LaneNet代码实现细节以及遗留问题
最近比较忙很久没有维护这里了,可能还是有很多人会有问题,我重新提交了git,地址是https://github.com/stesha2016/lanenet-enet-hnet,如果有问题可以在git上提交,可以一起讨论下。现在这个项目还有一些工作需要继续:
1.聚类的点太多会导致聚类耗时太长,不能达到真正实时的效果。
2.在CULane的数据集上进行训练和测试。
3.可以考虑结合CULane中提到的卷积方式,增强backbone的表达力。
本文的代码分析是针对论文《Towards End-to-End Lane Detection: an Instance Segmentation Approach》,我们看论文会发现论文中很难提供所有的代码实现细节,如果作者好心提供了源代码,那么对照源码就可以看出关于所有细节的处理。但是如果作者没有提供源代码,单从论文上来复现,很大的可能会遇到一系列的小问题,会在一些细节的点上被卡住,而没有办法完美复现论文中的效果。
github上有人对这篇论文进行了复现,代码地址实现了论文中大概70%的内容吧,以这个工程的代码为主导来看论文代码的实现。
论文中提到了两部分网络,一个是lanenet,做车道预测,一个是hnet做车道拟合。
Lanenet
LaneNet网络分为两个分支,论文中的segmentation branch是做二分分类判断是否是车道线,对应的就是代码中的binary segmentation;论文中的embedding branch是为了区分不同的车道线,对应的就是代码中的instance segmentation。代码中将这两部分branch的名字稍作改变确实比较好理解。
Binary segmentation
Binary网络
Binary segmentation的backbone部分代码实现了vgg和dense两种网络结构,实际上与论文中的ENet不一样,建议还是要使用ENet作为backbone,因为vgg和dense肯定都无法达到real time的效果。
我参考github上的enet,将Binary segmentation的backbone替换成了enet。
从论文中我们知道Binary这个分支和Instance这个分支公用ENet的前两个stage,后面三个stage是各自不同的。
# shared stages
with tf.variable_scope('LaneNetBase'):
initial = enet_stage.iniatial_block(input_tensor, isTraining=self._phase)
stage1, pooling_indices_1, inputs_shape_1 = enet_stage.ENet_stage1(initial, isTraining=self._phase)
stage2, pooling_indices_2, inputs_shape_2 = enet_stage.ENet_stage2(stage1, isTraining=self._phase)
# Segmentation branch
with tf.variable_scope('LaneNetSeg'):
segStage3 = enet_stage.ENet_stage3(stage2, isTraining=self._phase)
segStage4 = enet_stage.ENet_stage4(segStage3, pooling_indices_2, inputs_shape_2, stage1, isTraining=self._phase)
segStage5 = enet_stage.ENet_stage5(segStage4, pooling_indices_1, inputs_shape_1, initial, isTraining=self._phase)
segLogits = tf.layers.conv2d_transpose(segStage5, 2, [2, 2], strides=2, padding='same', name='fullconv')这部分替换backbone的代码部分不难实现。网络的output的tensor的尺寸是[width, height, 2],channel 2表示的是每个点是属于背景还是车道的概率。
Binary Loss
在说到loss之前我们必须要知道ground truth是什么,Binary的gt其实就是一张二值化的图片,车道部分显示白色,背景显示黑色。

这种gt image是由tusimple数据中json文件生成的,将json文件中每条车道的点进行拟合画出来的曲线。处理的脚本可以参考generate_tusimple_dataset.py,但是这个文件中稍微有点问题,没有过滤掉tusimple数据集中没有标记的图片。需要自己稍微修改一下。
然后在计算loss之前将这张gt image除以255得到gt label,那么黑色部分就是0, 白色部分就是1。这样很明显,loss函数就是生成的tensor与这个gt label在channel维度的cross entropy。
稍微有点特别之处是因为正负样本的比例极度的不平衡,所以需要计算正负样本的比例来给他们的crossentropy加上权重。
# 计算二值分割损失函数
binary_label_plain = tf.reshape(
binary_label,
shape=[binary_label.get_shape().as_list()[0] *
binary_label.get_shape().as_list()[1] *
binary_label.get_shape().as_list()[2]])
# 加入class weights
unique_labels, unique_id, counts = tf.unique_with_counts(binary_label_plain)
counts = tf.cast(counts, tf.float32)
inverse_weights = tf.divide(1.0,
tf.log(tf.add(tf.divide(tf.constant(1.0), counts),
tf.constant(1.02))))
# inverse_weights = tf.concat([tf.constant([5.]), inverse_weights[1:]], axis=0)
inverse_weights = tf.gather(inverse_weights, binary_label)
binary_segmenatation_loss = tf.losses.sparse_softmax_cross_entropy(
labels=binary_label, logits=decode_logits, weights=inverse_weights)
binary_segmenatation_loss = tf.reduce_mean(binary_segmenatation_loss)另外我在训练的时候发现如果从头训练起Binary分支的准确率会降到很低,所以我尝试过自己调整正负样本的比例来进行训练,训练的效果也还不错。
Instance segmentation
Instance网络
上面说过了,与Binary branch公用stage1和stage2,使用自己的stage3/4/5.
# shared stages
with tf.variable_scope('LaneNetBase'):
initial = enet_stage.iniatial_block(input_tensor, isTraining=self._phase)
stage1, pooling_indices_1, inputs_shape_1 = enet_stage.ENet_stage1(initial, isTraining=self._phase)
stage2, pooling_indices_2, inputs_shape_2 = enet_stage.ENet_stage2(stage1, isTraining=self._phase)
# Embedding branch
with tf.variable_scope('LaneNetEm'):
emStage3 = enet_stage.ENet_stage3(stage2, isTraining=self._phase)
emStage4 = enet_stage.ENet_stage4(emStage3, pooling_indices_2, inputs_shape_2, stage1, isTraining=self._phase)
emStage5 = enet_stage.ENet_stage5(emStage4, pooling_indices_1, inputs_shape_1, initial, isTraining=self._phase)
emLogits = tf.layers.conv2d_transpose(emStage5, 4, [2, 2], strides=2, padding='same', name='fullconv')网络output的tensor是[width, height, 4],可以看成是图片每个像素点上是4个数字,后面会用这四个数字进行聚类。
Instance Loss
首先来看gt image

对不同的车道标记上不同的颜色。我们根据这个图片上的不同车道的位置,可以得到网络的输出tensor中的不同车道的像素位置。
Instance的loss由两部分组成:
- 同一车道内的loss,先计算出tensor中属于同一车道的位置上的值的均值,然后希望同一车道位置上的值与这个均值的L2差值不大于0.5
- 不同车道的loss,先计算tensor中每一条车道的均值,然后希望不同车道的均值的L2差值大于3.0
这样的目的都是为了后面预测的可以很轻松的聚类出不同车道。
在lanenet_discriminative_loss.py中可以看到代码的实现,主要是用到了一些矩阵的处理的技术。

预测
当我们把上面两个分支的loss相加后,就可以开始训练网络了。当网络训练好后我们运行网络可以得到两张图片,一张Binary一张Instance


然后我们用预测出来的Binary的图片去覆盖Instance的图片,这样可以在Instance图片中找到所有车道的点的位置,然后把这些点的值(这里的值是4个数字为一组,因为我们生成的Instance是[w, h, 4])取出来进行聚类。
ms = MeanShift(bandwidth, bin_seeding=True)
ms.fit(prediction)
labels = ms.labels_得到的labels就是已经分好类的车道点,现在不考虑HNet,将不同的车道点用不同颜色标记出来,可以得到
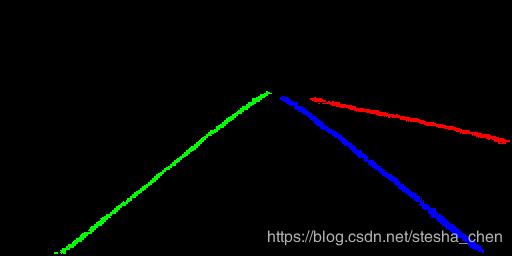
遗留的问题
似乎lanenet网络相关的功能都实现了,但是其实有和论文中不一样的地方。
第一点不同:
论文中Instance分支的预测图是这样的,似乎是将两条车道线中的车道部分都进行了划分,才能得到这个效果,这样做的好处是不会在上图的预测图出现蓝色点旁边还夹杂着一点绿色的干扰,或者红色的干扰。我之前的训练中会出现这种现象,不过把代码中gt_binary的线条画细了一点,把gt_instance中的线条画粗了一点后这个现象就出现的比较少了。

第二点不同:
达不到论文中的速度要求,瓶颈在聚类部分,因为我们通过binary挑选出来的点大概有4000个左右,进行聚类需要消耗40ms以上的时间,这显然不够快。我想解决方法应该是把这4000多个点进行筛选,或者进行随机的抛弃来降低点的数量,如果点很少,我们后续使用多项式拟合也可以很好的把线条画出来。下面这幅图的聚类大概消耗20ms,但是这种方法可能会对Hnet的曲线拟合带来随机性,并不是太合适的方法。
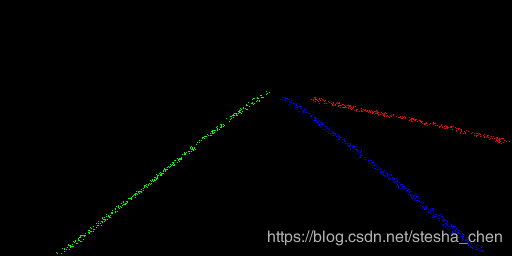
HNet
HNet的代码实现还存在很大的问题,达不到论文中的效果。
网络
网络比较简单,就是几层卷积加上全连接,最后输出6个数字
conv_stage_1 = self._conv_stage(inputdata=input_tensor, out_channel=16, name='conv_stage_1')
conv_stage_2 = self._conv_stage(inputdata=conv_stage_1, out_channel=16, name='conv_stage_2')
maxpool_1 = self.maxpooling(inputdata=conv_stage_2, kernel_size=2, stride=2, name='maxpool_1')
conv_stage_3 = self._conv_stage(inputdata=maxpool_1, out_channel=32, name='conv_stage_3')
conv_stage_4 = self._conv_stage(inputdata=conv_stage_3, out_channel=32, name='conv_stage_4')
maxpool_2 = self.maxpooling(inputdata=conv_stage_4, kernel_size=2, stride=2, name='maxpool_2')
conv_stage_5 = self._conv_stage(inputdata=maxpool_2, out_channel=64, name='conv_stage_5')
conv_stage_6 = self._conv_stage(inputdata=conv_stage_5, out_channel=64, name='conv_stage_6')
maxpool_3 = self.maxpooling(inputdata=conv_stage_6, kernel_size=2, stride=2, name='maxpool_3')
fc = self.fullyconnect(inputdata=maxpool_3, out_dim=1024, use_bias=False, name='fc')
bn = self.layerbn(inputdata=fc, is_training=self._is_training, name='bn')
fc_relu = self.relu(inputdata=bn, name='fc_relu')
output = self.fullyconnect(inputdata=fc_relu, out_dim=6, name='fc_output')HNet Loss
由网络输出的6个数组组成论文中的转换矩阵H,然后将gt的车道点通过H转换后,使用最小二乘法拟合后,根据拟合曲线调整x的坐标,然后反向转换到原图中,将反向转换的x与原x组成一个MSE loss。
整个思路很简单,但是实施起来有很多细节需要注意,否则经常会遇到矩阵不可逆的错误。
- HNet的网络的input是128x64,而我们从json中读取出来的坐标点是以1280x720为坐标单位的,所以我们需要把坐标点转换为128x64的坐标系,按比例缩放就好了。
- 最好自己先计算一张图片的H矩阵,然后将网络先做一些简单的训练,使预测的矩阵接近我们计算的H矩阵作为预训练。后面训练Hnet将学习率调整的特别小来微调预测矩阵。
- 我们看图像的透视转换原理,通过H矩阵转换后的数值是
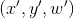 ,但是其实真实的坐标是
,但是其实真实的坐标是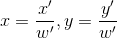 ,根据论文中提到的转换后的数值似乎都是
,根据论文中提到的转换后的数值似乎都是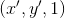 所以计算后的真实坐标需要用x'和y'除以
所以计算后的真实坐标需要用x'和y'除以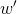 。
。
HNet拟合后的效果
