Kafka教程(三)---------------底层实现细节之broker
目录
-
-
- 目录
-
- 一数据存储
- 数据目录
- 数据文件
- 数据查找
- 二 数据缓存
- 缓存的好处
- 缓存方案
- pageCache原理
- 缓存失效问题
- pageCache优化参数
- 三 数据备份
- 容错方案
- 数据同步过程
一、数据存储
我们从上面可以看到,broker中存储的是各个topic的各个partition中的数据
1.数据目录
每个broker都是有自己 存消息数据的目录(参考第一节的配置)
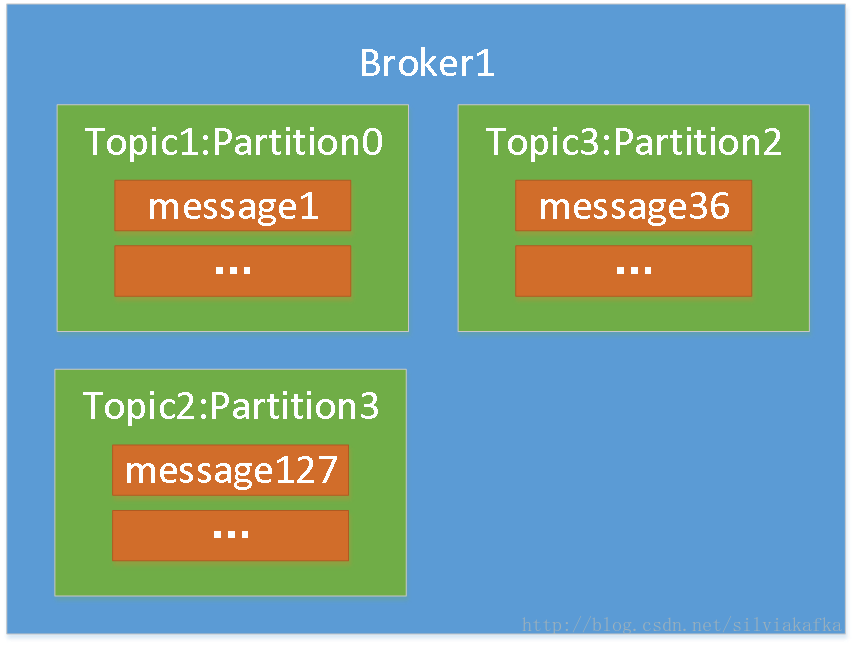
比如下图是某个broker的数据目录,里面是子目录,子目录名字为topicname-partition,存储的内容就是这个topic的这个partition里面的message数据

2.数据文件
这里面存的是消息数据,在这个partition内部,数据的进入是有序的,用一个线性的offset(偏移量)来标识每条数据的位置,相当于排队的号码牌,每条消息(message)有一个它的offset,这个offset不是整个topic全局的,是这个topic的这个partition里面”号码牌”,它可以唯一确定每条消息在parition(分区)内的位置。

Message(消息数据)的结构如下

如果一直往一个log文件中写,那么这个文件会不断膨胀,而且一个文件也不利于管理。所以写满一个后,开启新的文件写入。
这个“写满”的标准:log.segment.bytes,由这个参数控制。比如这个值是1G,那么当log文件大小达到1G之后,就会开启一个新的log文件去写入数据,新进来的数据写入新的log文件中。
每一个log文件就是一个segment(分段的概念),log文件的命名是其起始offset
如下图就有四个segment(四个log文件)

除了有log文件,还有index文件。他们成对出现,index文件是为了数据查找。
3.数据查找
大多数场景下,我们消费kafka中的数据都是顺序读取下来的。但存在一些场景是需要随机读取某个offset的消息:比如kafka消费者(下一章讲解)处理消息时程序失败,重新处理,需要重新从该partition的某个offset数据续读数据。
那么如何快速定位某个partition的某个offet的消息数据:
步骤1:根据offset定位在哪一个log文件中
查找文件列表,根据log的文件名称和offset的比较就可以定位到具体log文件(二分查找,非常快)。比如查找这个partition的offet为368784的消息,那么一定是落在0000000368769.log文件中的
步骤2:根据此log文件对应的索引文件(.index文件)进一步定位其物理位置
在topicname-partition目录内部,有一系列数据文件,是Log与index文件对,如上图
log文件存储的是消息数据信息,index是索引信息。这样存储的目的就是为了方便查找指定的offset的数据,index中存储的是相对offset和position。
根据在index中查找到该offset所在的位置,直接移动文件指针即可访问到数据。
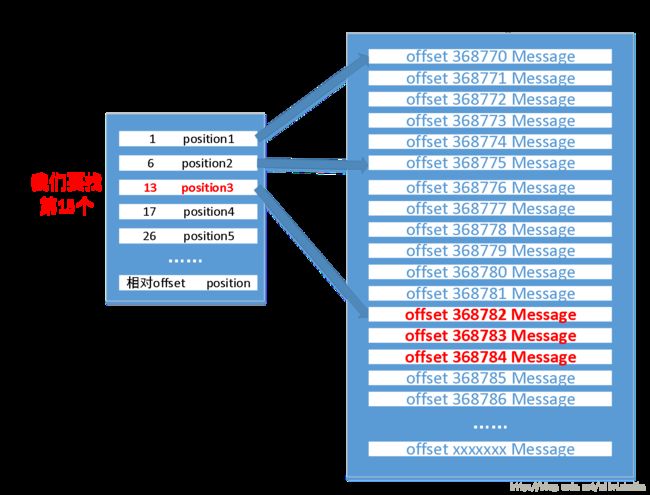
例:我们查找0000000368769
索引文件是稀疏索引,没有记录每条message的索引,只记录了一部分。现在要找368784,已经判断出来落在0000000000368769.log文件中了,此时的相对offset为368784-368769=15,在index文件中查找,发现落在13和17之间,那么我们找到13对应的position3,也就是文件的中的位置,直接定位到offet 368782 的数据,再往下就可以很快找到偏移量为368784的数据
注意:
相对offset:没有在index中存储绝对offset,而是存储的相对offset,可以节省空间
position:表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个position就可以读取对应的Message了
二、 数据缓存
如果每次有消息进入,就往log文件中写入,那么就会造成大量的磁盘随机写入。磁盘性能低,上层应用性能也被拉低。所以引入数据缓存。
1.缓存的好处
通过缓存是写入到内存中,所以应用的写入速度会非常快
其次,缓存是统一写入磁盘,可以合并很多消息,可以达到顺序写入的效果,磁盘的顺序写效率非常高。磁盘顺序读写和随机读写的差别巨大:Sequence IO 600M/s Random IO 100k/s。所以需要将要写入的数据先缓存起来再统一写入,从而提升写入效率
2.缓存方案
缓存可以由服务进程自己维护,也就是将数据缓存到JVM内部。但这样就需要创建Java对象,则会占进程大量内存。缓存存入磁盘后缓存的Java对象需要删除,又需要JVM进行垃圾回收,GC过程又影响性能。
所以Kafka采取操作系统级别缓存。数据缓存不再占用应用自身的资源,而是直接交由操作系统来完成。也就是PageCache。
而且如果Kafka服务重启,进程中缓存的数据会失效,而OS管理的PageCache依然可用
3.pageCache原理
操作系统将闲置的memory用作disk caching。当数据写入时,操作系统将数据写入pageCache,同时标记该page为dirty;当读取数据时,先从pageCache中查找,如果没有查到(发生缺页)则去磁盘中读取,返回数据。
所以本质上pageCache就是尽量把空闲的内存用作磁盘缓存。这个缓存是操作系统级别的,现代OS基本上都支持PageCache

注意:目前笔者认为,这个数据交由操作系统层后,对于上层应用Kafka服务进程来说,就认为已经存储了,至于操作系统层是否持久化到磁盘,对于kafka服务透明,不影响上层结果。
4.缓存失效问题
由于数据在内存,那么依然存在系统down机内存数据丢失的风险。
而对于上层Kafka进程来说,既然认为数据已经存储了(commit),那么如果系统缓存失效就导致kafka的commit的数据丢失了。
所以就有参数可以控制log.flush.interval.messages和log.flush.interval.ms,也就是达到一定消息条数或者一定时间,就强制写入到磁盘。但Kafka官方并不建议通过Broker端的来强制写盘,认为数据的可靠性应该通过Replica来保证(在后面将详细讲解,机器A down掉之后,commit的数据在机器B上是还有一份的)。强制Flush数据到磁盘会对整体性能产生影响。
所以说kafka保证它存在于多个replica内存中,不保证被持久化到磁盘。
5.pageCache优化参数
可以通过调整系统参数/proc/sys/vm/dirty_background_ratio和/proc/sys/vm/dirty_ratio来调优性能。
脏页率超过第一个指标会启动pdflush开始Flush Dirty PageCache。
脏页率超过第二个指标会阻塞所有的写操作来进行Flush。
根据不同的业务需求可以适当的降低dirty_background_ratio和提高dirty_ratio。
三、 数据备份
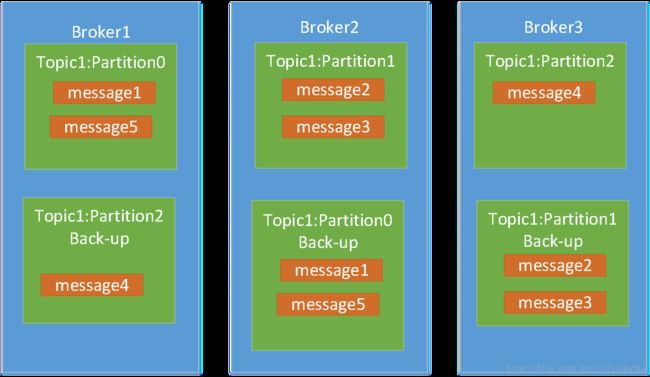
在第一章就讲到replication,比如创建时设置–replication-factor 2。
1.容错方案
数据备份的意义就在于:在机器或者服务进程出现问题时,kafka集群依然能对外提供服务。
比如上例中,现在partition0在broker1中,partition1在broker2中,partition2在broker3中; 如果broker2机器down掉,则变成如下:
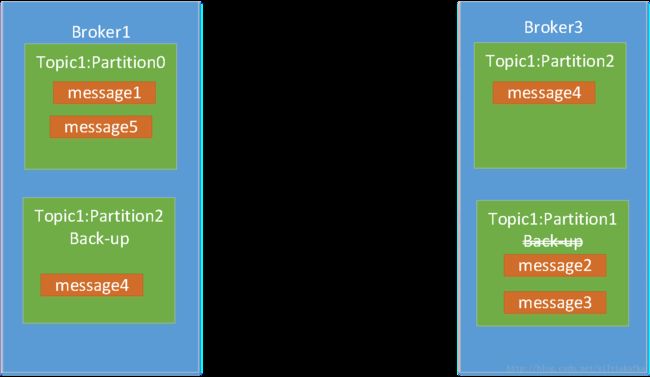
Broker3上的partition1 backup就会自动顶上提供服务(嗯,奏四这么智能),那么broker3就成为partition1的leader。
什么是leader:也就是正在提供这个partition数据服务的节点
Replica:所有拥有这个partition数据的节点。其中一个作为leader向外提供服务,其他作为follower跟着leader的领导。Leader挂掉之后,follower会选举一个出来作为新leader。
Isr:In-Sync Replicas(在同步中的replica)代表活着并且能跟上的replica(什么叫能跟上,下一节介绍)
例如
比如有四台机器,replica为2,partition6,则如下
Partition 0 leader 1 replica 1,2 isr 1,2
Partition 1 leader 2 replica 2,3 isr 2,3
Partition 3 leader 3 replica 3,4 isr 3,4
Partition 4 leader 4 replica 4,5 isr 4,5
Partition 5 leader 5 replica 5,6 isr 5,6
Partition 6 leader6 replica 6,1 isr 6,1
· 挂一台机器
比如此时1号机器down了,broker会自己调整leader,进行leader的转移
Partition 0 leader 2 replica 1,2 isr 2
Partition 1 leader 2 replica 2,3 isr 2,3
Partition 3 leader 3 replica 3,4 isr 3,4
Partition 4 leader 4 replica 4,5 isr 4,5
Partition 5 leader 5 replica 5,6 isr 5,6
Partition 6 leader 6 replica 6,1 isr 6
· 挂两台机器
在上面的基础上
如果此时又2挂了,那么partition0的数据就不可用了,集群丢数据了
如果此时又6挂了,那么partition6的数据就不可用了,集群丢数据了
(数据是不可能转移的)
但如果是3/4/5挂了,整个集群还可以坚持,还能对外提供完整的6个partition的数据服务
比如5挂了
Partition 0 leader 2 replica 1,2 isr 2
Partition 1 leader 2 replica 2,3 isr 2,3
Partition 3 leader 3 replica 3,4 isr 3,4
Partition 4 leader 4 replica 4,5 isr 4
Partition 5 leader 6 replica 5,6 isr 6
Partition 6 leader 6 replica 6,1 isr 6
· 挂三台机器
现在还剩2,3,4,6.
如果3挂了,还能对外提供完整服务。
如果其他节点挂了,集群将丢数据。
2.数据同步过程
我们上面说了,leader对外提供服务,leader负责这个partition所有数据的读写操作。(leader是partition级别的,不是topic级别的)
其他replica节点叫做follower,那他们的首要任务就是需要同步leader的数据到自己这里
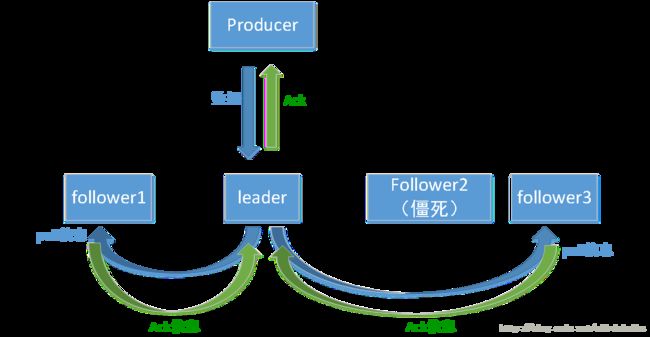
当有新数据写入到leader中时,其他follower会从leader那pull(拉取)数据,并且发送ack(acknowledge)告诉leader自己同步到哪个offset了,如果能和leader保持一致,就可以认为它能跟上节奏。
例如上图,follower1,follower3都会不断pull信息,发送ack回复leader,但follower2因为jvm在GC而导致进程僵死,可能就不会拉取新的数据,导致跟不上了,延迟条数太多(或者延迟时间太多),最终会被踢出ISR中。此时ISR中只有follower1和follower3。但follower2依然是replica的成员,所以它醒了之后还会默默pull信息,如果能追赶上,则又可以加入到ISR中。
可以catch up(跟上节奏)的节点就是在同步中(ISR)的,跟不上(延迟时间过长或者延迟条数过多)的就会被踢出ISR中。
