Inception-V4和Inception-Resnet论文阅读和代码解析
目录:
论文阅读
代码解析
小结
论文阅读
论文地址:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
此论文主要是作者尝试将inception与residual结合,而提出了inception-resnet-v1和inception-resnet-v2网络,并且为了比较inception与resnet结合后是否真的对网络性能有提升而提出了一个inception-v4网络进行对比。试验证明residual能够加速inception网络的训练,并且精度上有少量的提升。
1.介绍
这篇论文的主要思想就是将residual和inception结构相结合,以获得residual带来的好处。
在直接集成这两个思想之前,作者也研究了能否将inception变得更深更宽使其更高效,因为这个原因作者设计了新版本的inception,叫做inception-v4。Inception-v4有更多简化的模型,并且比Inception-v3有更多的inception block。
在这个报告里面,作者会用两个纯inception网络inception-v3和inception-v4和混合的inception-resnet网络进行比较。另外还测试了更大更宽的inception-resnet网络,发现他们的表现都非常相似。
2.相关工作
残差网络的作者认为训练很深的网络时使用残差链接是非常中要的,但是本文的作者说很深的网络即使不使用残差连接,训练网络也并不难,但是使用了残差网络训练速度会大大加快。另外作者还提到了inception的第一代第二代和第三代之间的改进。
3.纯Inception block
Inception的结构是很容易调节的,就是说改变一些fitler最终并不会影响结果。但是作者为了优化训练速度小心的调整了每一层的大小。现在因为tensorflow的优化功能,作者认为不需要再像以前一样根据经验小心的调整每一层,现在可以更加标准化的设置每一层的参数。而提出了Inception-V4,网络结构如下:

具体每个block对应的细节很容易从论文中找到,这里面就不一一贴出了。可以看到很明显的,网络可以很清晰的划分为一个一个block,而且Inception的block都是重复使用,因为它的input和output尺寸是一样的。Reduction主要是用来降低feature map的尺寸。另外每个block中没有标记v的都表示same padding。
4.Residual Inception Block
作者尝试了很多种residual inception block的结构,但是这里只会列出来两种。一种是Inception-Resnet-V1,它的计算量和Inception-V3相当。另一种是Inception-Resnet-V2,它的计算量和新提出来的Inception-V4相当。结构如下:

上图显示了Inception-ResNet-v1和Inception-ResNet-v2两种Inception-Resnet结构。他们总体结构一致,里面的block不同。
对有residual和没有residual的网络在技术上有个小差别。对于Inception-Residual的模块,在做相加的那一层不做batch normalization,这是作者从计算消耗上的考虑。
5.缩小残差
作者发现如果filter的个数超过1000个,残差网络会变得不稳定,网络会在训练的早期就‘死掉’,也就意味着在几万次迭代之后,avg_pool之前的最后几层网络参数全是0。解决方案是要么减小learning rate,要么对这些层增加额外的batch normalization.
作者又发现如果将残差部分缩放后再跟需要相加的层相加,会使网络在训练过程中更稳定。因此作者选择了一些缩放因子在0.1到0.3之间,用这个缩放因子去缩放残差网络,然后再做加法,如下图
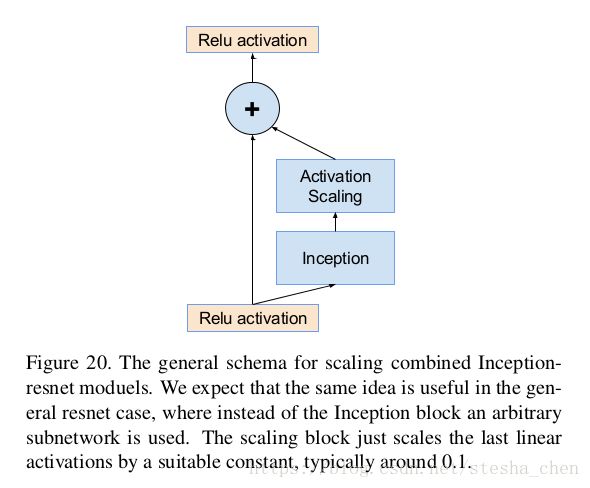
在VGG的论文中也曾提到过类似的问题,当时作者说开始用很小的learning rate来进行训练,一段时间后再用比较大的learning rate。但是此文作者发现即使用0.00001这么小的learning rate也不能让网络稳定,使用缩放因子会更靠谱。
使用缩放因子并不是严格需要的,它对网络没有害处,会帮助网络训练更加稳定。
6.网络比较
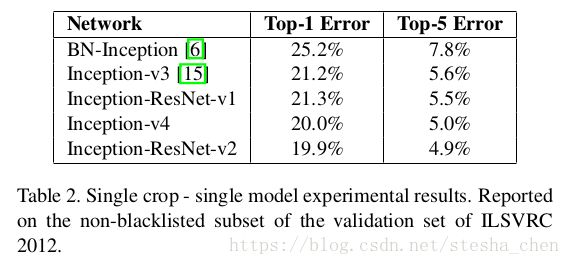
论文中提供的数据可以看出Inception-V4和Inception-ResNet-V2的差别并不大,但是都比Inception-V3和Inception-ResNet-V1都好很多。
代码解析
tensorflow源码中只实现了Inception-v4和Inception-Resnet-V2,Inception-Resnet-V1只是一个中间件的结构用来做比较。
Inception-V4和Inception-Resnet-V2的总体结构是比较像的,都是一个stem加上多次重复的Inception或者Inception-Resnet block,然后后面再连接reduction,然后重复这样的结构几次。代码的实现上也完全是以block为单位来实现,同类型的block实现也是非常的类似。
Inception-V4代码实现
Inception-v4代码中的函数命名如下:
def block_inception_a(inputs, scope=None, reuse=None):
"""Builds Inception-A block for Inception v4 network.""
def block_reduction_a(inputs, scope=None, reuse=None):
"""Builds Reduction-A block for Inception v4 network."""
def block_inception_b(inputs, scope=None, reuse=None):
"""Builds Inception-B block for Inception v4 network."""
def block_reduction_b(inputs, scope=None, reuse=None):
"""Builds Reduction-B block for Inception v4 network."""
def block_inception_c(inputs, scope=None, reuse=None):
"""Builds Inception-C block for Inception v4 network."""
def inception_v4_base(inputs, final_endpoint='Mixed_7d', scope=None):
"""Creates the Inception V4 network up to the given final endpoint.
def inception_v4(inputs, num_classes=1001, is_training=True,
dropout_keep_prob=0.8,
reuse=None,
scope='InceptionV4',
create_aux_logits=True):
"""Creates the Inception V4 model.下面以block_inception_a和block_reduction_a和inception_v4_base为例来看一下inception-v4 block的代码实现。
1. block_inception_a
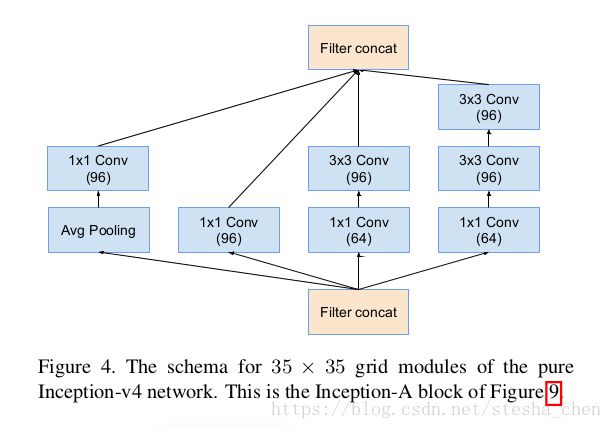
代码的实现就是依赖上图的结构,实现也是非常简单。分成4个分支,branch_0对应上图从左到右第二个分支,branch_1对应第上图三个分支,branch_2对应上图第四个分支,branch_3对应上图第一个分支。所有的padding都是same,stride都为1。所以feature map的size不会发生变化,最后得到的feature map是35 x 35 x 384。
def block_inception_a(inputs, scope=None, reuse=None):
"""Builds Inception-A block for Inception v4 network."""
# By default use stride=1 and SAME padding
with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope(scope, 'BlockInceptionA', [inputs], reuse=reuse):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(inputs, 96, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(inputs, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(inputs, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(inputs, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 96, [1, 1], scope='Conv2d_0b_1x1')
return tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])2.block_reduction_a
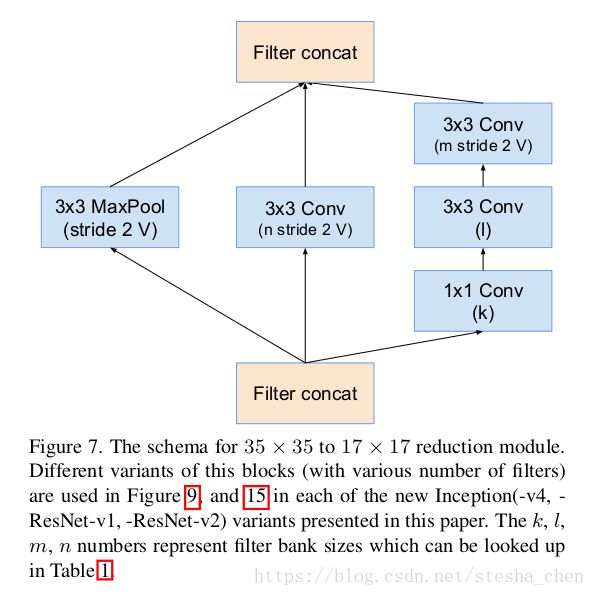
代码是依据上图模型来实现的,这里的k为192, l为224,m为256,n为384。branch_0对应上图的第二个分支,branch_1对应上图的第三个分支,branch_2对应上图的第一个分支。因为最后一层的padding都为valid,并且stride为2,所以feature map的size会减半,最后feature map的尺寸为17 x 17 x 1024。
def block_reduction_a(inputs, scope=None, reuse=None):
"""Builds Reduction-A block for Inception v4 network."""
# By default use stride=1 and SAME padding
with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope(scope, 'BlockReductionA', [inputs], reuse=reuse):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(inputs, 384, [3, 3], stride=2, padding='VALID',
scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 224, [3, 3], scope='Conv2d_0b_3x3')
branch_1 = slim.conv2d(branch_1, 256, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(inputs, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
return tf.concat(axis=3, values=[branch_0, branch_1, branch_2])3.inception_v4_base
此函数主要有两部分内容,一部分是实现了stem结构,第二部分是实现了inception block的重复调用。
论文中stem的结构图如下,代码就是按照论文中的结构图实现的,比较简单。
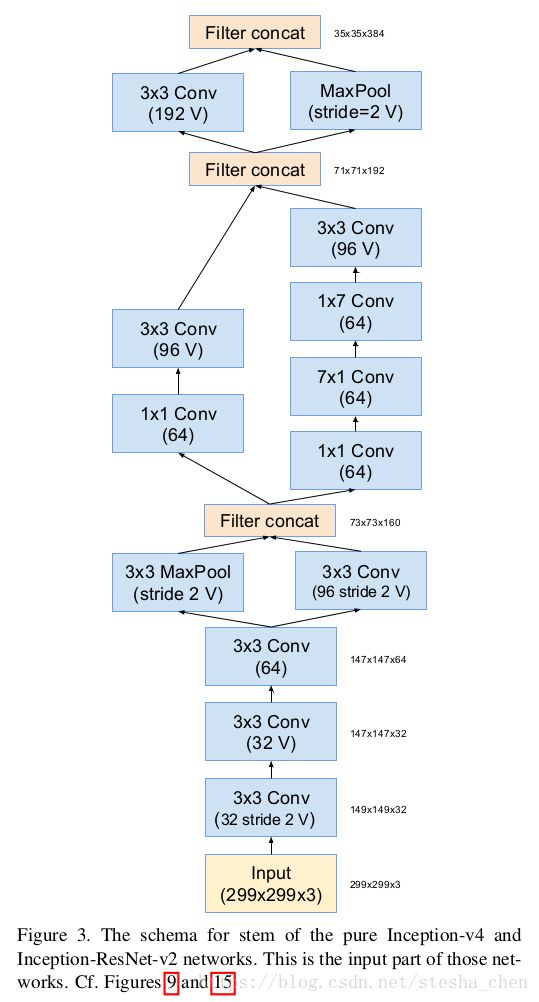
接着是inception block与reduction block的部分
# 35 x 35 x 384
# 4 x Inception-A blocks
for idx in range(4):
block_scope = 'Mixed_5' + chr(ord('b') + idx)
net = block_inception_a(net, block_scope)
if add_and_check_final(block_scope, net): return net, end_points
# 35 x 35 x 384
# Reduction-A block
net = block_reduction_a(net, 'Mixed_6a')
if add_and_check_final('Mixed_6a', net): return net, end_points根据论文中inception-v4的结构,Inception-A block需要重复4次后连接Reduction-A block,重复的部分就用了一个循环实现。后面其他的block也是类似的实现和调用方法。
Inception-Resnet-V4代码实现
Inception-Resnet-V4的代码实现和Inception-V4类似。网络结构中的Inception-resnet-A在函数block35中实现,表示feature map的尺寸是35 x 35。网络结构中的Inception-resnet-B在函数block17中实现,Inception-resnet-C在函数block8中实现。而Reduction-A和Reduction-B都在inception_resnet_v2_base中实现。
1.block35
论文中Inception-resnet-A的结构如下
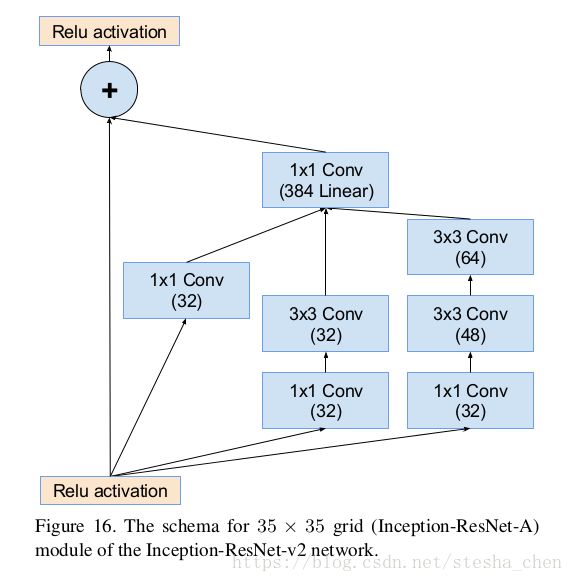
代码实现就是concat branch_0 branch_1 branch2三个分支的结果,然后进行一个1x1的卷积运算,接着用一个scale因子(论文阅读的时候提到过)进行缩放,最后跟input的值相加。
def block35(net, scale=1.0, activation_fn=tf.nn.relu, scope=None, reuse=None):
"""Builds the 35x35 resnet block."""
with tf.variable_scope(scope, 'Block35', [net], reuse=reuse):
with tf.variable_scope('Branch_0'):
tower_conv = slim.conv2d(net, 32, 1, scope='Conv2d_1x1')
with tf.variable_scope('Branch_1'):
tower_conv1_0 = slim.conv2d(net, 32, 1, scope='Conv2d_0a_1x1')
tower_conv1_1 = slim.conv2d(tower_conv1_0, 32, 3, scope='Conv2d_0b_3x3')
with tf.variable_scope('Branch_2'):
tower_conv2_0 = slim.conv2d(net, 32, 1, scope='Conv2d_0a_1x1')
tower_conv2_1 = slim.conv2d(tower_conv2_0, 48, 3, scope='Conv2d_0b_3x3')
tower_conv2_2 = slim.conv2d(tower_conv2_1, 64, 3, scope='Conv2d_0c_3x3')
mixed = tf.concat(axis=3, values=[tower_conv, tower_conv1_1, tower_conv2_2])
up = slim.conv2d(mixed, net.get_shape()[3], 1, normalizer_fn=None,
activation_fn=None, scope='Conv2d_1x1')
scaled_up = up * scale
if activation_fn == tf.nn.relu6:
# Use clip_by_value to simulate bandpass activation.
scaled_up = tf.clip_by_value(scaled_up, -6.0, 6.0)
net += scaled_up
if activation_fn:
net = activation_fn(net)
return netblock17和block8也是同样的实现方式。不过resnet结构需要注意一点,就是scaled_up的shape和input的shape必须完全一样才能相加。论文中是有一些错误的,比如从Inception-A出来后feature map的size是17 x 17 x 1152,所以Inception-resnet-B的scaled_up尺寸必须是同样的,但是论文中channel写的是1154,这样会导致无法相加。
另外tensorflow中的实现跟论文有稍微的差别,在channel的数值上做了些微的调整。
2.inception_resnet_v2_base
整个网络的搭建就是在inception_resnet_v2_base中实现的,代码很容易阅读。
inception-resnet block的重复部分用了slim的repeat接口,就是重复调用10次。
net = slim.repeat(net, 10, block35, scale=0.17,
activation_fn=activation_fn)
小结
总的来说Inception V4的论文很容易读,代码实现也是非常简单,而且Inception v4和inception resnet v2的精度也很不错,是非常成熟的网络,如果部署分类网络的应用可以优先考虑使用这两种网络。