鸢尾花决策树/随机森林实例——sklearn
本次实践主要通过 DecisionTreeClassifier 熵/gini系数决策树模型、以及RandomForestClassifier随机森林模型进行分类;
训练集:测试集=8:2
结果:返回模型评价结果、导出DecisionTreeClassifier 熵/gini系数决策树模型生成的决策树.dot文件并,生成png格式决策树图片。
注意: 相同的数据集,因算法训练过程中有用到随机算法,如果random_state参数不设置,那么每次执行模型将会生成不一样的结果,如果模型投入生产会产生很不好的影响,过程中任何涉及随机算法都需要注意。
#!/usr/bin/evn python # -*-coding:utf8 -*- ''' 鸢尾花经典数据处理: # 数据获取: # http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data import requests content = requests.get('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data') file = open('F:\\kettle\\tbsales\\pyhon_seana\\testresult\\liris_data.txt', "ab+") file.write(content.text.encode('utf-8')) # data_ = pd.read_excel(r'F:\kettle\tbsales\pyhon_seana\chapter5\demo\data\sales_data.xls',index_col=u'序号') ''' iris_data = [] with open('F:\\kettle\\tbsales\\pyhon_seana\\testresult\\liris_data.txt', "r") as filereader: for line in filereader.readlines()[:150]: line = line.replace('\n','') iris_data.append(line.split(',')) filereader.close() import pandas as pd data = pd.DataFrame(iris_data) data.columns = ['sepal_length','sepal_width','petal_length','petal_width','iris_type'] data = data.sample(frac=1,random_state=10).reset_index(drop=True) #随机打乱数据顺序提高模型准确性,设置随机参数,否则每次运行结果将会不同。 test_weight = 0.8 x_train = data.iloc[:int(len(data)*test_weight), 0:4] y_train = data.iloc[:int(len(data)*test_weight), 4] X_test = data.iloc[int(len(data)*test_weight):, 0:4] y_test = data.iloc[int(len(data)*test_weight):, 4] from sklearn.tree import DecisionTreeClassifier as DTC from sklearn.ensemble import RandomForestClassifier as RFC dtc_en = DTC(criterion='entropy',random_state=0)#熵 ,确定随机参数,否则每次运行模型结果不同 dtc_gn = DTC(criterion='gini',random_state=0)#gini系数 rfc = RFC(n_estimators=1000, random_state=10) dtc_en.fit(x_train, y_train) dtc_gn.fit(x_train, y_train) rfc.fit(x_train, y_train) dtc_en_pred = dtc_en.predict(X_test) dtc_gn_pred = dtc_gn.predict(X_test) rfc_pred = rfc.predict(X_test) from sklearn.metrics import confusion_matrix, classification_report dtc_en_score = classification_report(y_test, y_pred=dtc_en_pred) dtc_gn_score = classification_report(y_test, y_pred=dtc_gn_pred) dtc_rf_score = classification_report(y_test, y_pred=rfc_pred) print('dtc_en_score 模型综合评估矩阵如下:\n',dtc_en_score) print('dtc_gn_score 模型综合评估矩阵如下:\n',dtc_gn_score) print('dtc_rf_score 模型综合评估矩阵如下:\n',dtc_rf_score) from sklearn.tree import export_graphviz import numpy as np data_feature_name = data.columns[:-1]#数据列名 data_target_name = np.unique(data[data.columns[-1]])#分类列数据类别名 #信息熵/gini系数模型生成dot文件 with open("F:\\kettle\\tbsales\\pyhon_seana\\testresult\\dtc_en_iristree.dot", 'w') as f: f = export_graphviz(dtc_en, feature_names=data_feature_name,class_names=data_target_name, out_file=f,special_characters=True) with open("F:\\kettle\\tbsales\\pyhon_seana\\testresult\\dtc_gn_iristree.dot", 'w') as f: f = export_graphviz(dtc_gn, feature_names=data_feature_name,class_names=data_target_name, out_file=f,special_characters=True) #生成png图片--注意中文会显示框框乱码,代码暂时没找到解决方法,目前含中文分类都用GVEidt打开,外加一句代码(下文) import pydotplus,os from IPython.display import Image os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.37/bin/' dot_tree_en = export_graphviz(dtc_en,out_file=None,feature_names=data_feature_name,class_names=data_target_name,filled=True, rounded=True,special_characters=True) graph = pydotplus.graph_from_dot_data(dot_tree_en) img = Image(graph.create_png()) graph.write_png("F:\\kettle\\tbsales\\pyhon_seana\\testresult\\dtc_en.png")#图片中文乱码未解决
运行结果:
dtc_en_score 模型综合评估矩阵如下: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 9 Iris-versicolor 1.00 1.00 1.00 9 Iris-virginica 1.00 1.00 1.00 12 avg / total 1.00 1.00 1.00 30 dtc_gn_score 模型综合评估矩阵如下: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 9 Iris-versicolor 1.00 1.00 1.00 9 Iris-virginica 1.00 1.00 1.00 12 avg / total 1.00 1.00 1.00 30 dtc_rf_score 模型综合评估矩阵如下: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 9 Iris-versicolor 1.00 0.89 0.94 9 Iris-virginica 0.92 1.00 0.96 12 avg / total 0.97 0.97 0.97 30
决策树-此处只生成熵生成的图片,gini系数生成树状相同,只是里面熵值换成了gini值。
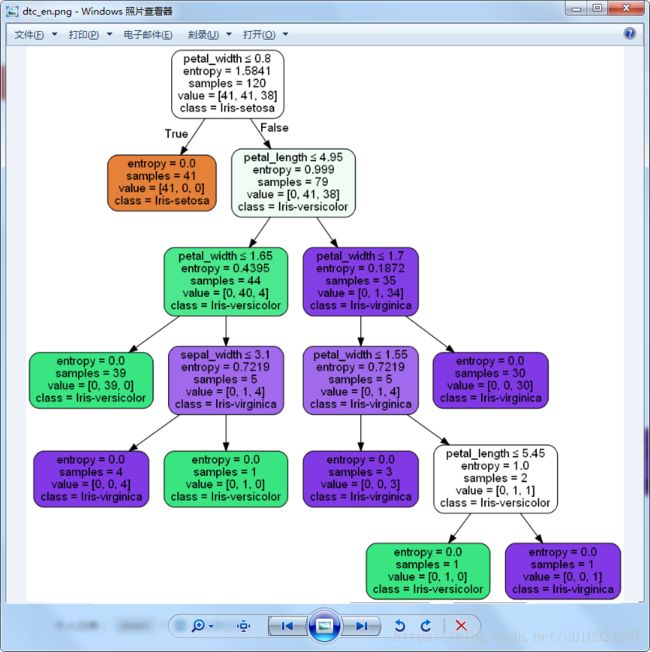
dot文件的处理:
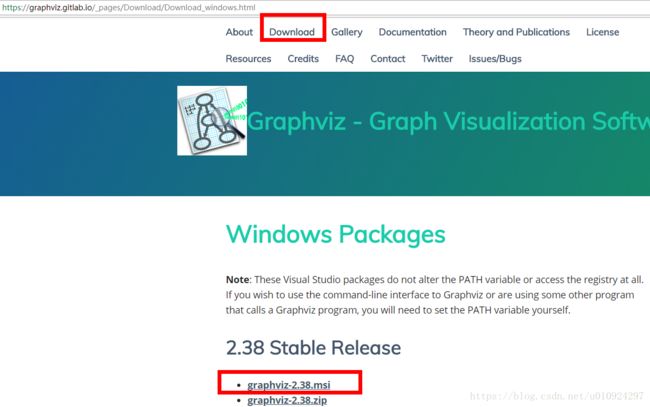
1、安装Graphviz----地址:https://graphviz.gitlab.io/_pages/Download/Download_windows.html graphviz-2.38.msi
我是Windows版本,zip包直接解压不需要安装,但我是没有找到GVEdit,安装mis后缀文件就直接所有程序很快找到。
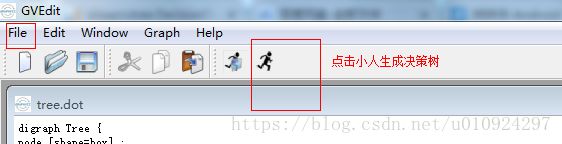
2、打开文件,一般选择打开文件即自动生成决策树,当代码修改后点击小人可以生成决策树。
3、决策树中文乱码的情况---目前个人试过pdf或者是png或者dot文件,含有中文分类标签的乱码成框框,可能经验太少,目前只发现一种解决的办法,就是GVEdit里面打开,加一行代码~~
中文乱码:
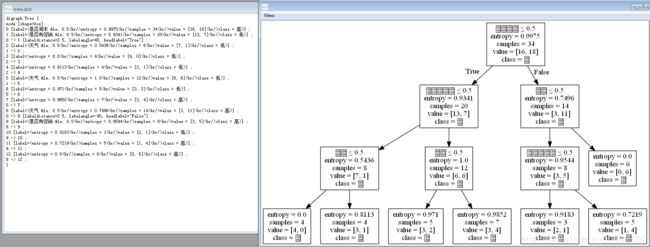
添加代码:node[fontname = "PMingLiu"];
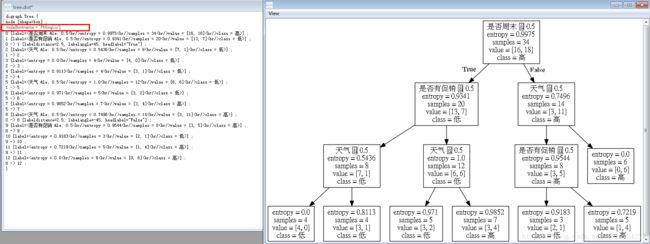
png以及pdf文件乱码尚未解决~要是大神路过求指教~~~