程序性能数据采集工具汇总
https://en.wikipedia.org/wiki/List_of_performance_analysis_tools 其他一些分析工具
Intel® VTune™ Amplifier
1. 简介:
VTune™ Amplifier XE 集成了Intel® VTune™ Performance Analyzer 和 Thread Profiler的主要功能,同时吸取了Performance Tool Utility 这个实验产品的的优点(用户无需关注处理器的PMU部件上的具体事件,而是使用预定义的分析类型),可以帮助你分析算法选择,标识出你的应用程序怎样更好的利用可用的硬件资源。
Intel® VTune™ 性能分析器基础介绍 PPT:http://www.docin.com/p-721221027.html;
2. 是否开源
否
3. 官方网站:
https://software.intel.com/en-us/intel-vtune-amplifier-xe/
4. 特点与缺点
特点:VTune不仅支持对热点函数(hotspots)的分析,还支持对并发、锁等待、不同类型的CPU内存访问(都是Intel自家的)、读写带宽等进行分析,功能强大;使用gui工具来展示结果,直观易懂,非常方便
缺点:收费(可以免费试用一个月),过期了需要重新申请,
5. 主要功能:
使用VTune Amplifier XE可以定位或者决定如下内容:
在你的程序中或者整个系统中时间消耗最多的函数;
没有有效利用处理器时间的代码片段;
优化串行和线程化性能的最好代码片段;
影响程序性能的同步对象;
程序的I/O操作是否花费很多时间,以及在哪里、为什么花费时间;
不同的同步方法,不同的线程数量或者不同算法对于性能的影响;
线程活跃性和变迁;
代码中硬件相关的瓶颈;
6. 安装
Vtune下载和安装:
试用版:http://software.intel.com/en-us/articles/intel-vtune-amplifier-xe/ ,下载前需要注册账号,然后获得31天的测试版使用。通过邮件链接进行软件下载。以linux版本为例,进行解压缩
tar zxvf vtune_amplifier_xe_2015.tar.gz
gprof
1. 简介
gprof是GNU profile工具,可以运行于linux、AIX、Sun等操作系统进行C、C++、Pascal、Fortran程序的性能分析,用于程序的性能优化以及程序瓶颈问题的查找和解决。gprof 可以为 Linux平台上的程序精确分析性能瓶颈。gprof实际上只是一个用于读取profile结果文件的工具。
gprof采用混合方法来收集程序的统计信息,他使用检测方法,在编译过程中在函数入口处插入计数器用于收集每个函数的被调用情况和被调用次数;也使用采样方法,在运行时按一定间隔去检查程序计数器并在分析时找出程序计数器对应的函数来统计 函数占用的时间。Gprof能够精确地给出函数被调用的时间和次数,给出函数调用关系。
2. 是否开源
否
3. 特点与缺点
特点:gprof 优化尤其适用于CPU、内存密集性的应用模块。
缺点:功能比较简单,编译时候需要加入-pg 选项,使用不是很方便;Gprof一般用于对用户态的程序进行简单分析,对于很多时间都在内核态执行的程序,gprof不适合
4. 工作原理
需要在内存中分配几块内存(视需要进行profile的代码段大小而定,by monstartup),存储程序执行期间的统计数据
在GCC使用-pg选项编译后,gcc会在程序的入口处(before Main())call void monstartup(lowpc, highpc),在每个函数的入口call void _mcount(),在程序退出时(in atexit ())call void _mcleanup()。
monstartup:负责初始化profile环境,分配内存空间
需要实施跟踪程序的执行状况,记录程序代码的执行次数.
5. 主要功能
gprof 是GNU gnu binutils工具之一,默认情况下linux系统当中都带有这个工具。
可以显示“flat profile”,包括每个函数的调用次数,每个函数消耗的处理器时间,
可以显示“Call graph”,包括函数的调用关系,每个函数调用花费了多少时间。
可以显示“注释的源代码”--是程序源代码的一个复本,标记有程序中每行代码的执行次数。
gprof 用户手册: http://sourceware.org/binutils/docs-2.17/gprof/index.html
6. 安装
目前我们的linux主机上大多都安装了gprof,但是线上的gprof对多线程的支持不好,直接调用只能得到主线程的相关调用情况,为此,需要做一些额外的工作。使用提供的gprof-helper.c,将其编译为so库, 命令为: gcc -shared -fPICgprof-helper.c -o gprof-helper.so -lpthread –ldl
7. 使用流程
在编译和链接时 加上-pg选项。一般我们可以加在 makefile 中。
执行编译的二进制程序。
在程序运行目录下 生成 gmon.out 文件。如果原来有gmon.out 文件,将会被重写。
结束进程。这时 gmon.out 会再次被刷新。
用 gprof 工具分析 gmon.out 文件。
Oprofile
1. 简介
Oprofile也是一个开源的profiling工具,它使用硬件调试寄存器来统计信息,进行profiling的开销比较小,而且可以对内核进行profiling。它统计的信息非常的多,可以得到cache的缺失率,memory的访存信息,分支预测错误率等等,这些信息 gprof是得不到的,但是对于函数调用次数,它是不能够得到的。
2. 是否开源
是
3. 特点与缺点
特点:功能较强大,可以对每个线程进行单独采样,也可以对每个CPU单独采样,对于分析kernel或者系统级别的问题比较有用
缺点:不是很合适对stl使用频繁的程序进行分析
4. 官方网站
http://oprofile.sourceforge.net/news/
5. 工作原理
根据CPU系统结构的不同, Oprofile支持两种采样方式:基于事件(Event Based)的采样和基于时间(Time Based)的采样。
如果CPU内部存在性能计数寄存器,则Oprofile基于事件采样,记录特定事件(如分支预测事件)发生的次数,当达到设定的定值时就采样一次。反之,则基于时间采样,主要是借助于操作系统的时钟中断机制,每当时钟中断发生时就采样一次。不难看出,基于时间的采样方式,要求被测程序不能屏蔽中断,其精度也低于事件采样。
Oprofile主要分为两部分,其中一部分是内核模块(oprofile.ko),另外一部分是用户空间的守护进程(oprofiled)。前者主要负责访问性能计数寄存器或者注册基于时间采样的函数,并将采样结果置于内核的缓冲区中。后者在后台运行,负责从内核空间收集数据,并写入采样文件中,其交互流程如图1所示:
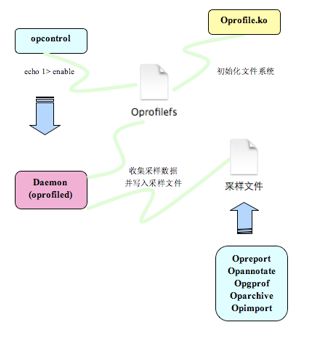
图1 oprofile交互流程图
6. 主要功能
Oprofile可以帮助用户识别诸如循环的展开、高速缓存的使用率低、低效的类型转换和冗余操作、错误预测转移等问题。它收集有关处理器事件的信息,其中包括TLB的故障、停机、存储器访问、位于 DCU(数据高速缓存单元)中的总线路数、一个 DCU 故障的周期数,以及不可高速缓存的和可高速缓存的指令的获取数量。Oprofile是一种细粒度的工具,可以为指令集或者为函数、系统调用或中断处理例程收集采样。Oprofile 通过取样来工作。使用收集到的评测数据,用户可以很容易地找出性能问题。
Oprofile用户手册:http://oprofile.sourceforge.net/doc/index.html
7. 安装使用
Oprofile需要内核的支持,2.6的linux内核已经支持了这个功能,可以编译成模块或者直接编译进内核。一般发行版本是没有将此项功能编译进内核的,因此需要手动编译一个内核版本,将cat /boot/config-uname -r | grep OPROFILE
应该有这样两行:
CONFIG_HAVE_OPROFILE=y
CONFIG_OPROFILE=m
如果没有则加上,CONFIG_OPROFILE=m表示编译成模块,CONFIG_OPROFILE=y表示直接编译进内核。一般选择直接编译进内核。使用重新编译的内核启动机器,如果oprofile编成了模块,需要加载oprofile模块。
Oprofile的安装:
1) 下载oprofile软件包,并用tar解压
2) ./configure –with-linux=/usr/src/linux/ –with-qt-dir=/usr/lib/qt/ –with-kernel-support
3) make
4) make install
Google performance Tools (gperftools)
1. 简介
gperftools是google开发的一款非常实用的工具集,主要包括:性能优异的malloc free内存分配器tcmalloc;基于tcmalloc的堆内存检测和内存泄漏分析工具heap-profiler,heap-checker;基于tcmalloc实现的程序CPU性能监测工具cpu-profiler。
2. 是否开源
否
3. 特点与缺点
特点:包含内存分配器,内存泄露分析器,CPU使用分析器,callgraph也比较精准,用起来简单方便(只要链接lib然后配置一个环境变量就好了),并且自己可以使用代码精确控制profile的配置
缺点:精确度一般,对函数次数和执行时间的统计都是通过采样频率估算的,存在一定的偏差和遗漏。
4. 官方网站
https://code.google.com/p/gperftools/
5. 主要功能
它的主要功能就是通过采样的方式,给程序中cpu的使用情况进行“画像”,通过它所输出的结果,我们可以对程序中各个函数(得到函数之间的调用关系)耗时情况一目了然。
性能分析监控;
定位内存泄漏;
寻找性能热点;
提高malloc free内存分配性能。
gperftools 使用:https://code.google.com/p/gperftools/wiki/GooglePerformanceTools?redir=1
6. 安装使用
下载安装gperftools:
Wget https://code.google.com/p/gperftools/downloads/detail?name=gperftools-2.0.tar.gz
tar –xzf gperftools-2.0.tar.gz
cd gperftools-2.0
./configure –prefix=/usr/local –enable-frame-pointers
make && make install
使用
目标程序中引入头文件< google/profiler.h>,链接libprofiler库,64位操作系统同时链接libunwind库,在需要分析代码的起点和终点调用ProfilerStart()函数和ProfilerStop()函数
编译链接,运行程序
PAPI
1. 简介
Performance Application Programming Interface PAPI是一套API,使用PAPI可以得到硬件级的数据,即与微指令相关的数据,例如L1/L2 cache miss、TLB miss、Cycle。PAPI可以在大多数现代微处理器上指定一个标准的应用程序编程接口(API)来访问硬件性能计数器。这些计数器相当于一组暂存器来对处理器功能相关的事件以及特殊信号的发生进行计数。监听这些事件促进源/目标代码的结构和底层架构代码映射效率的关联。这种相关性性能分析有多种用途,包括手动调优,编译器优化、调试、基准测试、监控和性能建模。
2. 是否开源
是 (有C和Fortran两个实现版本)
3. 官方网站
http://icl.cs.utk.edu/papi/
4. 主要功能
PAPI(Performance Application Programming Interface)田纳西大学创新计算实验室开发的一组与机器无关的可调用的例程,提供对性能计数器的访问,其研究目的是设计、标准化与实现可移植的、高效的性能计数器API。
(1)支持的性能计数器事件
PAPI支持本地事件和多个预设事件。其标准事件分为4类:存储层次访问事件;周期与指令计数;功能部件与流水线状态事件;Cache一致性事件,与SMP系cache一致性协议相关。
随PAPI参考实现包含一个工具程序avail,可以检测用户平台具有哪些事件。
(2)用户接口
PAPI为用户使用性能计数器提供3种接口:
a) 低级接口:管理用户定义的事件组(称为EventSet)中的事件,完全可编程,线程安全,为工具开发人员和高级用户提供方便
b) 高级接口:提供启动、停止和读取特定事件的能力
c) 图形界面(Perfometer):PAPI性能数据可视化工具。
5. 软件版本及下载(http://icl.cs.utk.edu/papi/software/ )
PAPI 5.4.1(最新版本)
PAPI 5.4.0
PAPI 5.3.2
6. 安装以及使用
用户指南:http://icl.cs.utk.edu/projects/papi/wiki/User_Guide
安装说明:
a) 安装前需要确保内核中安装了 perfctr 模块并且是动态加载方式(modprobe perfctr),并且支持APIC;
b) 确保 perfctr 使用正常,所有测试实例能够正常运行,例如 perfex -i;
c) 然后根据官网PAPI的Source Code Repository中的INSTALL.txt进行安装
7. Source Code Repository
http://icl.cs.utk.edu/trac/papi/browser
PAPIex
1. 简介
PAPIex版本已经不再受开发者所支持,包括田纳西大学和SiCortex的前雇员。papiex性能分析工具使用PAPI对应用程序的硬件性能计数器进行透明地和被动地测量。它使用Monitor(一个程序库)来毫不费力地拦截进程,创建和销毁线程。它监控整个应用程序的运行。在默认情况下这包括所有子流程。papiex的目标是成为一个Linux系统中的代替品代替SGI的Speedshop的perfex命令。Papiex能够很简单的建造、安装和使用。Monitor的最新文档大部分都可以在使用手册里(man pag)找到。
2. 是否开源
是
3. 官方网站:http://icl.cs.utk.edu/~mucci/papiex/
4. 主要功能和特点
Papiex是一个基于PAPI的程序,以命令行的方式测量应用程序的硬件性能事件。它同时支持PAPI预设事件和本地事件。它支持多个线程的执行,包括pthreads和OpenMP线程。对于MPI程序,papiex跨任务可以收集统计信息。Papiex也计算在I / O和MPI调用所花费的总时间。
a) 除了PAPI和Monitor没有其他外部依赖;
b) 用户代码支持papiex_start()/papiex_stop() 方法;(papiex_start()/papiex_stop()的使用方法)
c) 可以报告各种各样的内存使用情况
d) 支持PAPI多路技术
e) 通过单个标记(-a)为架构提供有效事件的自动计数
f) 自动检测线程化的可执行文件
g) 为MPI和线程化的MPI工作
h) 特别支持MPICH,避免了链接papiex和MPICH库
i) 转储总体的统计数据,例如线程和任务之间的mean/max/avg。
j) 在分支和执行程序的变体间工作,正确处理中断信号/判断提示/异常中断
k) 如果不想使用papiex驱动程序可以省略shell参数
l) 支持本地事件计数(无PAPI)和不同的计数区域
m) 架构独立构建和papiex-config驱动(papiex-config使用方法)
5. 安装及使用
安装:http://icl.cs.utk.edu/~mucci/papiex/INSTALL
使用:http://icl.cs.utk.edu/~mucci/papiex/papiex-man.html
6. Source Code Repository
http://icl.cs.utk.edu/viewcvs/viewcvs.cgi/OSPAT/iotrack/
OpenSpeedShop
1.简介
OpenSpeedShop是一个开源的多平台Linux性能工具,用于单节点或者大规模 IA64, IA32, EM64T, AMD64, PPC, ARM, Blue Gene, Cray平台上的程序运行性能分析。
OpenSpeedShop采用模块化设计,可以扩展。它支持多个层次上的插件,使得用户可以添加自定义的性能测试实验。
2.是否开源
是
3.特点
用途广泛:可用于串行、多线程、MPI程序
无需重新编译用户的程序
可以选择分析层次的深度
易用的GUI,以及可以脚本执行的命令行接口和Python API
支持基于Intel和AMD的Linux系统
在Los Alamos National Laboratory,Lawrence Livermore National Laboratory, Sandia National Laboratory的主要集群上得到应用
4.官方网站
https://openspeedshop.org/
5.主要功能
Program Counter Sampling
Support for Callstack Analysis
Hardware Performance Counter Sampling and Threshold based
MPI Lightweight Profiling and Tracing
I/O Lightweight Profiling and Tracing
Floating Point Exception Analysis
Memory Trace Analysis
POSIX Thread Trace Analysis
6.安装使用
http://openspeedshop.org/wp-content/uploads/2013/12/OSSQuickStartGuide2013revised.pdf
7.Source code
http://sourceforge.net/projects/openss/files/openss/
thread spotter
1.简介
目前计算机的多层次存储结构和应用程序之间的适配性很差。处理器通常花费很多时间等待数据。多核处理器加剧了这个问题的所带来的影响,因为每个线程分得的cache变小了。
ThreadSpotter在程序运行时对其进行分析,然后按重要性排序列出性能问题,给出分析数据和修正建议。
(即,ThreadSpotter是一个针对多核程序的cache利用的分析指导工具)
2.是否开源
是
3.特点
不是仅仅收集原始数据,而是指导开发者来修正问题,对线程通信和交互进行建模
4.官方网站
http://www.paratools.com/threadspotter
5.主要功能
ThreadSpotter在程序运行时对其进行监控(无需重新编译),捕获少量的内存标识,这些标识可以反映程序的局部性特征。用户无需了解存储器的底层细节,ThreadSpotter会将所有问题和对应的代码关联起来,指导进行程序的性能提升。
6.安装使用
见源码包内的文档
7.Source code
ftp://ftp.paratools.com/threadspotter/tar/ParaTools-TS-latest.tgz