高并发场景限流策略
1、什么是限流和降级
在开发高并发系统时,有很多手段来保护系统:缓存、降级、限流。
当访问量快速增长、服务可能会出现一些问题(响应超时),或者会存在非核心服务影响到核心流程的性能时, 仍然需要保证服务的可用性,即便是有损服务。
所以意味着我们在设计服务的时候,需要一些手段或者关键数据进行自动降级,或者配置人工降级的开关。
缓存的目的是提升系统访问速度和增大系统处理的容量,可以说是抗高并发流量的银弹;
降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉某些功能,等高峰后或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如秒杀、抢购;写服务(评论、下单)、频繁的复杂查询,因此需要一种手段来限制这些场景的并发/请求量。
1.1、降级
对于高可用服务的设计,有一个很重要的设计,那就是降级。降级一般有几种实现手段,自动降级和人工降级。
1. 通过配置降级开关,实现对流程的控制
2. 前置化降级开关, 基于 OpenResty+配置中心实现降级
3. 业务降级,在大促的时候,我们会有限保证核心业务的流程可用,也就是下单支付。同时,我们也会对核心的支付流程采取一些异步化的方式来提升吞吐量。
1.2、限流
限流的目的是防止恶意请求流量、恶意攻击、或者防止流量超过系统峰值限流是对资源访问做控制的一个组件或者功能,那么控制这块主要有两个功能:
限流策略和熔断策略,对于熔断策略,不同的系统有不同的熔断策略诉求,有得系统希望直接拒绝服务、有的系统希望排队等待、有的系统希望服务降级。限流服务这块有两个核心概念:资源和策略
资源:被流量控制的对象,比如接口
策略:限流策略由限流算法和可调节的参数两部份组成
限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务(定向到错误页或者告知资源没有了)、排队或等待(秒杀、下单)、降级(返回兜底数据或默认数据或默认数据,如商品详情页库存默认有货)
1.3、限流和降级
滑动窗口协议是传输层进行流控的一种措施,接收方通过通告发送方自己的窗口大小,从而控制发送方的发送速度,从而达到防止发送方发送速度过快而导致自己被淹没的目的。
简单解释下,发送和接受方都会维护一个数据帧的序列,这个序列被称作窗口。发送方的窗口大小由接受方确定,目的在于控制发送速度,以免接受方的缓存不够大,而导致溢出,同时控制流量也可以避免网络拥塞。下面图中的 4,5,6 号数据帧已经被发送出去,但是未收到关联的 ACK, 7,8,9 帧则是等待发送。可以看出发送端的窗口大小为 6,这是由接受端告知的。此时如果发送端收到 4 号 ACK,则窗口的左边缘向右收缩,窗口的右边缘则向右扩展,此时窗口就向前“滑动了”,即数据帧10 也可以被发送
动态效果演示地址 https://media.pearsoncmg.com/aw/ecs_kurose_compnetwork_7/cw/content/interactiveanimations/selective-repeat-protocol/index.html
2、限流算法
2.1、计数器算法
计数器算法是限流算法里最简单也是最容易实现的一种算法。比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,具体算法的示意图如下:

简易版实现代码:
public class CounterTest {
public long timeStamp = getNowTime();
public int reqCount = 0;
public final int limit = 100; // 时间窗口内最大请求数
public final long interval = 1000; // 时间窗口ms
public boolean grant() {
long now = getNowTime();
if (now < timeStamp + interval) {
// 在时间窗口内
reqCount++;
// 判断当前时间窗口内是否超过最大请求控制数
return reqCount <= limit;
} else {
timeStamp = now;
// 超时后重置
reqCount = 1;
return true;
}
}
public long getNowTime() {
return System.currentTimeMillis();
}
}这个算法虽然简单,但是有一个十分致命的问题,那就是临界问题,我们看下图:

从上图中我们可以看到,假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。我们刚才规定的是1分钟最多100个请求,也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
聪明的朋友可能已经看出来了,刚才的问题其实是因为我们统计的精度太低。那么如何很好地处理这个问题呢?或者说,如何将临界问题的影响降低呢?我们可以看下面的滑动窗口算法。
设置一个1s的滑动窗口,窗口有10个格子,每个格子100ms,每100ms移动一次,每次移动都记录当前服务请求的次数。内存中保存最近10次的次数(LinkedList)。格子每次移动的时候判断一次,最后一个格子和第一个格子的次数是否相差100,如果超过,则进行限流。
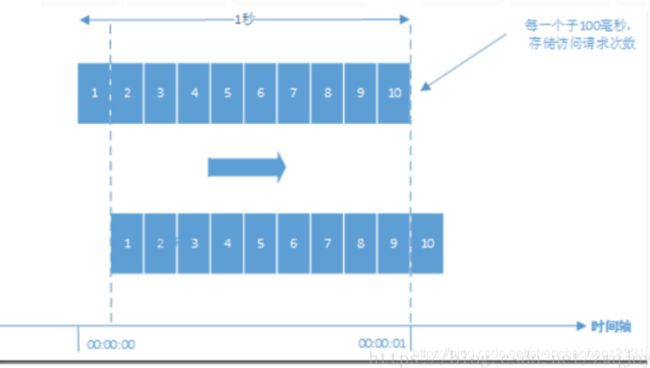
当格子划分的越多,那么滑动窗口的滚动越平滑,限流的统计就会越精确。
2.2、漏桶
漏桶算法(Leaky Bucket)是网络世界中流量整形(Traffic Shaping)或速率限制(Rate Limiting)时经常使用的一种算法,它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。
漏桶作为计量工具时,可用于流量整形和流量控制,漏桶的主要概念如下:
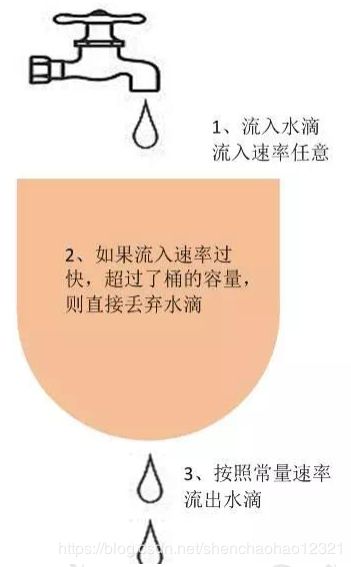
- 一个固定容量的漏桶,按照常量固定速率流出水滴(流出请求)
- 如果桶是空的,则不需流出水滴
- 可以以任意速率流入水滴到漏桶(流入请求)
- 如果流入水滴超出了桶的容量,则流入的水滴溢出了(新流入的请求被拒绝),则漏桶容量是不变的
漏桶可以看作是一个带有常量服务时间的单服务器队列,如果漏桶(包缓存)溢出,那么数据包会被丢弃。 在网络中,漏桶算法可以控制端口的流量输出速率,平滑网络上的突发流量,实现流量整形,从而为网络提供一个稳定的流量。
如图所示,把请求比作是水,水来了都先放进桶里,并以限定的速度出水,当水来得过猛而出水不够快时就会导致水直接溢出,即拒绝服务。
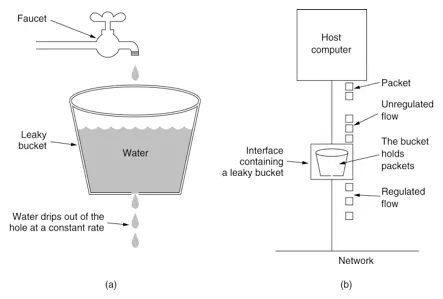
漏桶可以看做固定容量、固定流出速率的队列,漏桶限制的是请求的流出速率,漏桶中装的是请求。
因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率.因此,漏桶算法对于存在突发特性的流量来说缺乏效率。
算法实现:
public class FunnelRateLimiter {
static class Funnel {
int capacity;
float leakingRate;
int leftQuota;
long leakingTs;
public Funnel(int capacity, float leakingRate) {
this.capacity = capacity;
this.leakingRate = leakingRate;
this.leftQuota = capacity;
this.leakingTs = System.currentTimeMillis();
}
void makeSpace() {
long nowTs = System.currentTimeMillis();
long deltaTs = nowTs - leakingTs;
int deltaQuota = (int) (deltaTs * leakingRate);
if (deltaQuota < 0) { // 间隔时间太长,整数数字过大溢出
this.leftQuota = capacity;
this.leakingTs = nowTs;
return;
}
if (deltaQuota < 1) { // 腾出空间太小,最小单位是 1
return;
}
this.leftQuota += deltaQuota;
this.leakingTs = nowTs;
if (this.leftQuota > this.capacity) {
this.leftQuota = this.capacity;
}
}
boolean watering(int quota) {
makeSpace();
if (this.leftQuota >= quota) {
this.leftQuota -= quota;
return true;
}
return false;
}
}
private Map funnels = new HashMap<>();
public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate) {
String key = String.format("%s:%s", userId, actionKey);
Funnel funnel = funnels.get(key);
if (funnel == null) {
funnel = new Funnel(capacity, leakingRate);
funnels.put(key, funnel);
}
return funnel.watering(1); // 需要 1 个 quota
}
} Funnel 对象的 make_space 方法是漏斗算法的核心,其在每次灌水前都会被调用以触发漏水,给漏斗腾出空间来。能腾出多少空间取决于过去了多久以及流水的速率。Funnel 对象占据的空间大小不再和行为的频率成正比,它的空间占用是一个常量。
2.3、令牌桶算法
令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。令牌桶是一个存放固定容量令牌(token)的桶,按照固定速率往桶里添加令牌; 令牌桶算法实际上由三部分组成:两个流和一个桶,分别是令牌流、数据流和令牌桶,大概描述如下:
1)所有的请求在处理之前都需要拿到一个可用的令牌才会被处理;
2)根据限流大小,设置按照一定的速率往桶里添加令牌;
3)桶设置最大的放置令牌限制,当桶满时、新添加的令牌就被丢弃或者拒绝;
4)请求达到后首先要获取令牌桶中的令牌,拿着令牌才可以进行其他的业务逻辑,处理完业务逻辑之后,将令牌直接删除;
5)令牌桶有最低限额,当桶中的令牌达到最低限额的时候,请求处理完之后将不会删除令牌,以此保证足够的限流;
令牌桶的一个好处是可以方便的改变速度. 一旦需要提高速率,则按需提高放入桶中的令牌的速率. 一般会定时(比如100毫秒)往桶中增加一定数量的令牌, 有些变种算法则实时的计算应该增加的令牌的数量。相比漏桶算法另一个优点是能够解决突发流量。
简单实现代码:
public class TokenBucketDemo {
public long timeStamp = getNowTime();
public int capacity; // 桶的容量
public int rate; // 令牌放入速度
public int tokens; // 当前令牌数量
public boolean grant() {
long now = getNowTime();
// 先添加令牌
//min(桶的容量,当前令牌 + 上次请求获取令牌时间到当前时间内生成的令牌)
tokens = min(capacity, tokens + (now - timeStamp) * rate);
timeStamp = now;
if (tokens < 1) {
// 若不到1个令牌,则拒绝
return false;
}
else {
// 还有令牌,领取令牌
tokens -= 1;
return true;
}
}
}2.4、令牌桶和漏桶的比较
| 令牌桶 | 漏桶 | |
| 请求何时拒绝 | 固定速率往桶中添加令牌,如果桶中令牌不够,则拒绝新请求 | 流入请求速率任意,常量固定速率流出请求。当流入请求数积累到漏桶容量时,则拒绝新请求 |
| 速率限制 | 限制平均流入速率,允许一定程度的突发请求(支持一次拿多个令牌) | 限制常量流出速率(流出速率是固定值),从而平滑突发流入速率 |
3、限流算法的实际应用
3.1、单机模式限流实现
在 Guava 中 RateLimiter 的实现有两种: Bursty 和 WarmUp。
Bursty 是基于 token bucket 的算法实现,比如
RateLimiter rateLimiter=RateLimiter.create(permitPerSecond); //创建一个 bursty实例
rateLimiter.acquire(); //获取 1 个 permit,当令牌数量不够时会阻塞直到获取为止WarmUp
1. 基于Leaky bucket 算法实现
2. QPS 是固定的
3. 使用于需要预热时间的使用场景
RateLimiter create(double permitsPerSecond, long warmupPeriod, TimeUnit unit)//创建一个 SmoothWarmingUp 实例;warmupPeriod 是指预热的时间
RateLimiter rateLimiter=RateLimiter.create(permitsPerSecond,warmupPeriod,timeUnit);
rateLimiter.acquire();//获取 1 个 permit;可能会被阻塞止到获取到为止差异化演示
public class TokenDemo {
private int qps;
private int countOfReq;
private RateLimiter rateLimiter;
public TokenDemo(int qps, int countOfReq) {
this.qps = qps;
this.countOfReq = countOfReq;
}
public TokenDemo processWithTokenBucket() {
rateLimiter = RateLimiter.create(qps);
return this;
}
public TokenDemo processWithLeakyBucket() {
rateLimiter = RateLimiter.create(qps, 00, TimeUnit.MILLISECONDS);
return this;
}
private void processRequest() {
System.out.println("RateLimiter:" + rateLimiter.getClass());
long start = System.currentTimeMillis();
for (int i = 0; i < countOfReq; i++) {
rateLimiter.acquire();
}
long end = System.currentTimeMillis() - start;
System.out.println("处理请求数量:" + countOfReq + "," + "耗时: " + end + "," +
"qps:" + rateLimiter.getRate() + "," + "实际 qps: " +
Math.ceil(countOfReq / (end / 1000.00)));
}
public void doProcess() throws InterruptedException {
for (int i = 0; i < 20; i = i + 5) {
TimeUnit.SECONDS.sleep(i);
processRequest();
}
}
public static void main(String[] args) throws InterruptedException {
new TokenDemo(50, 100).processWithTokenBucket().doProcess();
new TokenDemo(50, 100).processWithLeakyBucket().doProcess();
}
}3.2、集群模式限流实现
3.2.1、利用redis实现集群计数器算法限流
用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个 key 保存下来。同一个用户同一种行为用一个 zset 记录。 为节省内存,我们只需要保留时间窗口内的行为记录,同时如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间。
通过统计滑动窗口内的行为数量与阈值 max_count 进行比较就可以得出当前的行为是否允许。用代码表示如下:
public class SimpleRateLimiter {
private Jedis jedis;
public SimpleRateLimiter(Jedis jedis) {
this.jedis = jedis;
}
public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount) {
String key = String.format("hist:%s:%s", userId, actionKey);
long nowTs = System.currentTimeMillis();
Pipeline pipe = jedis.pipelined();
pipe.multi();
pipe.zadd(key, nowTs, "" + nowTs);
pipe.zremrangeByScore(key, 0, nowTs - period * 1000);
Response count = pipe.zcard(key);
pipe.expire(key, period + 1);
pipe.exec();
pipe.close();
return count.get() <= maxCount;
}
public static void main(String[] args) {
Jedis jedis = new Jedis();
SimpleRateLimiter limiter = new SimpleRateLimiter(jedis);
for(int i=0;i<20;i++) {
System.out.println(limiter.isActionAllowed("userId", "action", 60, 5));
}
}
} 它的整体思路就是:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。
zset 集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可以了。
因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升 Redis 存取效率。
但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。redis的ttl特性完美的满足了这一需求,将时间窗口设置为key的失效时间,然后将key的值每次请求+1即可.伪代码实现思路:
//1.判断是否存在该key
if(EXIT(key)){
// 1.1自增后判断是否大于最大值,并返回结果
if(INCR(key) > maxPermit){
return false;
}
return true;
}
//2.不存在key,则设置key初始值为1,失效时间为3秒
SET(KEY,1);
EXPIRE(KEY,3);3.2.2、Redis-Cell 实现集群漏桶算法
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令。有了这个模块,限流问题就非常简单了。
安装方式
官方提供了安装包和源码编译两种方式,源码编译要安装rust环境,比较复杂,这里介绍安装包方式安装:
- 根据操作系统下载安装包;
- 将文件解压到redis能访问到的路径下;
- 进入 redis-cli,执行命令
module load /path/to/libredis_cell.so;
执行完以上步骤就可以使用其提供的限流功能了。该模块只有 1 条指令 cl.throttle,它的参数和返回值都略显复杂,接下来让我们来看看这个指令具体该如何使用。
> cl.throttle userId:action 15 30 60
1) (integer) 0 # 0 表示允许,1 表示拒绝
2) (integer) 15 # 漏斗容量 capacity
3) (integer) 14 # 漏斗剩余空间 left_quota
4) (integer) -1 # 如果拒绝了,需要多长时间后再试(漏斗有空间了,单位秒)
5) (integer) 2 # 多长时间后,漏斗完全空出来(left_quota==capacity,单位秒) 上面这个指令的意思是允许「用户某行为」的频率为每 60s 最多 30 次(漏水速率),漏斗的初始容量为 15,也就是说一开始可以连续执行 15 次某行为,然后才开始受漏水速率的影响。我们看到这个指令中漏水速率变成了 2 个参数,替代了之前的单个浮点数。用两个参数相除的结果来表达漏水速率相对单个浮点数要更加直观一些。
在执行限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle 指令考虑的非常周到,连重试时间都帮你算好了,直接取返回结果数组的第四个值进行 sleep 即可,如果不想阻塞线程,也可以异步定时任务来重试。
3.2.3、 使用Redisson实现令牌通算法
基于Redis的分布式限流器(RateLimiter) 可以用来在分布式环境下现在请求方的调用频率。既适用于不同Redisson实例下的多线程限流,也适用于相同Redisson实例下的多线程限流。该算法不保证公平性。
RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter");
// 初始化
// 最大流速 = 每1秒钟产生10个令牌
rateLimiter.trySetRate(RateType.OVERALL, 10, 1, RateIntervalUnit.SECONDS);
CountDownLatch latch = new CountDownLatch(2);
limiter.acquire(3);
// ...
Thread t = new Thread(() -> {
limiter.acquire(2);
// ...
});