NIO
Java NIO 虽然提供了非阻塞的网络通信编程框架,但它的设计带来了很多编程难题。
1 难懂的 ByteBuffer
Java NIO 抛弃了我们所熟悉的 Stream、byte[]等数据结构,设计了一个全新的数据结构—— ByteBuffer,ByteBuffer 的主要使用场景是保存从 Socket 中读取的输入字节流,并循环利用,以降低 GC 的压力。第一眼看到它的广告介绍后,你会感觉它功能强大,美不胜收,作为一个单纯的程序员,你可能会瞬间爱上它,但当你认真地去学习它的 API 时,你可能就把自己搞晕了。以经典的 Echo 服务器为例,其核心是读入客户端发来的数据,并且回写给客户端,这段代码用 ByteBuffer 来实现,大致就是下面的逻辑:
1 byteBuffer = ByteBuffer.allocate(N);
2 //读取数据,写入 byteBuffer
3 readableByteChannel.read(byteBuffer);
6 //读取 byteBuffer,写入 Channel
7 writableByteChannel.write(byteBuffer);
如果你一眼就发现了上述代码中存在一个严重缺陷且无法正常工作,那么说明你可能的确精通了 ByteBuffer 的用法。这段代码的缺陷是在第 6 行之前少了一个 byteBuffer.flip()调用。之所以 ByteBuffer 会设计一个这样奇怪名字的 Method,是因为它与我们所熟悉的 InputStream & OutStream 分别操作输入输出流的传统 I/O 设计方式不同,它是“二合一”的设计方式。我们可以把 ByteBuffer 设想成内部拥有一个固定长度 byte 数组的对象,属性 capacity 为数组的长度(不可变),position 变量保存当前读(或写)的位置,limit 变量为当前可读或可写的位置上限。当byte 被写入到 ByteBuffer 中的时候,position++,而 0 到 position 之间的字符就是已经写入的字符。如果后面要读取之前写入的这些字符,则需要将 position 重置为 0,而 limit 则被设置为之前 position 的值,这个操作恰好就是 flip 要做的事情,这样一来,从 postion 到 limit 之间的字符刚好是要读的全部数据。
ByteBuffer 有三种实现方式:第一种是堆内存储数据的 HeapByteBuffer;第二种是堆外存储数据的 DirectByteBuffer;最后一种是文件映射(数据存储到文件中)的 MappedByteBuffer。 HeapByteBuffer 是将数据保存在 JVM 堆内存中,我们知道 64 位 JVM 的堆内存最大为 32GB 时候的内存利用率最高,一旦堆超过了 32GB,你就进入到 64 位的世界里了,应用程序的可用堆的空间就会减小。另外,过大的 JVM 堆内存也容易导致复杂的 GC 问题,因此最好的办法是采用堆外内存,堆外内存的管理由程序员自己控制,类似 C 语言的直接内存管理,而DirectByteBuffer 就是采用堆外内存来存放数据的,因此在访问性能提升的同时带来了复杂的动态内存管理问题。而动态内存管理是一项高端编程技术,涵盖了内存分配性能、内存回收、内存碎片化、内存利用率等一系列复杂问题。
面对内存分配性能这个问题,我们通常会在 Java 里采用 ThreadLocal 对象来实现多线程本地化分配的思路,即每个线程拥有一个 ThreadLocal 类型的 ByteBufferPool,然后每个线程管理各自的内存分配和回收问题,避免共享资源导致的竞争问题。下面这段来自大名鼎鼎的 GrizzyNIO 框架中的 ByteBufferThreadLocalPool,就采用了 ThreadLocal 结合 ByteBuffer 视图的动态内存管理技术。

上面的代码很简单也很经典,可以分配任意大小的内存块,但存在一个问题,即它只能从 pool 的当前位置持续往下分配空间,而中间被回收的内存块是无法立即被分配的,因此内存利用率不高。另外,当后面分配的内存没有被及时释放的时候,会发生内存溢出,即使前面分配的内存早已释放大半。其实上述问题可以通过一个环状的结构(Ring)来解决,即分配到头以后,回头重新继续分配,但代码会稍微复杂点。
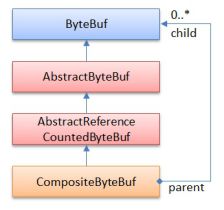
Netty 则采用了另外一种思路。首先,Netty 的作者认为 JDK 的 ByteBuffer 设计得并不好,其中 ByteBuffer 不能继承,以及 API 难用、容易出错是最大的两个问题,于是他重新设计了一个接口 ByteBuf 来替代官方的 ByteBuffer。如下所示是 ByteBuffer 的设计示意图,它通过分离读写的位置变量(reader index 及 writer index)简单、有效地解决了 ByteBuffer 难懂的 flip 操作问题,这样一来 ByteBuf 也可以实现同时读与写的功能了。

由于 ByteBuf 是一个接口,所以可以继承与扩展,为了实现分配任意长度的 Buffer,Netty设计了一个 CompositeByteBuf 实现类,它通过组合多个 ByteBuf 实例的方式巧妙实现了动态扩容能力,这种组合扩容的方式存在一个读写效率问题,即要判断当前的读写位置是否要移到下一个 ByteBuf 实例上。
Netty 的 ByteBuf 实例还有一个很重要的特征,即记录了被引用的次数,所有实例都继承自AbstractReferenceCountedByteBuf。这点非常重要,因为我们在实现 ByteBuf Pool 时,需要确保ByteBuf 被正确地释放和回收,由于官方的 ByteBuffer 缺乏这一特征,因此很容易因为使用不当导致内存泄露或者内存访问错误的严重 Bug。
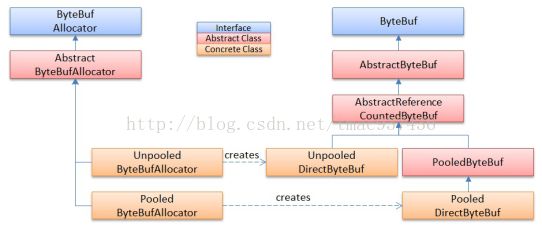
由于使用 ByteBuffer 时用得最多的是堆外 DirectByteBuffer,因此一个功能齐全、高效的Buffer Pool 对于 NIO 来说相当重要,官方 JDK 并没有提供这样的工具包,于是 Netty 的作者顺便也把这部分功能实现了,基于 ByteBuf 实现了一套可以在 Netty 之外单独使用的 Buffer Pool框架,如下图所示。
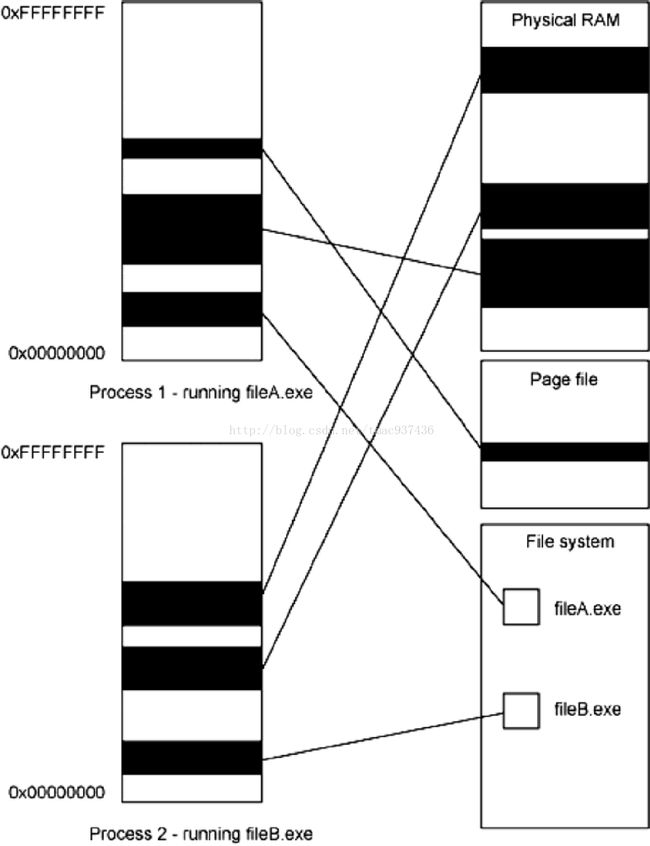
我们再来说说 MappedByteBuffer,说得通俗一点就是 Map 把一个磁盘文件(整体或部分内容)映射到计算机虚拟内存的一块区域,这样就可以直接操作内存当中的数据,而无须每次都通过 I/O 从物理硬盘上读取文件,所以在效率上有很大提升。想要真正理解 MappedByteBuffer的原理和价值,需要掌握一点操作系统内存、文件系统、内存页与内存交换的基本知识。如下图所示,每个进程有一个虚拟地址空间,也被称为逻辑内存地址,其大小由该系统上的地址大小规定,比如 32 位 Windows 的单进程可寻址空间是 4GB,虚拟地址空间也使用分页机制,即我们所说的内存页面。当一个程序尝试使用虚拟地址访问内存时,操作系统连同硬件会将该分页的虚拟地址映射到某个具体的物理位置,这个位置可以是物理 RAM、页面文件(Page file 是Windows 的说法,对应 Linux 下的 swap)或文件系统中的一个普通文件。尽管每个进程都有其自己的地址空间,但程序通常无法使用所有这些空间,因为地址空间被划分为内核空间和用户空间。大部分操作系统将每个进程地址空间的一部分映射到一个通用的内核内存区域。被映射来供内核使用的地址空间部分被称为内核空间,其余部分被称为用户空间,可供用户应用程序使用。
MappedByteBuffer 使用 mmap 系统调用来实现文件内存映射过程,如下图中的过程 1 所示。此外,在内存映射的过程中,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space),并没有实际的数据复制,文件没有被载入内存,所以建立内存映射的效率很高。仅仅当此文件的内容要被访问的时候,才会触发操作系统加载内存页,这个过程中可能涉及当物理内存不足时内存交换的问题,即过程 4。

通过上面的原理分析,我们就不难理解 JDK 中关于 MappedByteBuffer 的一些方法的作用了。
- fore():当缓冲区是 READ_WRITE 模式时,此方法对缓冲区内容的修改强行写入文件。
- load():将缓冲区的内容载入内存,并返回该缓冲区的引用。
-
isLoaded():如果缓冲区的内容在物理内存中,则返回真,否则返回假。
MappedByteBuffer 的主要使用场景有如下两个。 -
基于文件共享的高性能进程间通信(IPC)。
-
大文件高性能读写访问。
正因为上述两个独特的使用场景,MappedByteBuffer 有很多高端应用,比如 Kafka 采用MappedByteBuffer 来处理消息日志文件,而来自伯克利分校的 AMPLab 开发的分布式文件系统 Tachyon 也采用了 MappedByteBuffer 加速文件读写。高性能 IPC 通信技术在当前大数据和实时计算方面越来越重要,原因很简单,当前服务器的核心数越来越多,而且都支持 NUMA 技术,在这种情况下,单机上的多进程架构能最大地提升系统的整体吞吐量。于是,国外有人基于MappedByteBuffer 实现了一个 DEMO 性质的高性能 IPC 通信例子,项目地址为 https://github. com/caplogic/Mappedbus,其作者受到了 Java 高性能编程领域的大神 peter-lawrey 的著名项目Java Chronicle 的启发,也采用了内存映射文件来实现 Java 多进程间的数据通信,其原理图如下所示。

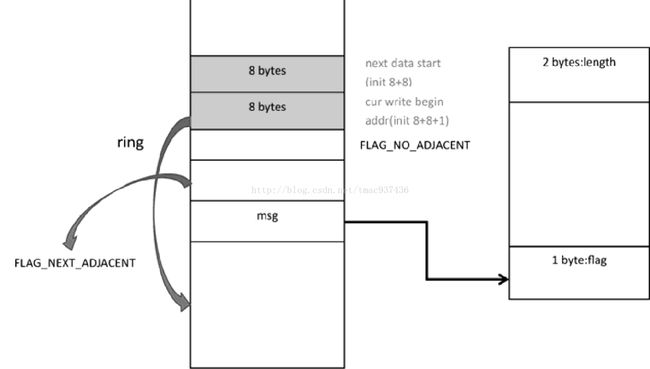
一个进程负责写入数据到内存映射文件中,其他进程(不限于 Java)则从此映射文件中读取数据,经笔者测试,采用这种方式的性能极高,在笔者的笔记本计算机上可以达到每秒 4000万的传输速度,消息延迟仅仅只有 25ns。受此项目的启发,笔者也发起了一个更为完善的 IPC开源框架,项目地址为 https://github.com/MyCATApache/Mycat-IPC,此项目的关键点在于用一个 MappedByteBuffer 模拟了 N 组环形队列的数据结构,用来表示一个进程发送或者读取的消息队列。如下所示是 MappedByteBuffer 内存结构图,内存起始位置记录了当前定义的几个RingQueue,随后记录每个 RingQueue 的长度以确定其开始内存地址与结束内存地址, RingQueue 类似 ByteBuffer 的设计,有记录读写内存位置的变量,而放入队列的每个“消息”都有两个字节的长度、消息体本身,以及下个消息的开始位置 Flag(继续当前位置还是已经掉头、从头开始)。笔者计划未来将 Mycat 拆成多进程的架构,一个进程负责接收客户端的Socket 请求,然后把数据通过 IPC 框架分发给后面几个独立的进程去处理,处理完的响应再通过 IPC 传回给 Socket 监听进程,最终写入客户端。
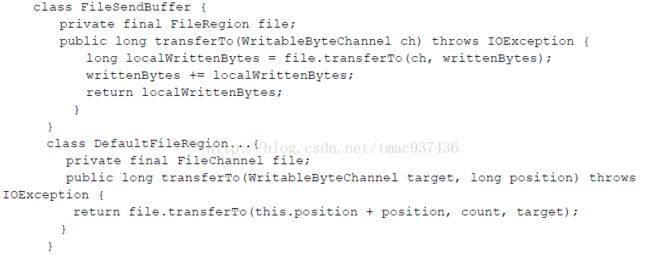
MappedByteBuffer 还有另外一个奇妙的特性,“零复制”传输数据,它的 transferTo 方法能节省一次缓冲区的复制过程,直接写入另外一个 Channel 通道上,如下图所示。
Netty 传输文件的逻辑就用到了 transferTo 这一特性,下面的代码片段给出了真相:
2 晦涩的“非阻塞”
NIO 里“非阻塞”(None Blocking)这个否定式的新名称对于大多数程序员来说的确很难理解,就好像他们很难理解妹子们多变的心情一样。即便如此,我们还是要硬着头皮去弄懂它,否则,高薪是很难有的,而没有高薪,再容易理解的妹子也会离开。不去想诗与远方了,在笔者解释“非阻塞”这个概念之前,让我们先来恶补一下 TCP/IP 通信的基础知识。
首先,对于 TCP 通信来说,每个 TCP Socket 在内核中都有一个发送缓冲区和一个接收缓冲区,TCP 的全双工的工作模式及 TCP 的滑动窗口便依赖于这两个独立的 Buffer 及此 Buffer 的填充状态。接收缓冲区把数据缓存入内核,若应用进程一直没有调用 Socket 的 read 方法进行读取的话,则此数据会一直被缓存在接收缓冲区内。不管进程是否读取 Socket,对端发来的数据都会经由内核接收并且缓存到 Socket 的内核接收缓冲区中。read 所做的工作,就是把内核接收缓冲区中的数据复制到应用层用户的 Buffer 里面,仅此而已。进程调用 Socket 的 send 发送数据的时候,最简单的情况(也是一般情况)是将数据从应用层用户的 Buffer 里复制到 Socket 的内核发送缓冲区中,然后 send 便会在上层返回。换句话说,send 返回时,数据不一定会被发送到对端(和 write写文件有点类似),send 仅仅是把应用层 Buffer 的数据复制到 Socket 的内核发送 Buffer 中。而对于 UDP 通信来说,每个 UDP Socket 都有一个接收缓冲区,而没有发送缓冲区,从概念上来说就是只要有数据就发,不管对方是否可以正确接收,所以不缓冲,不需要发送缓冲区。
其次,我们来说说 TCP/IP 的滑动窗口和流量控制机制,前面我们提到,Socket 的接收缓冲区被 TCP 和 UDP 用来缓存网络上收到的数据,一直保存到应用进程读走为止。对于 TCP 来说,如果应用进程一直没有读取,则 Buffer 满了之后,发生的动作是:通知对端 TCP 协议中的窗口关闭,保证 TCP 套接口接收缓冲区不会溢出,保证了 TCP 是可靠传输的,这个便是滑动窗口的实现。因为对方不允许发出超过通告窗口大小的数据,所以如果对方无视窗口大小而发出了超过窗口大小的数据,则接收方 TCP 将丢弃它,这就是 TCP 的流量控制原理。而对于 UDP 来说,当接收方的 Socket 接收缓冲区满时,新来的数据报无法进入接收缓冲区,此数据报就会被丢弃,UDP 是没有流量控制的,快的发送者可以很容易地淹没慢的接收者,导致接收方的 UDP丢弃数据报。
明白了 Socket 读写数据的底层原理,我们就容易理解传统的“阻塞模式”了:对于读取 Socket数据的过程而言,如果接收缓冲区为空,则调用 Socket 的 read 方法的线程会阻塞,直到有数据进入接收缓冲区中;而对于写数据到 Socket 中的线程而言,如果待发送的数据长度大于发送缓冲区的空余长度,则会阻塞在 write 方法上,等待发送缓冲区的报文被发送到网络上,然后继续发送下一段数据,循环上述过程直到数据都被写入到发送缓冲区为止。
从上述的程来看,传统的 Socket 阻塞模式直接导致每个 Socket 都必须绑定一个线程来操作数据,参与通信的任意一方如果处理数据的速度较慢,则都会直接拖累另一方,导致另一方的线程不得不浪费大量的时间在 I/O 等待上,所以,每个 Socket 要绑定一个单独的线程正是传统Socket 阻塞模式的根本“缺陷”。之所以这里加了“缺陷”两个字,是因为这种模式在一些特定场合下效果是最好的,比如只有少量的 TCP 连接通信,双方都非常快速地传输数据,此时这种模式的性能最高。
现在我们可以开始分析“非阻塞”模式了,它就是要解决 I/O 线程与 Socket 解耦的问题,因此,它引入了事件机制来达到解耦的目的。我们可以认为 NIO 底层中存在一个 I/O 调度线程,它不断扫描每个 Socket 的缓冲区,当发现写入缓冲区为空(或者不满)的时候,它会产生一个Socket 可写事件,此时程序就可以把数据写入 Socket 里,如果一次写不完,则等待下次可写事件的通知;而当发现读取缓冲区里有数据的时候,它会产生一个 Socket 可读事件,程序收到这个通知事件时,就可以从 Socket 读取数据了。
上述原理听起来很简单,但实际上有很多容易陷入的“坑”,如下所述。
收到可写事件时,想要一次性地写入全部数据,而不是将剩余数据放入 Session 中,等待下次可写事件的到来。
写完数据并且没有可写数据的时候,在应答数据报文已经全部发送给客户端的情况下,需要取消对可写事件的“订阅”,否则 NIO 调度线程总是报告 Socket 可写事件,导致 CPU 使用率狂飙。因此,如果没有数据可写,就不要订阅可写事件。
如果来不及处理发送的数据,就需要暂时“取消订阅”可读事件,否则数据从 Socket 里读取以后,下次还会很快发送过来,而来不及处理的数据积压到内存队列中,最终会导致内存溢出。
此外,NIO 里还有一个容易被忽略的高级问题,即业务数据处理逻辑是使用 NIO 调度线程来执行还是用另外线程池里的线程来执行?关于这个问题,没有绝对的答案,在 Mycat 的研发过程中,我们经过大量测试和研究得出以下结论:
如果数据报文的处理逻辑比较简单,不存在耗时和阻塞的情况,则可以直接用 NIO 调度线程来执行这段逻辑,避免线程上下文切换带来的损耗;如果数据报文的处理逻辑比较复杂,耗时比较多,而且可能存在阻塞和执行时间不确定的情况,则建议放入线程池里去异步执行,防止 I/O 调度线程被阻塞。
如下所示是 Mycat 里相关设计的示意图。
3 复杂的 Reactor 模型
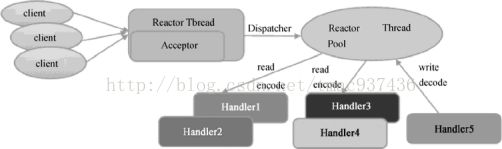
Java NIO 框架比较原始,目前主流的 Java 网络程序都在其上设计实现了 Reactor 模型,隐藏了 NIO 底层的复杂细节,大大简化了 NIO 编程,其原理和架构如下图所示,Acceptor 负责接收客户端 Socket 发起的新建连接请求,并把该 Socket 绑定到一个 Reactor 线程上,于是这个Socket 随后的读写事件都交给此 Reactor 线程来处理。Reactor 线程读取数据后,交给用户程序中的具体 Handler 实现类来完成特定的业务逻辑处理。为了不影响 Reactor 线程,我们通常使用一个单独的线程池来异步执行 Handler 的接口方法。
如果仅仅到此为止,则 NIO 里的 Reactor 模型还不算是很复杂,但实际上,我们的服务器是多核心的,而且需要高速并发处理大量的客户端连接,单线程的 Reactor 模型就满足不了需求了,因此我们需要多线程的 Reactor。一般原则是 Reactor(线程)的数量与 CPU 核心数(逻辑CPU)保持一致,即每个 CPU 执行一个 Reactor 线程,而客户端的 Socket 连接则随机均分到这些 Reactor 线程上去处理,如果有 8000 个连接,而 CPU 核心数为 8,则平均每个 CPU 核心承担 1000 个连接。
多线程 Reactor 模型下可能带来另外一个问题,即负载不均衡的问题,虽然每个 Reactor 线程服务的 Socket 数量是均衡的,但每个 Socket 的 I/O 事件可能是不均衡的,某些 Socket 的 I/O事件可能大大多于其他 Socket,从而导致某些 Reactor 线程负载更高,此时是否需要重新分配Socket 到不同的 Reactor 线程呢?这的确是一个问题,因为如果要切换 Socket 到另外的 Reactor 线程,则意味着 Socket 相关的 Connection 对象、Session 对象等必须是线程安全的,这本身就带来一定的性能损耗,另外需要对 I/O 事件做统计分析,启动额外的定时线程在合适的时机完成 Socket 重分配,这本身就是很复杂的事情。
由于 Netty 的代码过于复杂,我们下面以 Mycat NIO Framework 为例,来说说应该怎样设计一个基于多线程 Reactor 模式的高性能 NIO 框架。
如下图所示,我们先要有一个基础类 NetSystem,它负责 NIO 框架中基础参数与基础组件的创建,其中常用的基础参数如下。
- Socket 缓存区的大小
- TCP_NODELAY 标记
- Reactor 个数
- ByteBuffer Pool 的参数
- 业务线程池大小。基础组件如下
- NameableExecutor:业务线程池
- NIOAcceptor:负责接收客户端的新建连接请求
- NIOConnector:负责发起客户端连接(NIO 模式)
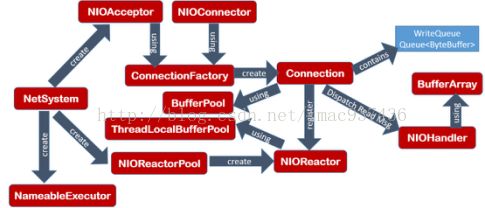
考虑到不同的应用需要创建自己的 Connection 实例来实现应用特定的网络协议,而且一个程序里可能会有几种网络协议,因此框架里设计了 Connection 抽象类,采用的是工厂模式,即由不同的 ConnectionFactory 来创建不同的 Connection 实现类。不管是作为 NIO Server 还是作为NIO Client,应用程序都可以采用这套机制来实现自己的 Connection。当收到 Socket 报文(及相关事件)时,框架会调用绑定在此 Connection 上的 NIO Handler 来处理报文,而 Connection 要发送的数据被放入一个 WriteQueue 队列里,框架实现具体的无阻塞发送逻辑。
为了更好地使用有限的内存,Mycat NIO 设计了一个“双层”的 ByteBuffer Pool 模型,全局的 ByteBufferPool 被所有 Connection 共享,而每个 Reactor 线程则在本地保留了一份局部占用ByteBuffer Pool——ThreadLocalBufferPool,我们可以设定 80%的 ByteBuffer 被 N 个 Reactor线程从全局 Pool 里取出并放到本地的 ThreadLocalBufferPool 里,这样一来,可以避免过多的全局 Pool 的锁抢占操作,提升 NIO 性能。
NIOAcceptor 收到客户端发起的新连接事件后,会新建一个 Connection 对象,然后随机找到一个 NIOReactor,并把此 Connection 对象放入该 NIOReactor 的 Register 队列中等待处理,NIOReactor 会在下一次的 Selector 循环事件处理之前,先处理所有新的连接请求。下面两段来自 NIOReactor 中的代码表明了这一逻辑过程:

NIOConnector 属于 NIO 客户端框架的一部分,与 NIOAcceptor 类似,当需要发起一个 NIO连接的时候,程序调用下面的方法将连接放入“待连接队列”中并唤醒 Selector:

随后,NIOConnector 的线程会先处理“待连接队列”,发起真正的 NIO 连接并异步等待响应:

最后,在 NIOConnector 的线程 Run 方法里,对收到连接完成事件的 Connection,回调应用的通知接口,应用得知连接已经建立时,可以在接口里主动发数据或者请求读数据: