超详细数据分析基础知识之python编程基础(各种基础命令操作必备,numpy库和pandas库对数据操作命令)
Python编程基础、numpy包、pandas包的用法(详细)
一、python编程入门
1.python的工作目录
在使用Python时,一个重要设置是定义工作目录,即设置当前运行路径。
例如:
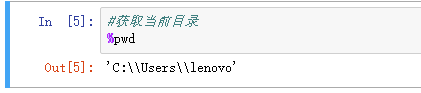
#获取当前目录
%pwd
#改变工作路径
%cd"D:python"
2.python分析包
python具有丰富的数据分析模块,大多数做数据分析的人使用python是因为其强大的数据分析功能。所有的python函数和数据集是保存在里面的。只有当一个包被安装并被载入(import)时,他的内容才可以被访问。
常用的数据分析包:
包名 说明 主要功能
math 基础数学包 提供函数,完成各种数学运算
random 随机数生成包 Python中的random模块用于生成各种随机数
numpy 数值计算包 numpy (numeric python)是Python的一种开源的数值计算扩展,一个用Python实现的数值计算工具包。它提供许多高级的数值编程工具,如矩阵数据类型、矢量处理,以及精密的运算包。专为进行严格的数值处理而产生
scipy 数值分析包 提供很多科学计算工具包和算法,方便是易于使用,专为科学和工程设计的数值分析工具包。它包括统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理、常微分方程求解器等,包含常用的统计估计和检验方法
pandas 数据操作包 提供类似于R语言的Dataframe操作,非常方便。 pandas是面板数据(panel data)的简写。它是Python最强大的数据分析和探索工具,因金融数据分析工具而开发,支持类似SQL的数据增、删、改、查,支持时间序列分析,灵活处理缺失数据
statsmodels 统计模型包 statsmodels可以补充scipy.stats,是一个包含统计模型、统计测式和统计数据挖掘的Python模块。对每个模型都会生成一个对应的统计结果,对时间序列有完美的支持
matplotlib 基本绘图包 该包主要用于绘图和绘表,是一个强大的数据可视化工具,语法类似于Matlab,是一个Python的图形框架,类似于Matlab和R语言。它是Python最著名的绘图库,提供了一整套和Matlab相似的命令API,十分适合交互式制图。而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中
sklearn 机器学习包 sklearn是基于Python的机器学习工具模块,里面主要包含6大模块:分类、回归、聚类、降维、模型选择、预处理,如,使用sklearn.decomposition可进行主成分分解
beautifulSoup 网络爬虫包 beautifulsoup是Python的一个包,最主要的功能是从网页抓取数据。BeautifulSsoup提供一些简单的、Python式的函数,用来处理导航、搜索、修改分析树等功能。通过解析文档为用户提供需要抓取的数据,通过它可以很方便地提取出HTML或XML标签中的内容
network 复杂网络包 networkx一款Python的软件包,用于创造、操作复杂网络,以及学习复杂网络的结构、动力学及其功能。通过它可以用标准或者不标准的数据格式加载或者存储网络,它可以产生许多种类的随机网络或经典网络,也可以分析网络结构、建立网络模型、设计新的网络算法、绘制网络等
注意:安装程序包和载入程序包是两个概念,安装程序包是指将需要的程序包安装到电脑中,载入包是指将程序包调入Python环境中。程序包的安装(通常在命令行状态:)> > > pip install pandas
python调用包的命令是import ,如需要调用上述包,可用
- import math
- import random
- import numpy
- import scipy
- import pandas
- import matplotlib
这些包中的函数,可直接使用包名加“.”。如要用matplotlib绘plot图,可用matplotlib.plot(…)。
如要简化这些包的写法,可用as命令赋予别名,如:
- import numpy as np
- import pandas as pd
- import matplotlib as plt
这样matplotlib.plot(…)可以简化为plt.plot(…)。
如要调用python包中某个具体函数或方法,可使用 from … import 例如:
调用math中的开放、对数、和pi函数,则:
from math import sqrt,log,pi
这样,可以直接在程序中使用,如sqrt(2),等价于math.sqrt(2).
3.python中的数据管理
目前,python中最大的问题就是数据管理,因为python没有好的数据管理器,其自带的数据管理器很不方便,所以,要用好Python软件,就得将python与Excel等电子表格充分结合,发挥两者的优点。
二、python数据类型
1.python对象
python创建和控制的实体称为“对象”,它们可以是变量、数组、字符串、函数或结构。
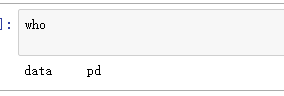
- 查看数据对象
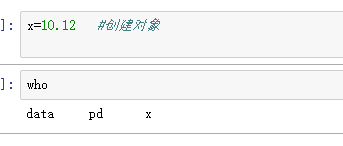
- 生成数据对象
- 删除数据对象
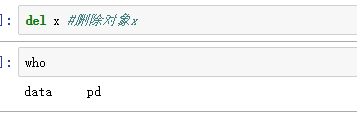
**python对象名称必须是以一个英文字母打头,并由一串大小写字母、数字或下划线组成。
注意:python区分大小写,比如:Orange与orange数据对象是不同的。不要用python的内置函数名作为对象的名称。**
2.数据的基本类型
python的基本数据类型包括数值型、逻辑型、字符型、复数型等,也可能是缺失值。
2.1数值型
数值型数据的形式是实数,可以写成整数(如 n=3)、小数(如 x=1.46)、科学计数法(y=le9)的方式,该类型数据默认是双精度数据。
python支持4中不同的数字类型:
- int(有符号整型)
- long(长整型,也可以代表八进制和十六进制)
- float(浮点型)
- complex(复数)
python中显示数据或对象内容直接用其名称,相当于执行print函数,如下:

2.2逻辑型
逻辑型数据只能取值True或False。
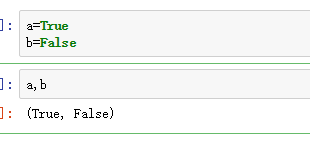
可以通过比较获得逻辑型数据。

2.3字符型
字符型数据的形式是夹在“”或单引号‘’之间的字符串,如‘MR’.
一定要用英文引号,不能用中文引号。python语言中的string(字符串)是由数字、字母、下划线组成的一串字符。一般形式为:
s = ‘I love python’
另外, Python字符串具有切片功能,即从左到右索引默认从0开始,最大范围是字符串长度减一(左闭右开):从右到左索引默认从-1开始。如果要实现从字符串中获取段子字符串,可以使用变量头下标:尾下标],其中下标从0开始算起,可以是正数或负数,也可以为空,表示取到头或尾。比如,上例中s[8]的值是p, s[3:7]的结果是love.
加号(+)是字符串连接运算符,星号(*)是重复操作。

2.4缺失值
有些统计资料是不完整的。当一个元素或值在统计的时候是“不可得到”或“缺失值”的时候,相关位置可能会被保留并且赋予一个特定的nan (not available number,不是一个数)值。任何nan的运算结果都是nano如flat(‘nan’)就是一个实数缺失值。
2.5数据类型转换
有时,需要对数据内置的类型进行转换。数据类型的转换,只须将数据类型作为函数名即可。以下几个内置的函数可以实现数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。下面列出几种常用的数据类型转换方式:
- int(x [,base]) #将x转换为一个整数
- float(x) #将x转换为一个浮点数
- str(x) #将对象x转换为字符串
- chr(x) #将一个整数转换为一个字符
Python的所有数据类型都是类,可以通过type()函数查看该变量的数据类型。
3.标准数据类型
在内存中存储的数据可以有多种类型,例如,一个人的年龄可以用数字来存储,名享可以用字持来存储. Python定义了一些标准失型,用于存储各种类型的数据。这些标准的数据类型是由前述基本类型构成的。
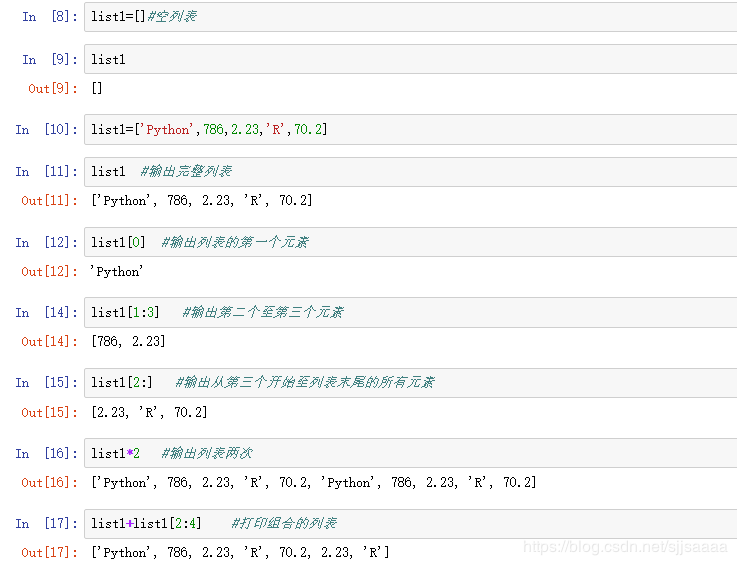
3.1list(列表)
list (列表)是Python中使用最频繁的数据类型。列表可以完成大多数集合类的数据结构实现。它支持字符、数字、字衬串,甚至可以包含列表(即嵌套),列表用1标识是一种最通用的复合数据类型. Python的列表也具有切片功能,列表中值的切割也可以用到变量[头下标:尾下标],可以截取相应的列表,从左到右索引默认从0开始,从右到左索引默认从-1开始,下标可以为空,表示取到头或尾。
加号+是列表连接运算符,星号*是重复操作,操作方法类似字符串。
列表list是进行数据分析的基本类型,所以必须掌握。
3.2tuple(元组)
元组是另一种数据类型,类似于list(列表)。元组用"()"标识,内部元素用逗号隔开。元组不能赋值,相当于只读列表。操作类似列表。
3.3dictionary(字典)
字典也是一种数据类型,且可存储任意类型对象。字典的每个键值对用冒号":“分隔,每个键值对之间用逗号”,”分隔,整个字典包括在花括号1中,格式如下:
dict={key1 : value1 , key2 : value2}
键必须是唯一的,但值则不必,值可以取任何数据类型,如字符串、数字或元组。
字典是除列表外Python中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典中的元素是通过键来存储,而不是通过下标存取。

三、数值分析包 numpy
在使用numpy包前,须加载其到内存中,语句 import numpy,通常简化为:
import numpy as np
1.一维数组(向量)
下面是使用Python的numpy包对一维数组或向量的基本操作。

2.二维数组(矩阵)
下面是使用Python的numpy包构建二维数组或矩阵的基本函数。

3.数组的操作
下面是对数组操作的一些常用函数
3.1数组的维度

3.2空数组

3.3零数组

3.4 '1’数组

3.5单位矩阵

四、数据分析包pandas
在数据分析中,数据通常以变量(一维数组,Python中用序列表示)和矩阵(二维数组,Python中用数据框表示)的形式出现,下面结合Python介绍pandas基本的数据操作。
注意:在Python编程中,变量通常以列表(一组数据),而不是一般编程语言的标量(一个数据)形式出现。
1.序列Series
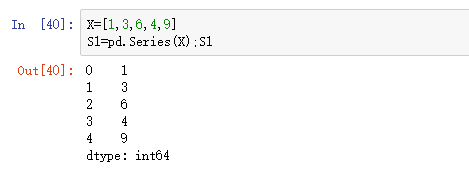
1.1创建序列(向量、一维数组)
假如要创建一个含有n个数值的向量X=(x1,x2…xn),Python中创建序列的函数是列表,这些向量可以是数字型,也可以是字符串型的,还可以是混合型的。
1.2生成序列

1.3根据列表构建序列
1.4序列合并
![]()
1.5序列切片
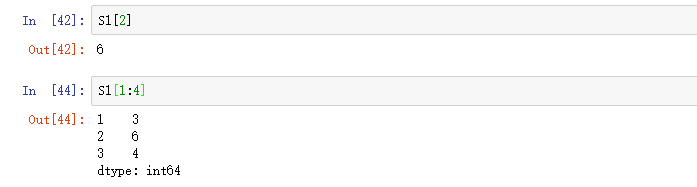
2.数据框DataFrame
pandas中的函数DataFrame()可用序列构成一个数据框。数据框相当于关系数据库中的结构化是数据类型,传统的数据大都可以以结构化数据形式存储于关系数据库中,因而传统的数据分析是以数据框为基础的。
-
生成数据框
pd.DataFrame() -
根据列表创建数据框
pd.DataFrame(X)
pd.DataFrame(X,columens=['X'],index=range(5) -
根据字典创建数据框
df1=pd.DataFrame({'S1':S1,'S2':S2,'S3',S3};df1 -
增加数据框列
df2=pd.DataFrame({'sex':sex,'weight':weight},index=X);df2 -
删除数据框列
del df2['weight'];df2 #删除数据列 -
缺失值处理
df3=pd.DataFrame({'S2':S2,'S3':S3},index=S1);df3
df3.isnull() #若是缺失值则返回True,否则返回False
df3.isnull().sum() #返回每列包含的缺失值个数
df3.dropna() #直接删除含有缺失值的行,多变量谨慎使用 -
数据框排序
df3.sort_index() #按index排序
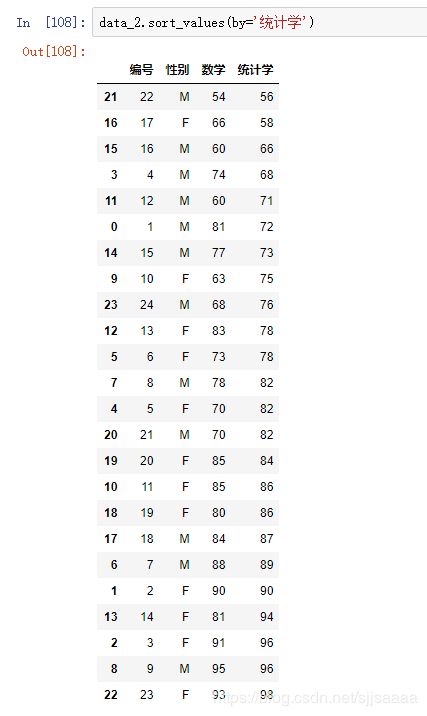
df.3sort_values(by='S3') #按列值排序
3.数据框的读写
3.1pandas读取数据集
大的数据对象常常是从外部文件读入,而不是在python中直接输入的。
下面会用到的数据:这里下载:PyDm_data.xlsx
- 从剪切板上读取
data= pd.read_clipboard(); #从剪切板上复制数据
data[:5
data为读入python中的数据框名,clipboard为剪切板。
- 读取csv格式数据
data=pd.read_csv("D://PyDm_data.xlsx",encoding='utf-8') #注意中文格式
data[6:9]
- 读取excel格式数据
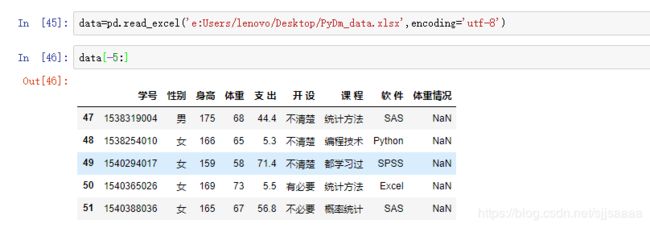
4. 读取其他统计软件的数据
要调用SAS、SPSS、Stata等统计软件的数据集,须先用相应的包。
3.2数据集的保存
Python读取和保存数据集最好方式是csv和xlsx文件格式。
data.to_csv('data1.csv' #将数据框data保存到data1.csv中
data.to_excel('data2.xlsx',index=False) #将数据框data保存到data2.xlsx中
4.数据框的操作
4.1获取数据框的基本信息
- 数据框显示
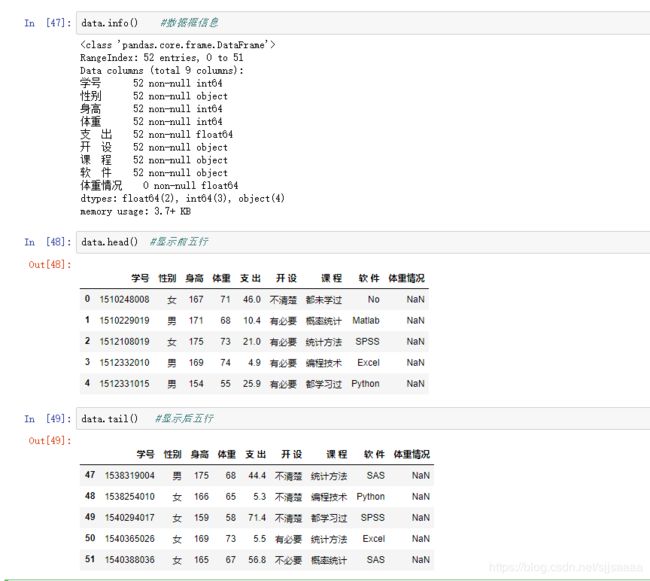
-
数据框列明(变量名)

-
数据框行名(样品名)

-
数据框维度

-
数据框值(数组)

4.2选取变量
- “."法或[’’]
获取一列数据:
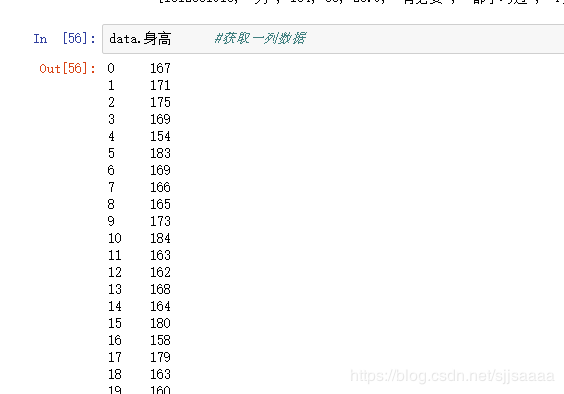
获取两列数据:

- 下标法
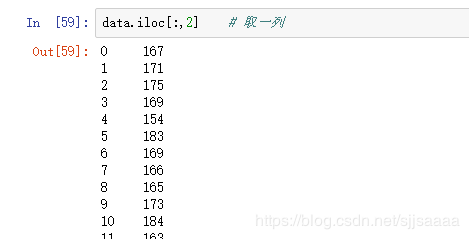
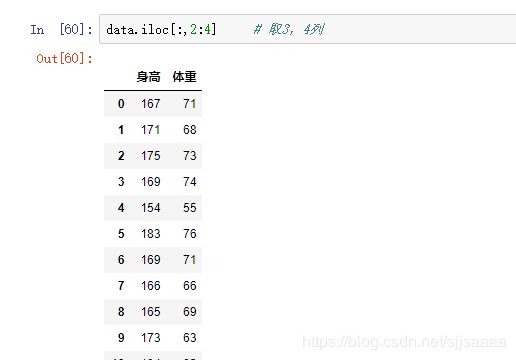
4.3提取样品

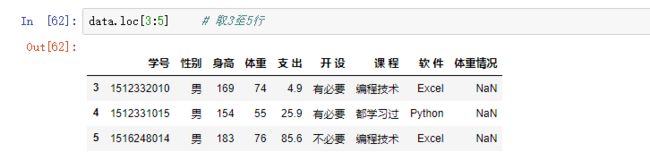
4.4选取观测与变量
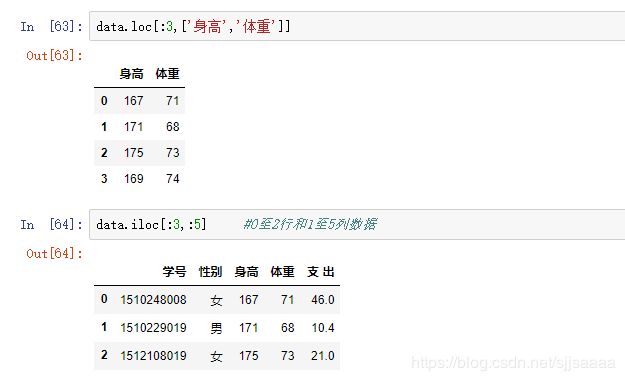
4.5根据条件选取样品与变量
选取身高超过180cm的男生的数据。
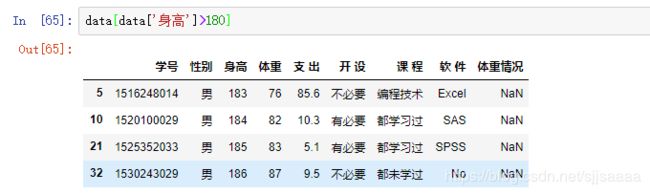
身高超过180且体重小于80kg的数据。

4.6数据框的运算
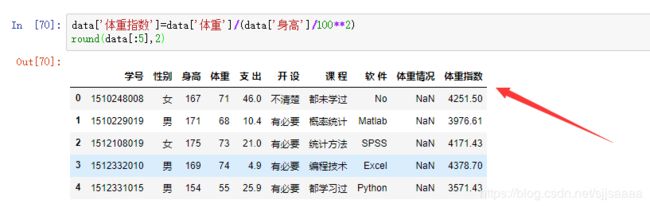
- 生成新的数据框
可以通过选择变量名来生成新的数据框
- 数据框的合并 pd.concat()
可以用pd.concat() 函数将两个或两个以上的向量、矩阵或数据框合并起来,参数axis=0表示按行合并,axis=1表示按列合并。

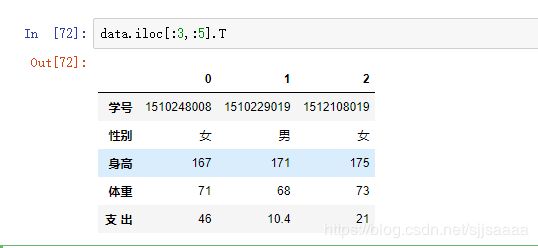
4.7数据框转置(.T)
三、python编程运算
1.基本运算
与Basic语言、VB语言、C语言、C++语言等一样,Python 语言具有编程功能,具有面向对象的功能,还是面向函数的语言。
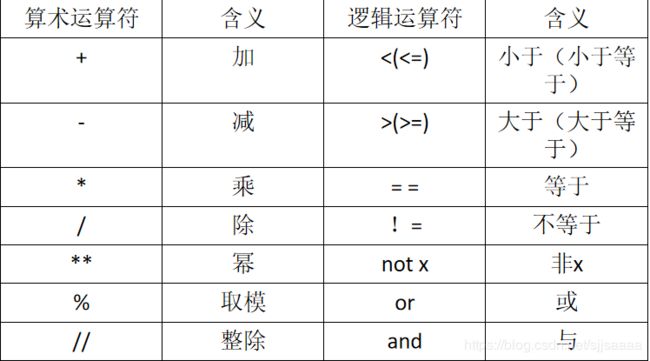
python中常用的算数运算符和逻辑运算符:
2.控制语句
2.1循环语句for
语法:
for i in range(x):
print(i)
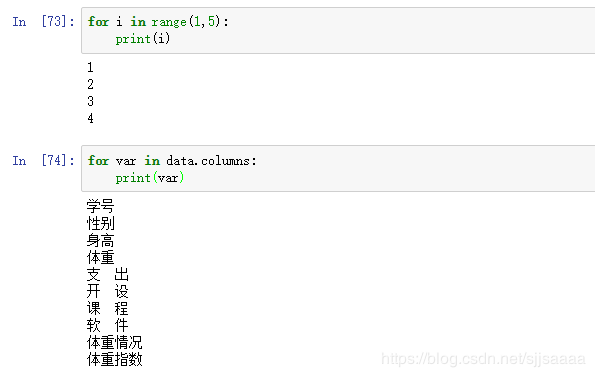
2.2 条件语句 if/else

注意:循环和条件等语句中要输出结果,请用prit()函数,这时只用变量名是无法显示的。
3函数定义
定义函数语法:
def 函数名(参数1,参数2,...):
函数体
return
python中常用的数学函数:
| math中的数学函数 | 含义(针对数值) |
|---|---|
| abs(x) | 数值的绝对值 |
| sqrt(x) | 数值的平方根 |
| log(x) | 数值的对数 |
| exp(x) | 数值的值数 |
| round(x,n) | 有效位数n |
| sin(x),cos(x),… | 三角函数 |
| numpy中数学函数 | 含义(针对数组) |
|---|---|
| len(x) | 数组中元素个数 |
| sum(x) | 数组中元素求和 |
| prod(x) | 数组中元素求积 |
| min(x) | 数组中元素最小值 |
| max(x) | 数值中元素最大值 |
| sort(x) | 数值中元素排序 |
| rank(x) | 数组中元素秩次 |
函数名可以是任意字符,但之前定义过的要小心使用,后定义的函数会覆盖先定义的函数。
注意:如果函数只用来计算,不需要返回结果,则可在函数中用print()函数,这时只用变量名是无法显示结果的。
4.面向对象
Python是一种面向对象的语言。

列表的用法:

向量、矩阵和数组的元素必须是同一类型的数据对象。
列表中对象的成分访问与变量和数据基本一样,可以用下表获取,但不完全一样。

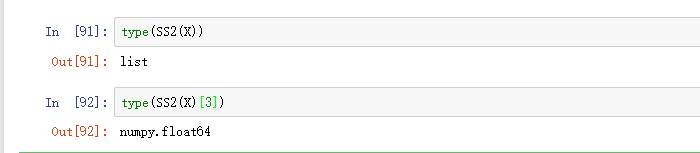
可以使用type()函数来查看数据或对象的类型。
练习题:
学生成绩:从某大学统计系的学生中随机抽取24人,对数学和统计学的考试成绩进行调查,数据如下:
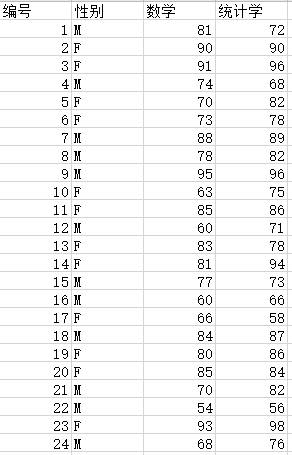
(1)用python的read_csv() 和resd_excel()函数读取。
(2)用python的方法获取性别、数学和统计学成绩变量,并筛选不同性别学生的成绩。
(3)用python分别对性别、数学或统计学成绩排序。
注:数据资源点这里——>数据资源下载
解:
1.

2.
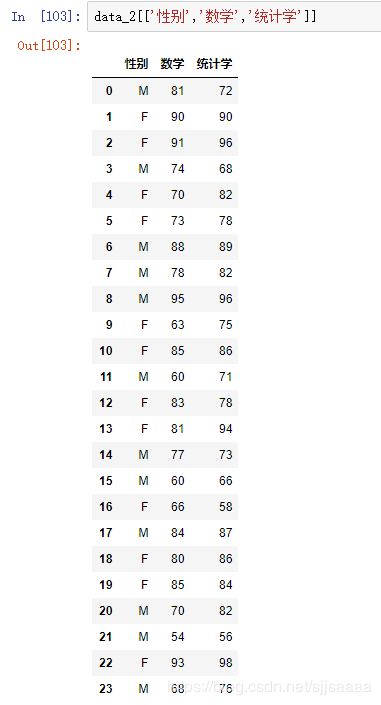
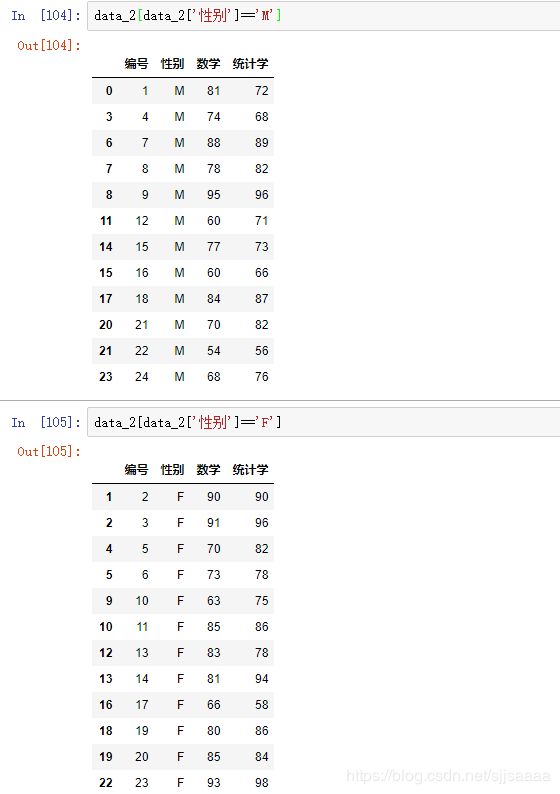
3.
按性别排序:
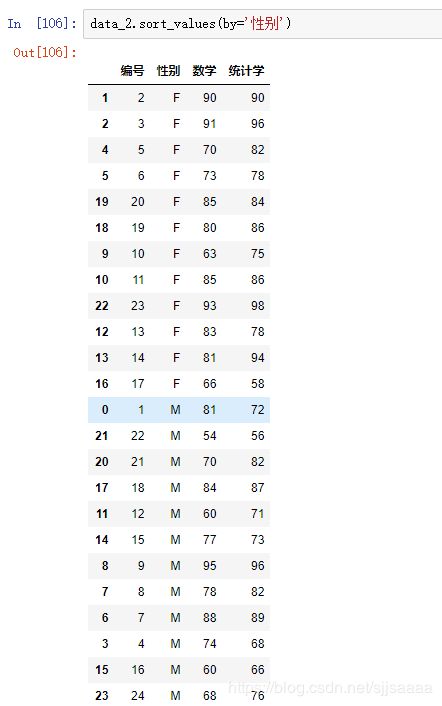
按数学排序:
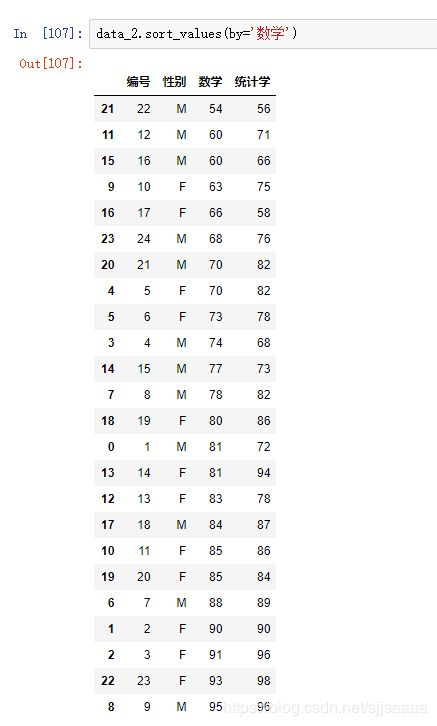
按统计学成绩排序: