Spark大数据分析-ML:分类和聚类
目录
- Spark ML库
- Estimators、transformers和evaluators
- ML参数
- ML管道
- 逻辑回归
- 二元逻辑回归模型
- 准备数据以使用Spark中的逻辑回归
- 处理缺失值
- 处理类别值
- 使用StringIndexer
- 使用OneHotEncoder编码数据
- 使用VectorAssembler
- 训练模型
- 评估分类模型
- 使用BinaryClassificationEvaluator
- 精确率和召回率
- 精确率-召回率曲线
- 接受者操作特征曲线
- 执行k折交叉验证
- 多类别逻辑回归
- 决策树和随机森林
- 决策树
- 一个例子
- 理解不纯度与信息增益
- 训练决策树模型
- 检查决策树
- 评估模型
- 随机森林
- 使用k-均值聚类
- k-均值聚类
- 在Spark中使用k-均值聚类
- 评估模型
- 确定簇数
Spark有两个机器学习库:MLlib和ML。它们都在积极发展,但是目前的发展重点更多的是ML库。
Spark ML库
ML相对于MLlib是比较新的机器学习库。创建新的机器学习库的原因是因为MLlib没有足够的伸缩和扩展性,也不足以在实际的机器学习项目中使用。ML的目标是概括机器学习操作和简化机器学习过程。受scikit-learn影响,它引入了可以组合形成管道的新的抽象概念——估计器、转换器和评估器。
ML经常会使用DataFrame对象来呈现数据集,这就是不能简单地升级旧的MLlib算法的原因。
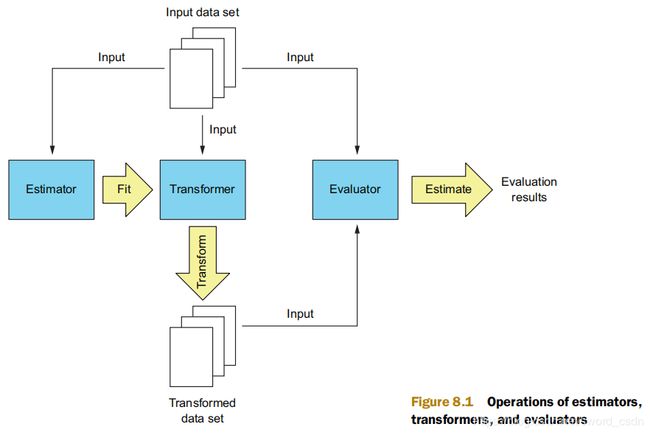
Estimators、transformers和evaluators
在spark中,可以通过使用transformers来实现一个机器学习组件,这个组件可以将一个数据集transform为另一个数据集。Spark ML中的所谓“模型”实际上是一个transformer,只是它需要添加predictions来实现。
Estimators通过拟合数据集创建transformers。
评估器根据单一度量来评估模型的性能。例如回归评估器可以使用RMSE和R2作为度量。
ML参数
在Spark ML中为估计器和转换器指定参数是非常常见的,可以使用Param、ParamPair和ParamMap类来指定它们的参数。
Param包含的参数类型包括:参数名称、类的类型、参数描述、用于验证参数的函数以及可选的默认值。ParamPair包含参数类型(Param对象)以及它的值。ParamMap包含一组ParamPair对象。
将ParamPair或ParamMap对象传递给Estimators的fit或transformers的transform方法,或者可以使用特定的setter方法设置参数。
ML管道
在机器学习中,相同的步骤通常使用稍微不同的参数以相同的顺序重复,从而找到产生最佳结果的参数。例如在《Spark大数据分析-MLlib——线性回归实例》中,每次都会使用不同的参数组合,或者是添加高阶多项式,然后再次进行训练。Spark ML可以创建具有两个阶段的Pipeline对象,第一阶段通过添加高阶多项式来转换数据集,ML中的PolynomialExpansion transformer使用多项式的次数来作为参数。第二阶段进行线性回归分析,将整个管道视为单个估计器,产生一个PipelineModel模型。
PipelineModel模型也有两个阶段:多项式展开和拟合线性回归模型。每次拟合管道时,都会给它一组不同的参数(包括两个阶段的参数ParamMap),然后选择一个可以获得最佳结果的参数集合。
逻辑回归
在《Spark大数据分析-MLlib——线性回归实例》中,有一个例子是预测波士顿郊区的房价。这是一个回归分析的例子,因为这个过程是基于一组输入变量查找一个值。另一方面,分类的目标是将输入示例分类为两个或更多个类。如果想预测房价是否大于某个固定值,可以轻松将房价问题转化为分类问题。
二元逻辑回归模型
在逻辑回归中,不是使用线性方程建模概率p(x),而是用逻辑函数。
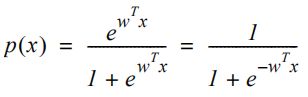
对于两个不同的权重集合w绘制函数的结果如下。
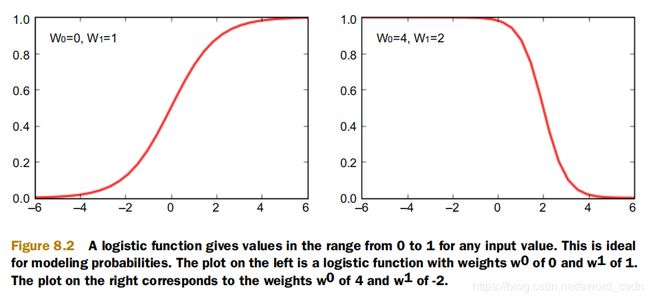
如果进一步操作逻辑函数,可以得到以下等式:
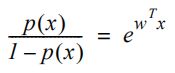
这个方程左边的表达式称为赔率。取等式的自然对数后,可以得出以下表达式。
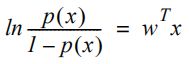
方程左侧的表达式变成了逻辑函数的对数,它线性地取决于x。
p(x)实际上是输入例子x属于1类的概率,所以1-p(x)等于相反情况的概率。使用条件概率表示法来写如下:
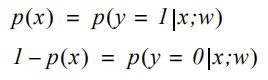
第一个方程的右侧可以解读为:给定了示例x和权重w,类别为1的概率。
可以通过最大化似然函数来确定逻辑回归中的权重参数的最优值。似然函数给出了“正确预测所有数据”的联合概率公式。并且希望这个概率值能尽可能的接近1。这得到以下等式:
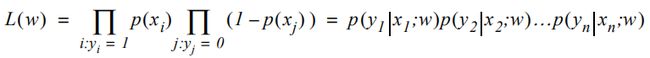
对表达式作自然对数可以得到对数似然函数,它经常被用作逻辑回归的cost function。
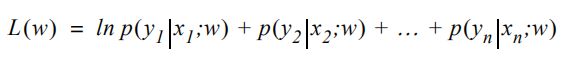
但依然可以进一步计算得到如下所示:
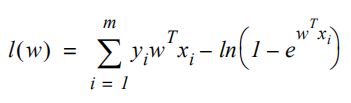
有了cost function后就可以使用gradient descent方法(这里可以翻译成梯度上升,原资料里翻译成了梯度下降)来找到这个cost function的最大值。还可以使用L1和L2正则化,或者是LBFGS优化等方法来应用到逻辑回归当中。
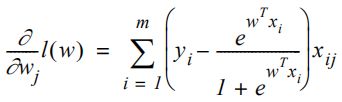
准备数据以使用Spark中的逻辑回归
用于逻辑回归的示例数据是从1994年美国人口普查数据中提取的成人数据集。它包含13个属性,性别、年龄、教育程度、婚姻状况、民族、原籍,以及Label是收入。
import spark.implicits._
val census_raw = sc.textFile("first-edition/ch08/adult.raw", 4).map(x => x.split(",").map(_.trim)).
map(row => row.map(x => try { x.toDouble } catch { case _ : Throwable => x }))
import org.apache.spark.sql.types.{StructType,StructField,StringType,DoubleType}
val adultschema = StructType(Array(
StructField("age",DoubleType,true),
StructField("workclass",StringType,true),
StructField("fnlwgt",DoubleType,true),
StructField("education",StringType,true),
StructField("marital_status",StringType,true),
StructField("occupation",StringType,true),
StructField("relationship",StringType,true),
StructField("race",StringType,true),
StructField("sex",StringType,true),
StructField("capital_gain",DoubleType,true),
StructField("capital_loss",DoubleType,true),
StructField("hours_per_week",DoubleType,true),
StructField("native_country",StringType,true),
StructField("income",StringType,true)
))
import org.apache.spark.sql.Row
val dfraw = spark.createDataFrame(census_raw.map(Row.fromSeq(_)), adultschema)
dfraw.show()
处理缺失值
dfraw.show列出了前20行的数据,这些数据具有缺失值(标记为?)。有几个处理缺失值的方法。
(1)如果列中缺少大量数据,则可以从数据集中删除整个列,因为该列可能会有不好的影响(如计算速度等等)。
(2)如果单个数据(行)中包含太多缺失值,则可以将其从数据集中删除。
(3)可以将缺失值设置为列中最常见的值。
(4)可以训练单独的分类或回归模型,并使用它来预测缺失值。
一般会选择第(3)条来处理缺失数据。
缺失值都出现在workclass、occupation和native_country。下面来研究workclass列中各个值的计数。
dfraw.groupBy(dfraw("workclass")).count().rdd.foreach(println)
[?,2799]
[Self-emp-not-inc,3862]
[Never-worked,10]
[Self-emp-inc,1695]
[Federal-gov,1432]
[State-gov,1981]
[Local-gov,3136]
[Private,33906]
[Without-pay,21]
可以看到,Private在workclass列是最多的。此外通过类似的代码可以发现,在occupation列,Prof-specialty值最常见。在native-country列最常用的值是United-States。现在可以使用DataFrame的na字段来估算缺失值。
//Missing data imputation
val dfrawrp = dfraw.na.replace(Array("workclass"), Map("?" -> "Private"))
val dfrawrpl = dfrawrp.na.replace(Array("occupation"), Map("?" -> "Prof-specialty"))
val dfrawnona = dfrawrpl.na.replace(Array("native_country"), Map("?" -> "United-States"))
处理类别值
dfrawnona中的大多数值都是字符串,分类算法并不能处理它们,需要将数据转换为数值。但是这个过程并不能单纯地使用0,1,2,3…来区别同个特征下的不同字符值。比如将marital_status字段的值(separated、divorced、never married、widowed、married)编码为0~4的整数值,这并不是一种具有现实意义的解释。因为这看上去never married会比separaed“大”,但其实不是,所以目前最常用的是一种称为“one hot encoding”的编码方式。如下图所示:
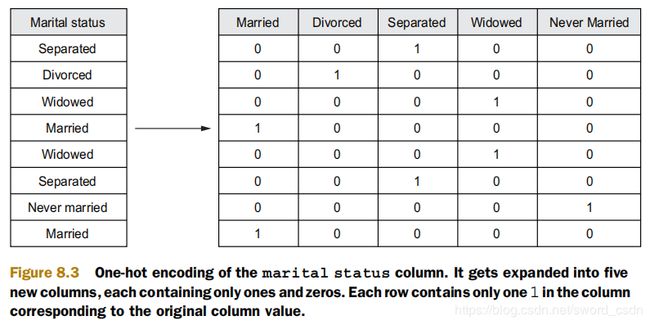
ML库中的3个类可以处理分类值,StringIndexer,OneHotEncoder,VectorAssembler。
使用StringIndexer
StringIndexer可以将String分类值转换为这些值的整数索引。
//converting strings to numeric values
import org.apache.spark.sql.DataFrame
def indexStringColumns(df:DataFrame, cols:Array[String]):DataFrame = {
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.feature.StringIndexerModel
//variable newdf will be updated several times
var newdf = df
for(c <- cols) {
//对cols中的每个列都fit一个StringIndexerModel,相当于生产了分类值。
val si = new StringIndexer().setInputCol(c).setOutputCol(c+"-num")
val sm:StringIndexerModel = si.fit(newdf)
//将转换的值放在带有扩展名“-num”的新列上,并删除旧列
newdf = sm.transform(newdf).drop(c)
//将新列重命名为旧名称
newdf = newdf.withColumnRenamed(c+"-num", c)
}
newdf
}
val dfnumeric = indexStringColumns(dfrawnona, Array("workclass", "education",
"marital_status", "occupation",
"relationship", "race", "sex", "native_country", "income"))
使用OneHotEncoder编码数据
OneHotEncode可以对列进行热编码,并将结果(一个稀疏向量)放入新列。
def oneHotEncodeColumns(df:DataFrame, cols:Array[String]):DataFrame = {
import org.apache.spark.ml.feature.OneHotEncoder
var newdf = df
for(c <- cols) {
//为每个列指定OneHotEncoder
val onehotenc = new OneHotEncoder().setInputCol(c)
onehotenc.setOutputCol(c+"-onehot").setDropLast(false)
//创建新列并删除旧列
newdf = onehotenc.transform(newdf).drop(c)
newdf = newdf.withColumnRenamed(c+"-onehot", c)
}
newdf
}
val dfhot = oneHotEncodeColumns(dfnumeric, Array("workclass", "education", "marital_status", "occupation", "relationship", "race", "native_country"))
使用VectorAssembler
处理好数据之后,最后一步是将所有这些新向量和原始列合并到包含所有特征的单个向量中,默认情况下,ML算法使用两列,features和label。MLlib算法使用的是包含LabeledPoint对象的RDD,如果将这种RDD转换成DataFrame的话,这个DataFrame就会包含features和label,所以DataFrame和LabeledPoint是等价的。
import org.apache.spark.ml.feature.VectorAssembler
val va = new VectorAssembler().setOutputCol("features")
va.setInputCols(dfhot.columns.diff(Array("income")))
val lpoints = va.transform(dfhot).select("features", "income").withColumnRenamed("income", "label")
训练模型
首先将数据集分为训练和验证集。
val splits = lpoints.randomSplit(Array(0.8, 0.2))
val adulttrain = splits(0).cache()
val adultvalid = splits(1).cache()
使用训练集拟合模型,然后使用验证集来测试模型的性能。
import org.apache.spark.ml.classification.LogisticRegression
val lr = new LogisticRegression
lr.setRegParam(0.01).setMaxIter(1000).setFitIntercept(true)
val lrmodel = lr.fit(adulttrain)
还可以使用fit方法设置参数。
import org.apache.spark.ml.param.ParamMap
val lrmodel = lr.fit(adulttrain, ParamMap(lr.regParam -> 0.01, lr.maxIter -> 500, lr.fitIntercept -> true))
ML中的逻辑回归使用LBFGS算法来最小化损失函数,因为它的速度更快。同时逻辑回归的实现会自动缩放这些特征。
评估分类模型
训练完的模型可以运用到数据上,观察其表现。
val validpredicts = lrmodel.transform(adultvalid)
validpredicts.show()
+--------------------+-----+-----------------+-----------------+----------+
| features|label| rawPrediction| probability|prediction|
+--------------------+-----+-----------------+-----------------+----------+
probablity列包含具有两个值的向量:样本不在prediction指定的类别的概率以及在该类别的概率,这两个值总是加起来为1。rawPrediction列也包含具有两个值的向量:样本不属于类别的对数几率和属于类别的对数几率。这两个值总是相反的数字(加起来为0)。prediction列包含1或0。
使用BinaryClassificationEvaluator
要评估模型的性能,可以使用BinaryClassificationEvaluator类及其evaluate方法:
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
val bceval = new BinaryClassificationEvaluator()
bceval.evaluate(validpredicts)
bceval.getMetricName
getMetricname方法可以返回BinaryClassificationEvaluator使用的度量标准,“areaUnderROC”。这个度量被称为“接收器工作特性曲线下的面积”。可以通过设置setMetricName(“areaunderpr”)来配置BinaryClassificationEvaluator以计算“精确率与召回率去线下的面积”。
精确率和召回率
前面使用过RMSE来评估线性回归的性能,但是这个方法不适用于评估分类结果。要评估模型的性能,可以计算真正(TP,True Positives),即正确分类为正的模型预测数,以及假正(FP,False Positives),即预测为正但实际为负的样本。类似地,也存在真负(TN)和假负(FN)。
从这4个数字来看,精确率(P)和召回率(R)度量的计算公式如下:
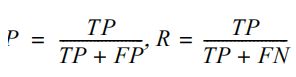
换句话说,精确率是经过模型预测的,所有标记为正的数据中,真的为正的数据的百分比。召回率是在所有真的为正的数据中,被模型标记为正的数据的百分比。
精确率-召回率曲线
当更改模型确定样本类型的概率阈值时,会获得精确率和召回率(也可以说成是:查全率,实际上这样更好理解)曲线,并且曲线上的每个点都可以确定一对精确率和召回率。
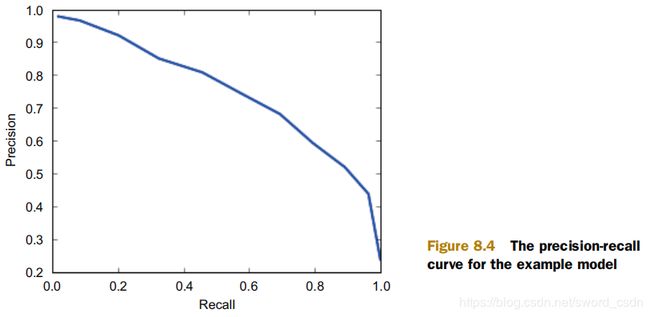
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,可以用不同的阀值,统计出一组不同阀值下的精确率和召回率。
精确率和召回率同时也互为条件。根据场景的不同,如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。在两者都要求高的情况下,可以用F-measure来衡量。F-measure的公式如下:
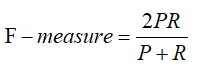
可以使用setThreshold方法更改模型的阈值。MLlib库的BinaryClassificationMetrics类可以计算包含predictions和labels的元组的RDD的精确率和召回率。
import org.apache.spark.ml.classification.LogisticRegressionModel
def computePRCurve(train:DataFrame, valid:DataFrame, lrmodel:LogisticRegressionModel) =
{
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
for(threshold <- 0 to 10)
{
var thr = threshold/10.0
if(threshold == 10)
thr -= 0.001
lrmodel.setThreshold(thr)
val validpredicts = lrmodel.transform(valid)
val validPredRdd = validpredicts.rdd.map(row => (row.getDouble(4), row.getDouble(1)))
val bcm = new BinaryClassificationMetrics(validPredRdd)
val pr = bcm.pr.collect()(1)
println("%.1f: R=%f, P=%f".format(thr, pr._1, pr._2))
}
}
computePRCurve(adulttrain, adultvalid, lrmodel)
// 0.0: R=1.000000, P=0.238081
// 0.1: R=0.963706, P=0.437827
// 0.2: R=0.891973, P=0.519135
// 0.3: R=0.794620, P=0.592486
// 0.4: R=0.694278, P=0.680905
// 0.5: R=0.578992, P=0.742200
// 0.6: R=0.457728, P=0.807837
// 0.7: R=0.324936, P=0.850279
// 0.8: R=0.202818, P=0.920543
// 0.9: R=0.084543, P=0.965854
// 1.0: R=0.019214, P=1.000000
这种情况下,PR曲线下面积是可用的两个度量之一。
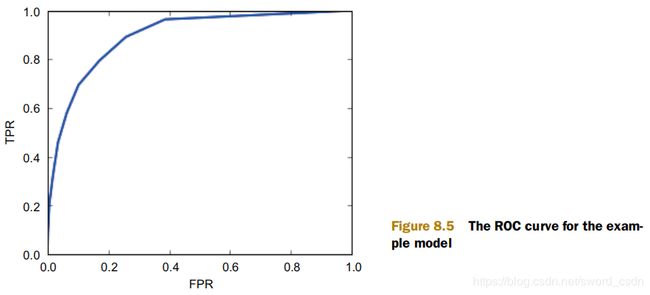
接受者操作特征曲线
当使用BinaryClassificationMetrics时,第二个可用度量(和默认度量)是接受者操作特征(ROC)曲线下的面积。ROC曲线与PR曲线相似,但在y轴绘制了召回率(TPR),在x轴绘制了假正率(FPR)。FPR计算为所有负样本假正的百分比:
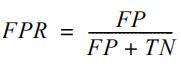
FPR指的是被模型错误归为正类的数据占所有负样本的百分比。ROC曲线如下图所示
生成上面曲线的代码如下:
def computeROCCurve(train:DataFrame, valid:DataFrame, lrmodel:LogisticRegressionModel) =
{
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
for(threshold <- 0 to 10)
{
var thr = threshold/10.0
if(threshold == 10)
thr -= 0.001
lrmodel.setThreshold(thr)
val validpredicts = lrmodel.transform(valid)
val validPredRdd = validpredicts.rdd.map(row => (row.getDouble(4), row.getDouble(1)))
val bcm = new BinaryClassificationMetrics(validPredRdd)
val pr = bcm.roc.collect()(1)
println("%.1f: FPR=%f, TPR=%f".format(thr, pr._1, pr._2))
}
}
computeROCCurve(adulttrain, adultvalid, lrmodel)
// 0,0: R=1,000000, P=0,237891
// 0,1: R=0,953708, P=0,430118
// 0,2: R=0,891556, P=0,515234
// 0,3: R=0,794256, P=0,586950
// 0,4: R=0,672525, P=0,668228
// 0,5: R=0,579511, P=0,735983
// 0,6: R=0,451350, P=0,783482
// 0,7: R=0,330047, P=0,861298
// 0,8: R=0,205315, P=0,926499
// 0,9: R=0,105444, P=0,972332
// 1,0: R=0,027004, P=1,000000
理想的模型将具有较低的FPR和较高的TPR,并且匹配的ROC曲线将会更靠近左上角。
执行k折交叉验证
使用交叉验证有助于验证模型的性能,因为它会多次验证模型并返回平均值作为最终结果。k折交叉验证将数据集划分为大小相等的k个子集,并需要训练k个模型,每次训练从分好的子集中里面,拿出一个作为测试集,其它k-1个作为训练集。
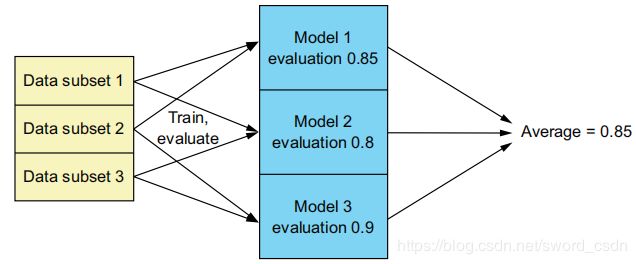
ML中的CrossValidator类可以自动执行此操作,给它一个estimator(如LogisticsRegression对象)和一个evaluator(BinaryClassificationEvaluation),然后设置他要使用的折数(默认为3):
import org.apache.spark.ml.tuning.CrossValidator
val cv = new CrossValidator().setEstimator(lr).setEvaluator(bceval).setNumFolds(5)
CrossValidator可以在setEstimatorParamMaps方法中使用几组参数,为每个ParamMap对象执行k折交叉验证。另一个类ParamGridBuilder将参数组生成为ParamMaps数组。可以添加带有单个参数值集的grids,然后构建完整的grid,如下所示:
import org.apache.spark.ml.tuning.ParamGridBuilder
val paramGrid = new ParamGridBuilder().addGrid(lr.maxIter, Array(1000)).
addGrid(lr.regParam, Array(0.0001, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5)).build()
将grid赋值给CrossValidator,接着进行训练,它会训练多个模型,并通过bestModel属性返回表现最好的一个。表现优劣由Evaluator bceval决定。
val cvmodel = cv.fit(adulttrain)
cvmodel.bestModel.asInstanceOf[LogisticRegressionModel].coefficients
//0.0001
cvmodel.bestModel.parent.asInstanceOf[LogisticRegression].getRegParam
又结果可知,表现最好的regParam是0.0001,现在可以在验证集上测试它的表现。
//0.9073005687252869
new BinaryClassificationEvaluator().evaluate(cvmodel.bestModel.transform(adultvalid))
综上所述,k折交叉验证虽然不能比较不同算法的表现,但是可以比较同一算法不同参数的表现。
多类别逻辑回归
ML暂时不支持多个类别的逻辑回归算法,但是MLlib的LogisticRegressionWithLBFGS可以,但是这里不打算对它做过多描述。除了MLlib可以使用one vs rest策略来解决多类别的逻辑回归问题。当使用这种方法是,每次训练一个模型,这个模型只负责一个分类,这个分类作为正类,而其他分类统合为负类。当结束训练并预测新的示例时,所有训练的模型都需要用来预测这个示例,最后选择概率最高的那个模型代表的分类。ML提供了OneVsRest类,它提供了一个OneVsRestModel用来实现数据集的转换。
首先准备数据:
import org.apache.spark.sql.types.{StructType,StructField,StringType,IntegerType}
val penschema = StructType(Array(
StructField("pix1",IntegerType,true),
StructField("pix2",IntegerType,true),
StructField("pix3",IntegerType,true),
StructField("pix4",IntegerType,true),
StructField("pix5",IntegerType,true),
StructField("pix6",IntegerType,true),
StructField("pix7",IntegerType,true),
StructField("pix8",IntegerType,true),
StructField("pix9",IntegerType,true),
StructField("pix10",IntegerType,true),
StructField("pix11",IntegerType,true),
StructField("pix12",IntegerType,true),
StructField("pix13",IntegerType,true),
StructField("pix14",IntegerType,true),
StructField("pix15",IntegerType,true),
StructField("pix16",IntegerType,true),
StructField("label",IntegerType,true)
))
val pen_raw = sc.textFile("first-edition/ch08/penbased.dat", 4).map(x => x.split(",")).
map(row => row.map(x => x.toDouble.toInt))
import org.apache.spark.sql.Row
val dfpen = spark.createDataFrame(pen_raw.map(Row.fromSeq(_)), penschema)
import org.apache.spark.ml.feature.VectorAssembler
val va = new VectorAssembler().setOutputCol("features")
va.setInputCols(dfpen.columns.diff(Array("label")))
val penlpoints = va.transform(dfpen).select("features", "label")
然后划分数据集和验证集
val pensets = penlpoints.randomSplit(Array(0.8, 0.2))
val pentrain = pensets(0).cache()
val penvalid = pensets(1).cache()
准备好数据之后就可以定义OneVsRest的分类器,这里是一个logistics regression 分类器
val penlr = new LogisticRegression().setRegParam(0.01)
import org.apache.spark.ml.classification.OneVsRest
val ovrest = new OneVsRest()
ovrest.setClassifier(penlr)
最后使用训练集对分类器进行训练,并得到模型。
val ovrestmodel = ovrest.fit(pentrain)
这个one vs rest 模型包含了10个logistics regression模型,现在可以使用它来预测验证集中的数据。
val penresult = ovrestmodel.transform(penvalid)
ML还没有用于多个类别的Evaluator,所以你可以使用MLlib的MulticlassMetrics。它需要包含predictions-labels元组的RDD,所以首先需要将DataFrame转换成RDD:
val penPreds = penresult.select("prediction", "label").rdd.map(row => (row.getDouble(0), row.getDouble(1)))
然后创建MulticlassMetrics对象
import org.apache.spark.mllib.evaluation.MulticlassMetrics
val penmm = new MulticlassMetrics(penPreds)
MulticlassMetrics可以返回精确率和召回率,并返回混淆矩阵,混淆矩阵展示了有多少原本在i类的数据被划分成了j类
penmm.precision
0.9018214127054642
penmm.recall(3)
0.9855072463768116
penmm.fMeasure(3)
0.9422632794457274
penmm.confusionMatrix
228.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 10.0 1.0
0.0 167.0 27.0 3.0 0.0 19.0 0.0 0.0 0.0 0.0
0.0 11.0 217.0 0.0 0.0 0.0 0.0 2.0 0.0 0.0
0.0 0.0 0.0 204.0 1.0 0.0 0.0 1.0 0.0 1.0
0.0 0.0 1.0 0.0 231.0 1.0 2.0 0.0 0.0 2.0
0.0 0.0 1.0 9.0 0.0 153.0 9.0 0.0 9.0 34.0
0.0 0.0 0.0 0.0 1.0 0.0 213.0 0.0 2.0 0.0
0.0 14.0 2.0 6.0 3.0 1.0 0.0 199.0 1.0 0.0
7.0 7.0 0.0 1.0 0.0 4.0 0.0 1.0 195.0 0.0
1.0 9.0 0.0 3.0 3.0 7.0 0.0 1.0 0.0 223.0
决策树和随机森林
决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
随机森林是以决策树为基础的一种更高级的算法。像决策树一样,随机森林即可以用于回归也可以用于分类。从名字中可以看出,随机森林是用随机的方式构建的一个森林,这由很多的相互不关联的决策树组成。
随机森林从本质上属于机器学习的一个很重要的分支叫做集成学习。集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
决策树
Spark只创建二值决策树。换言之,每个节点下只有两个分支。数据集根据分支来划分。如果分支仅包含单个类,或者说如果分支达到了某个树深度,则分支会变为叶节点。
一个例子
先创建一个数据集,采用了房屋数据集并对它进行了简化,仅选择age、education、sex、hours worked per week和目标变量income等特征,并将income转换为分类标签(如果一个人的年薪超过5万则为1,否则为0),然后对数据进行采样。
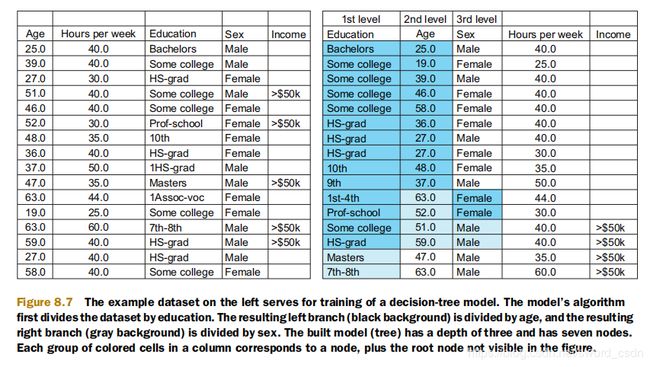
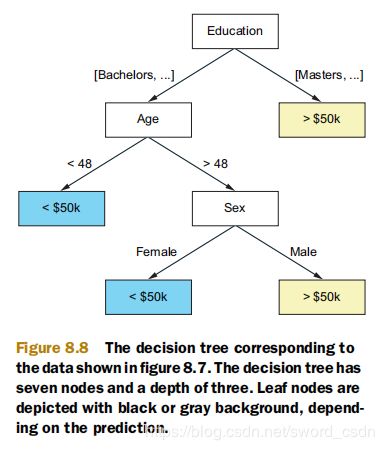
接下来使用数据集来训练决策树模型。算法使用原始数据集的方式,首先算法确定应该首先选择education特征。它根据目标类别值(imcome)的education特征的可能类别划分为左侧类别,对应下图中的左侧分支,并在上图用深蓝色背景标绘。得到的右侧分支仅包含正示例(年薪大于50000美元),因此它被声明为叶节点。
接着,算法使用age特征。它重复了相同的过程,只将左边education分支中的列值分成两组,因为age是连续的,它使用阈值而不是一组类别来划分值。这时左分支成为了叶节点。右分支,选择了sex特征,并且产生了最后两个叶子节点。
理解不纯度与信息增益
决策树算法使用不纯度和信息增益来确定要分割的特征。不纯度有两种:熵和基尼不纯度。熵(香农熵)来自信息论,是衡量消息包含的信息量的指标。数据集D的熵可用以下公式来计算:
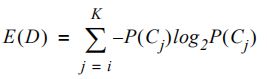
其中K是目标类的数量,p(Cj)是第j类Cj的比例。对于示例数据集,熵等于:
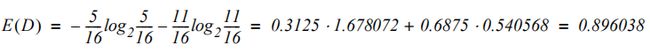
如果数据集中只有一个类,则熵为0。如果所有类在数据集中均匀存在,则熵达到最大值。对于二值分类问题,此最大值为1。
基尼不纯度衡量在一个数据集中,一个随机选择的元素会被错误标记的程度,并且这个数据集中的数据是根据标记的分布随机标记的。它是这样计算的:
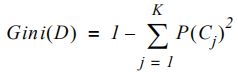
如果所有类在数据集中平均存在(在两个类的情况下等于0.5),则它也达到最大值,如果数据集只包含一个类,则等于0。例如上面使用到的数据集等于0.4296875。
训练决策树模型
在使用数据集之前,需要一个额外的数据准备步骤。需要添加列元数据,决策树算法需要确定可能类的数量。可以使用StringIndexer类,将类别字符串值转换为整数。
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.feature.StringIndexerModel
val dtsi = new StringIndexer().setInputCol("label").setOutputCol("label-ind")
val dtsm:StringIndexerModel = dtsi.fit(penlpoints)
val pendtlpoints = dtsm.transform(penlpoints).drop("label").withColumnRenamed("label-ind", "label")
划分训练集和验证集
val pendtsets = pendtlpoints.randomSplit(Array(0.8, 0.2))
val pendttrain = pendtsets(0).cache()
val pendtvalid = pendtsets(1).cache()
ML中的决策树算法由DecisionTreeClassifier类实现。用于回归的决策树由DecisionTreeRegressor类实现,它可配置多个参数:
maxDepth:确定树深度。默认5
maxBins:连续特征划分时创建的最大箱子树。默认32
minInstancesPerNode:设置每个分支在分割后需要具有的最小数据集样本。默认1
minInfoGain:将分割的最小信息增益设置为有效。默认0
通过调用训练集上的fit训练模型:
import org.apache.spark.ml.classification.DecisionTreeClassifier
val dt = new DecisionTreeClassifier()
dt.setMaxDepth(20)
val dtmodel = dt.fit(pendttrain)
检查决策树
决策树的优点之一是学习的决策规则是可以被可视化的,并且可以提供算法的内部工作原理的直观解释。检查根节点
dtmodel.rootNode
res0: org.apache.spark.ml.tree.Node = InternalNode(prediction = 0.0,
impurity = 0.4296875, split = org.apache.spark.ml.tree.
CategoricalSplit@557cc88b)
可以看到根节点的计算不纯度(0.4296875)。可以检查featureIndex字段来查看第一个节点上的分割使用了哪个特征。
import org.apache.spark.ml.tree.InternalNode
//15
dtmodel.rootNode.asInstanceOf[InternalNode].split.featureIndex
索引15对应数据集中的pix15。split字段还可以看到使用哪个阈值来分割特征15的值:
import org.apache.spark.ml.tree.ContinuousSplit
dtmodel.rootNode.asInstanceOf[InternalNode].split.asInstanceOf[ContinuousSplit].threshold
//51
拆分是CategoricalSplit类的实例,可以访问其leftCategories和rightCategories字段来检查每个分支使用了哪些类别。此外,可以访问左右节点:
dtmodel.rootNode.asInstanceOf[InternalNode].leftChild
dtmodel.rootNode.asInstanceOf[InternalNode].rightChild
评估模型
可以MulticlassMetrics转换验证集并评估模型。
val dtpredicts = dtmodel.transform(pendtvalid)
val dtresrdd = dtpredicts.select("prediction", "label").rdd.map(row => (row.getDouble(0), row.getDouble(1)))
val dtmm = new MulticlassMetrics(dtresrdd)
dtmm.precision
//0.951442968392121
dtmm.confusionMatrix
// 192.0 0.0 0.0 9.0 2.0 0.0 2.0 0.0 0.0 0.0
// 0.0 225.0 0.0 1.0 0.0 1.0 0.0 0.0 3.0 2.0
// 0.0 1.0 217.0 1.0 0.0 1.0 0.0 1.0 1.0 0.0
// 9.0 1.0 0.0 205.0 5.0 1.0 3.0 1.0 1.0 0.0
// 2.0 0.0 1.0 1.0 221.0 0.0 2.0 3.0 0.0 0.0
// 0.0 1.0 0.0 1.0 0.0 201.0 0.0 0.0 0.0 1.0
// 2.0 1.0 0.0 2.0 1.0 0.0 207.0 0.0 2.0 3.0
// 0.0 0.0 3.0 1.0 1.0 0.0 1.0 213.0 1.0 2.0
// 0.0 0.0 0.0 2.0 0.0 2.0 2.0 4.0 198.0 6.0
// 0.0 1.0 0.0 0.0 1.0 0.0 3.0 3.0 4.0 198.0
随机森林
Spark中的随机森林由RandomForestClassifier和RandomForestRegressor类实现。比如RandomForestClassifier,可以使用两个附加参数进行配置。
numTrees:是要训练的树的数量。默认20。
featureSubsetStrategy:确定特征装袋的策略。all(所有特征),onethird(随机选择1/3),sqrt(随机选择sqrt(特征数)),log2(随机选择log2(特征数)),auto(默认值)。
大多数情况下,默认值都可以正常工作。如果想训练大量的树,则需要确保给驱动器提供足够的内存,因为经过训练的决策树会被保存在内存中。
import org.apache.spark.ml.classification.RandomForestClassifier
val rf = new RandomForestClassifier()
rf.setMaxDepth(20)
val rfmodel = rf.fit(pendttrain)
通过访问trees字段检查它所训练的树
rfmodel.trees
转换验证集后,可以使用MulticlassMetrics类似常规的方式评估模型的性能:
val rfpredicts = rfmodel.transform(pendtvalid)
val rfresrdd = rfpredicts.select("prediction", "label").rdd.map(row => (row.getDouble(0), row.getDouble(1)))
val rfmm = new MulticlassMetrics(rfresrdd)
rfmm.precision
//0.9894640403114979
rfmm.confusionMatrix
// 205.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
// 0.0 231.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0
// 0.0 0.0 221.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0
// 5.0 0.0 0.0 219.0 0.0 0.0 2.0 0.0 0.0 0.0
// 0.0 0.0 0.0 0.0 230.0 0.0 0.0 0.0 0.0 0.0
// 0.0 1.0 0.0 0.0 0.0 203.0 0.0 0.0 0.0 0.0
// 1.0 0.0 0.0 1.0 0.0 0.0 216.0 0.0 0.0 0.0
// 0.0 0.0 1.0 0.0 2.0 0.0 0.0 219.0 0.0 0.0
// 0.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 212.0 0.0
// 0.0 0.0 0.0 0.0 0.0 0.0 2.0 2.0 2.0 204.0
使用k-均值聚类
聚类的任务是基于某种相似性度量将一组示例分组成几个组,是一种无监督学习方法。聚类可以用于许多目的,如下所述。
(1)将数据分组(客户细分或通过相似习惯对客户进行分组)。
(2)图像分割(识别图像中的不同区域)。
(3)检测异常。
(4)文本分类或识别一组文章中的主题。
(5)分组搜索结果。
Spark提供了以下聚类算法的实现,k-均值聚类、高斯混合模型、幂迭代聚类。
k-均值聚类是最简单的,但是它具有一下缺点:处理非球形族和不均匀大小的簇(密度不均匀或半径不均匀)是有困难的。无法有效利用独热编码功能。它通常用于分类文本文档,词频-逆文档频率(TF-IDF)特征向量方法。
高斯混合模型是一种基于模型的聚类技术,这意味着每个簇都由高斯分布表示,模型是这些分布的混合。高斯混合模型不能很好地扩展到具有多个维度的数据集。
幂迭代聚类一种谱聚类的形式。
k-均值聚类
假设在二维数据集中有一组示例,希望将它们分组到两个簇。
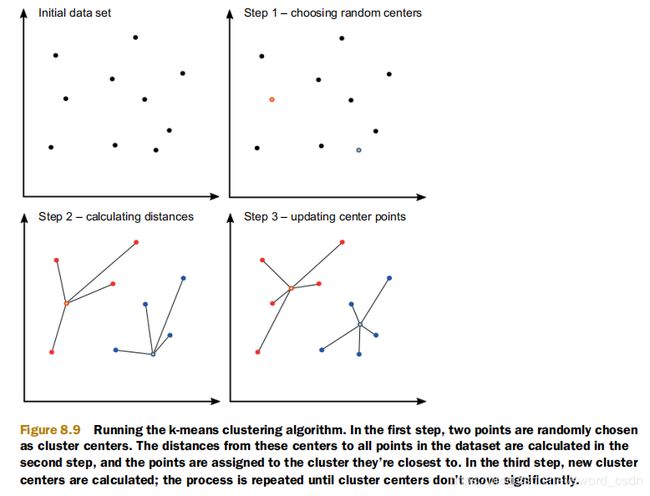
第一步,k-均值聚类算法随机选择两点作为簇中心。第二步,计算数据集中每个中心到所有点的距离,然后将点分配给它们最接近的簇。第三步,计算每个簇的均值点,这些点成为新的簇中心,再次计算到所有点的距离,将点相应地分配给簇,并再次计算新的聚类中心。如果新的簇中心没有明显移动,则这个过程就会停止。
在Spark中使用k-均值聚类
使用聚类算法,没有必要进行验证和训练数据集。
k——要查找的簇数(默认为2)
maxIter——要执行的最大迭代次数(必需)
predictionCol——预测列名称(默认为“prediction”)
featuresCol——特征列名称(默认为“features”)
tol——收敛容差
seed——簇初始化的随机种子值
最大迭代次数k可以设置为几百个。
import org.apache.spark.ml.clustering.KMeans
val kmeans = new KMeans()
kmeans.setK(10)
kmeans.setMaxIter(500)
val kmmodel = kmeans.fit(penlpoints)
评估模型
有以下几种方法可以帮助:成本值、与中心的平均距离和列联表。
成本值(也称为失真),是指从所有点到匹配簇中心的二次方距离的综合,是评估k-均值模型的主要指标。
确定簇数
实际操作中会有一个问题,就是应该使用多少个簇,在这种情况下,可以使用“肘部法则”。
逐渐增加簇数量,为每个数字训练一个模型,并查看每个模型的成本。