练习题︱图像分割与识别——UNet网络练习案例(两则)
代码见Github:mattzheng/U-Net-Demo
U-Net是Kaggle比赛非常青睐的模型,简单、高效、易懂,容易定制,可以从相对较小的训练集中学习。来看几个变形:
(1)Supervise.ly 公司。
在用 Faster-RCNN(基于 NasNet)定位 + UNet-like 架构的分割,来做他们数据众包图像分割方向的主动学习,当时没有使用 Mask-RCNN,因为靠近物体边缘的分割质量很低(终于!Supervise.ly 发布人像分割数据集啦(免费开源));(2)Kaggle-卫星图像分割与识别。
需要分割出:房屋和楼房;混杂的人工建筑;道路;铁路;树木;农作物;河流;积水区;大型车辆;小轿车。在U-Net基础上微调了一下。 而且针对不同的图像类型,微调的地方不一样,就会有不同的分割模型,最后融合。(Kaggle优胜者详解:如何用深度学习实现卫星图像分割与识别)(3)广东政务数据创新大赛—智能算法赛 。
国土监察业务中须监管地上建筑物的建、拆、改、扩,高分辨率图像和智能算法以自动化完成工作。并且:八通道U-Net:直接输出房屋变化,可应对高层建筑倾斜问题;数据增强:增加模型泛化性,简单有效;加权损失函数:增强对新增建筑的检测能力;模型融合:取长补短,结果更全。(参考:LiuDongjing/BuildingChangeDetector)
(4)Kaggle车辆边界识别——TernausNet。
由VGG初始化权重 + U-Net网络,Kaggle Carvana Image Masking Challenge 第一名,使用的预训练权重改进U-Net,提升图像分割的效果。开源的代码在ternaus/TernausNet当然现在还有很多流行、好用的分割网络:谷歌的DeepLabv3+(DeepLab: Deep Labelling for
Semantic Image Segmentation)、Mask R-CNN、COCO-16 图像分割冠军的实例分割FCIS(msracver/FCIS) 等。
跟目标检测需要准备的数据集不一样,因为图像分割是图像中实体的整个轮廓,所以标注的内容就是物体的掩膜。有两种标记方式:一种是提供单个物体的掩膜、一种是提供物体轮廓的标点。
一、U-Net网络练习题一: Kaggle - 2018 Data Science Bowl
因为Kaggle有该比赛,而且code写的很简单易懂,于是乎拿来玩一下。Keras U-Net starter - LB 0.277
与U-Net相关的开源项目与code很多,各种框架的版本都有:Tensorflow Unet、End-to-end baseline with U-net (keras)等等。
1.1 训练集的构造
因为使用的是比赛数据,赛方已经很好地帮我们做好了前期数据整理的工作,所以目前来说可能很方便的制作训练集、测试集然后跑模型。这里下载得到的数据为提供图像中单个物体的掩膜。其中,笔者认为最麻烦的就是标注集的构造(掩膜)。
原图:

掩膜图:

从掩膜列表可以到,比赛中是把每个细胞的掩膜都分开来了。来看一下这个掩膜标注内容如何:
mask = np.zeros((IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)
Y_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)
for mask_file in next(os.walk(path + '/masks/'))[2]:
mask_ = imread(path + '/masks/' + mask_file)
mask_ = np.expand_dims(resize(mask_, (IMG_HEIGHT, IMG_WIDTH), mode='constant',
preserve_range=True), axis=-1)
mask = np.maximum(mask, mask_)
Y_train[n] = mask- 读入(imread)掩膜图,图像的格式为:(m,n);
- resize,掩膜的尺寸缩放在128*128
- np.expand_dims步骤改变图像维度为(m,n,1);
- np.maximum,当出现很多掩膜的时候,有些掩膜会重叠,那么就需要留下共有的部分;
- Y_train的数据格式已经定义为bool型,那么最后存储得到的数据即为(x,m,n,1),且数据格式为True/False:
array([[[[False],
[False],
[False],
...,
[False],
[False],
[False]],
[[False],
[False],
[False],
...,
[False],
...其他X_train训练数据集,就会被存储成:(x,m,n,3),同时需要resize成128*128
1.2 预测
预测就可以用model.predict(X_test, verbose=1),即可以得到结果。那么得到的结果是(128,128,1)的,那么就是一个图层,也就是说U-Net出来的结果是单标签的,如果是多标签那么可以多套模型,可参考:Kaggle-卫星图像分割与识别。
预测出来的结果为单图层,可以重新回到原尺寸:
resize(np.squeeze(preds_test[i]),
(sizes_test[i][0], sizes_test[i][1]), mode='constant', preserve_range=True)1.3 结果提交
图像分割在提交结果的时候,主要就是掩膜了。那么掩膜的提交需要编码压缩:
Run-Length Encoding(RLE)行程长度的原理是将一扫描行中的颜色值相同的相邻像素用一个计数值和那些像素的颜色值来代替。例如:aaabccccccddeee,则可用3a1b6c2d3e来代替。对于拥有大面积,相同颜色区域的图像,用RLE压缩方法非常有效。由RLE原理派生出许多具体行程压缩方法。
那么图像压缩出来的结果即为:
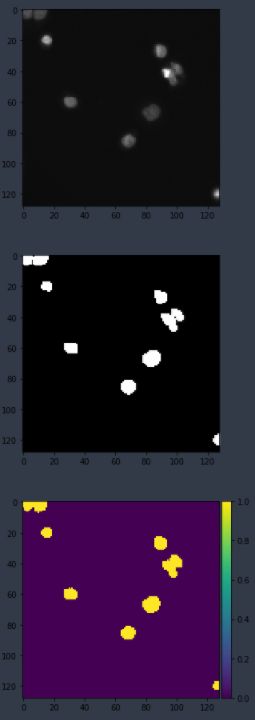
'137795 3 138292 25 138802 29 139312 32 139823 34 140334 36 140845 38 141356 40 141867 42 142371 51 142881 54 143391 57 143902 59 144414 59 144925 61 145436 62 145948 63 146459 65 146970 66 147482 66 147994 66 148506 66 149017 67 149529 67 150041 67 150553 67 151065 67 151577 66 152089 66 152602 65 153114 64 153626 64 154138 63 154650 63 155162 63 155674 63 156187 62 156699 62 157212 60 157724 60 158236 60 158749 59 159261 59 159773 58 160285 58 160798 56 161310 56 161823 55 162335 54 162848 53 163361 52 163874 50 164387 49 164899 48 165412 47 165925 45 166439 42 166953 40 167466 38 167980 35 168495 31 169009 28 169522 26 170036 23 170549 21 171062 18 171577 12 172093 4'那么下图就是出来的结果了,第一张为原图,第二张为标注的掩膜图,第三张为预测图。
二、U-Net网络练习题二:气球识别
在《如何使用Mask RCNN模型进行图像实体分割?》一文中提到了用Mask-RCNN来做气球分割,官网之中也有对应的代码,本着练习的态度,那么笔者就拿来这个数据集继续练手,最麻烦的仍然是如何得到标注数据。MaskRCNN的开源code为Mask R-CNN - Inspect Balloon Training Data
由于很多内容是从Mask R-CNN之中挖过来的,笔者也没细究,能用就行,所以会显得很笨拙…
2.1 训练集的准备
数据下载页面:balloon_dataset.zip
该案例更为通用,因为比赛的训练集是比赛方写好的,一般实际训练的时候,掩膜都是没有给出的,而只是给出标记点,如:
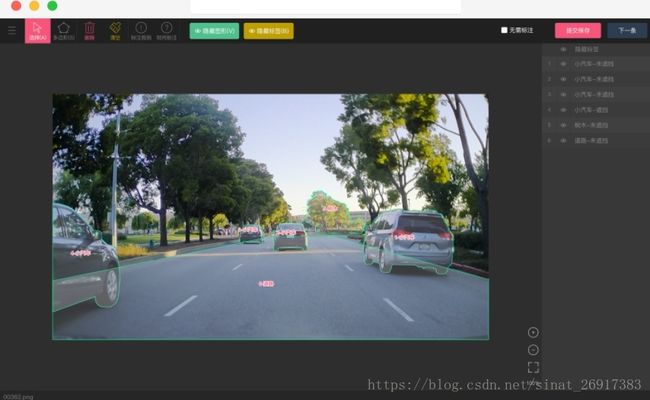

此时的标注数据都放在json之中,譬如:
{'10464445726_6f1e3bbe6a_k.jpg712154': {'base64_img_data': '',
'file_attributes': {},
'filename': '10464445726_6f1e3bbe6a_k.jpg',
'fileref': '',
'regions': {'0': {'region_attributes': {},
'shape_attributes': {'all_points_x': [1757,
1772,
1787,
1780,
1764],
'all_points_y': [867,
913,
986,
1104,
1170],
'name': 'polygon'}},all_points_x以及all_points_y都是掩膜标记的(x,y)点坐标,每一个物体都是由很多个box构造而成:
def get_mask(a,dataset_dir):
image_path = os.path.join(dataset_dir, a['filename'])
image = io.imread(image_path)
height, width = image.shape[:2]
polygons = [r['shape_attributes'] for r in a['regions'].values()]
mask = np.zeros([height, width, len(polygons)],dtype=np.uint8)
# 掩膜mask
for i, p in enumerate(polygons):
# Get indexes of pixels inside the polygon and set them to 1
rr, cc = skimage.draw.polygon(p['all_points_y'], p['all_points_x'])
mask[rr, cc, i] = 1
# 此时mask为(685, 1024, 1)
# mask二值化
mask, class_ids = mask.astype(np.bool), np.ones([mask.shape[-1]], dtype=np.int32)
# 提取每个掩膜的坐标
boxes = extract_bboxes(resize(mask, (128, 128), mode='constant',preserve_range=True))
unique_class_ids = np.unique(class_ids)
mask_area = [np.sum(mask[:, :, np.where(class_ids == i)[0]])
for i in unique_class_ids]
top_ids = [v[0] for v in sorted(zip(unique_class_ids, mask_area),
key=lambda r: r[1], reverse=True) if v[1] > 0]
class_id = top_ids[0]
# Pull masks of instances belonging to the same class.
m = mask[:, :, np.where(class_ids == class_id)[0]]
m = np.sum(m * np.arange(1, m.shape[-1] + 1), -1)
return m,image,height,width,class_ids,boxes- polygon之中记录的是一个掩膜的(x,y)点坐标,然后通过
skimage.draw.polygon连成圈; mask[rr, cc, i] = 1这句中,mask变成了一个0/1的(m,n,x)的矩阵,x代表可能有x个物体;- mask.astype(np.bool)将上述的0/1矩阵,变为T/F矩阵;
- extract_bboxes()函数,要着重说,因为他是根据掩膜的位置,找出整体掩膜的坐标点,给入5个物体,他就会返回5个物体的坐标
(xmax,ymax,xmin,ymin) - np.sum()是降维的过程,把(m,n,1)到(m,n)
那么,最终 Y_train的数据格式如案例一,一样的:
array([[[[False],
[False],
[False],
...,
[False],
[False],
[False]],
[[False],
[False],
[False],
...,
[False],
...2.2 模型预测
model = load_model(model_name, custom_objects={'mean_iou': mean_iou})
preds_train = model.predict(X_train[:int(X_train.shape[0]*0.9)], verbose=1)
preds_val = model.predict(X_train[int(X_train.shape[0]*0.9):],verbose=1)
preds_test = model.predict(X_test,verbose=1) 这边的操作是把trainset按照9:1,分为训练集、验证集,还有一部分是测试集
输入维度:
X_train (670, 128, 128, 3)
Y_train (670, 128, 128, 1)
X_test (65, 128, 128, 3)输出维度:
每个像素点的概率[0,1]
preds_train (603, 128, 128, 1)
preds_val (67, 128, 128, 1)
preds_test (65, 128, 128, 1)2.3 画图函数
该部分是从MaskRCNN中搬过来的,
def display_instances(image, boxes, masks, class_names,
scores=None, title="",
figsize=(16, 16), ax=None,
show_mask=True, show_bbox=True,
colors=None, captions=None):需要图像矩阵image,boxes代表每个实例的boxes,masks是图像的掩膜,class_names,是每张图标签的名称。下图是128*128像素的,很模糊,将就着看吧…

随机颜色生成函数random_colors
def random_colors(N, bright=True):
"""
Generate random colors.
To get visually distinct colors, generate them in HSV space then
convert to RGB.
"""
brightness = 1.0 if bright else 0.7
hsv = [(i / N, 1, brightness) for i in range(N)]
colors = list(map(lambda c: colorsys.hsv_to_rgb(*c), hsv))
random.shuffle(colors)
return colors还有就是一般来说,掩膜如果是(m,n),或者让是(m,n,1)都是可以画出来的。
imshow(mask)
plt.show()