤 3: 使用Tesseract对图片OCR识别
我们将使用干净的预处理过的图片,以便获取更好的识别结果。
当使用Tesseract时,我建议:
- 尽可能使用高分辨率和高DPI的图片。
- 应用阈值处理从背景中分割文本。
- 确保前景色和背景色可以清晰的分开。(例如:没有像素化或字符变形)
- 应用text skew correction处理输入图片确保文字合理的对其。
如果因为如上问题导致的识别偏差,我们将在后续的章节中介绍如何处理。
现在,让我们来实现对图片的OCR识别吧:

只需要在terminal中使用如下命令即可:
$ tesseract tesseract_inputs/example_01.png stdout
Warning in pixReadMemPng: work-around: writing to a temp file
Testing Tesseract OCR
识别正确! Tesseract 非常正确的识别出, “Testing Tesseract OCR”, 并且在terminal中打印出来。
下面,我们试试另外的图片:

在Terminal中输入下面的命令,注意输入文字名的改变:
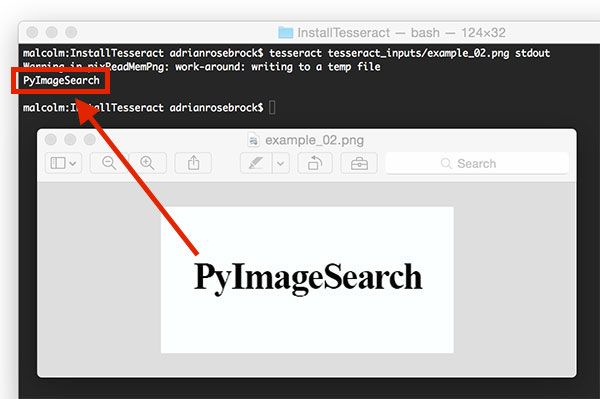
$ tesseract tesseract_inputs/example_02.png stdout
Warning in pixReadMemPng: work-around: writing to a temp file
PyImageSearch

成功!Tesseract正确识别出图片包含的文本“PyImageSearch”。
下面,让我们尝试去识别数字。

这个示例使用命令行只识别数字:
$ tesseract tesseract_inputs/example_03.png stdout digits
Warning in pixReadMemPng: work-around: writing to a temp file
650 3428
又一次,Tesseract成功识别出我们要识别的字符串(这个例子使纯数字)。
在上面的三个示例中,Tesseract都能成功的识别出我们的图片。你可以会以为Tesseract可以识别你所有的情况。
但是,我们将要在下个段落列出,Tesseract使用的局限性。
Tesseract的局限性
几周之前,我正在做的工作是通过OCR识别信用卡上面的16为数字。
我非常容易的通过python代码定位四组四位数的每一组。
以下是4位数字ROI(region of interest)的示例:

但是,当我尝试使用Tesseract去识别以下图片的时候,结果并不理想:
$ tesseract tesseract_inputs/example_04.png stdout digits
Warning in pixReadMemPng: work-around: writing to a temp file
5513
这里看到Tesseract的识别结果是 5513,但是图片显示的数字是5678。
不幸的是,这是Tesseract限制的最好的一个例子。当我们将前景文本和背景区分开后,文本的像素化特性使Tesseract混淆了。换个说法应该使Tesseract并没有对信用卡的字体进行学习训练。
Tesseract最适合在构建扫描图像,预处理图像的文档处理管道时,需要应用光学字符识别的情况。
我们应该了解Tesseract并不是一个OCR识别的现成的解决方案,不能应用所有的图片。
为了实现这个目标,我们将需要应用特征提取,机器学习和深度学习技术。
一个非常好的学习特征提取和机器学习去构建手写字体识别系统的列子可以在我的书中找到。 Practical Python and OpenCV.
本章摘要
今天我们在学习Tesseract进行OCR识别的教程的第一部分,学习到了如何在计算机上安装和配置Tesseract。并且我们使用tesseract库去识别一些图片示例。
但是,我们发现除非我们的图片非常清晰的分离的前景和背景才能被Tesseract很好的识别出结果。在有"噪点"的图片情况,我们需要获取更好的,更精确的训练模型去适应这种特别的情况。
对于具有高分辨率输入的情况,其中前景文本被干净地从背景中分割的图片,Tesseract 是最适合的。
下周我们将要学习通过Python代码,更多的与Tesseract交互,请继续关注。