基于 ELK 的 mongo 日志分析简单实践
基于Elk 的日志分析简单实践
- 基于Elk 的日志分析简单实践
-
- 前言
- Elk 简介
- 部署
- logstash
- 1. 数据源输入
- 2. 日志分析和过滤
- 3. 输出至 elastcisearch。
- Kibana
- 1. Setting
- 2. Discover
- 3. Visualize
- logstash
- 应用场景发散
- 问题总结与优化
- 参考资料
-
前言
Elk 是 ElasticSearch + logstash + kibana 的缩写,是一套集成的开源日志分析平台。作为当前最流行的日志分析平台,有着很多的天然优势。易部署,跨平台,高效的日志解析引擎和搜索引擎,以及非常强大的可视化平台,受到很多运维人员的青睐。
之前一直有做这方面的尝试,比如二进制审计日志分析,常用的 oplog 日志分析等等。但是因为受限于某些原因没能坚持下去。正好这次受到组内有人做的 mongo 数据库监控项目的启发,觉得使用 elk 平台会更加方便,于是重新开始尝试了一下。
Elk 简介
以下是 elk 的整体架构, logstash-forword 是日志采集器,负责从各个服务器上采集日志信息,可以是文本或者二进制形式的日志。logstash 负责将采集的日志解析出来,映射成es 的字段名,并存入 es 中,而 Kibana 提供了可视化的分析平台,可以基于es 的数据生成各种报表。

部署
由于整套方案都是基于java的,所以跨平台性很好,无需安装,下载之后即可运行。以下实践结果基于测试环境,es 运行在服务器 127.0.0.1,logstash 和 kibana 运行在服务器 200.200.107.249。使用的版本分别为elasticsearch-2.3 , kibana-4.5.4 , logstash-5.3.2 [ 附官方下载地址 ]。此外要注意 es 和 kibana 的版本保持对应。
| kibana 版本 | es 版本 |
|---|---|
| 4.1 | 1.4.4+ |
| 4.2 | 2.0+ |
| 4.3 | 2.1+ |
| 4.4 | 2.2+ |
| 4.5 | 2.3+ |
| 4.6 | 2.4+ |
| 4.7 | 5.0+ |
logstash
logstash 可以指定配置文件运行,配置文件中指定了关联的 ES 的地址以及日志解析方式。在 config/ 目录下copy 一份默认的配置文件,命名为 mongo-lostash.conf。 配置文件主要指定三件事:输入—解析—输出。
1. 数据源输入
这里直接指定 mongo 日志的路径, 如果有多种类型的日志,可以指定 type 标志来区分。
input {
file { //当输入源是文件时
path => "/home/moa/db/mongodb/log/mongod.log"
type => "mongolog"
}
}2. 日志分析和过滤
filter 将 input 的结果进行处理,并转为 es 中对应的字段。以下是对 type 为 mongolog 的日志进行处理。grok 是logstash 内置的正则解析引擎,包含丰富的正则表达式。
那么接下来是对于 mongo 日志的解析。根据 mongo 官网 (日志规范 )对日志的描述,mongo3.0 以上版本的日志格式为:
[]
@timestamp : 时间
@severity : 日志级别,分为: F(Fatal)/E(Error)/W(Warning)/I(Informational)/D(Debug)
@component: 包括 /NETWORK/ACCESS/COMMMAND/GEO/INDEX/QUERY/ROLLBACK/SHARDING/JOURNAL/WRITE 等
@context: 上下文,主要打印数据库连接
@message: 具体的日志数据 其中 compoent = COMMAND 基本涵盖了大部分的增删改查等数据库操作,这一部分的 message 是我们需要具体关注的。以下是部分有代表性的日志
// NETWROK 建立连接的日志
2018-01-02T10:47:02.253+0800 I NETWORK [initandlisten] connection accepted from anonymous unix socket #179873 (349 connections now open)
// ACCESS 接入失败的日志
2016-09-24T02:01:03.404+0800 I ACCESS [conn2232] Failed to authenticate Opt_ALL@admin with mechanism MONGODB-CR: AuthenticationFailed UserNotFound Could not find user Opt_ALL@admin
// COMMAND 日志
2016-08-14T19:08:54.569+0800 I COMMAND [conn4521] insert im.user_msg ninserted:1 keyUpdates:0 writeConflicts:0 numYields:0 locks:{ Global: { acquireCount: { r: 1, w: 1 } }, Database: { acquireCount: { w: 1 } }, Collection: { acquireCount: { w: 1 } } } 492ms
2018-01-03T13:28:17.308+0800 I COMMAND [conn9678] query task.opt_log query: { query: { did: 519390, taskid: 172 }, orderby: { opt_time: -1 } } planSummary: IXSCAN { did: 1.0, taskid: 1.0, opt_time: 1.0 } ntoreturn:3 ntoskip:0 nscanned:2 nscannedObjects:2 keyUpdates:0 writeConflicts:0 numYields:2 nreturned:2 reslen:429 locks:{ Global: { acquireCount: { r: 6 } }, Database: { acquireCount: { r: 3 } }, Collection: { acquireCount: { r: 3 } } } 120ms
2016-08-14T19:09:02.836+0800 I COMMAND [conn4521] remove im.user_msg query: { did: 10000, pid: 8445, msg_id: { $lte: 510 } } ndeleted:100 keyUpdates:0 writeConflicts:0 numYields:1 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 2 } } } 212ms以上述 COMMAND 类型的日志为例,其 message 部分又可以拆分出以下的格式
@command_type : 操作类型,比如 query/insert/update/remove/getmore(迭代返回) 等等
@databasename : 操作的数据库,比如 im.user_msg
@command_detail : 会输出具体的 queryplan,如果是全表扫描会出现 COLL_SCAN 之类的关键词
@spend_time : 花费时间,单位是 ms 通过对以上的mongo日志格式分析,我们现在就可以使用grok 解析出这些字段。 grok 内置了大部分的正则表达式,可以直接当做标签使用,比如用于匹配时间的 TIMESTAMP_ISO8601,MONGO3_SEVERITY 等等。每个标签后面可以指定这部分匹配结果的字段名。
先解析整行日志,然后再解析 component=COMMAND 日志的内容,从而得到操作信息和数据库信息等。
filter {
if [type] == "mongolog" {
grok {
match => ["message","%{TIMESTAMP_ISO8601:timestamp}\s+%{MONGO3_SEVERITY:severity}\s+%{MONGO3_COMPONENT:component}\s+(?:\[%{DATA:context}\])?\s+%{GREEDYDATA:body}"]
}
if [component] =~ "COMMAND" {
grok {
match => ["body","%{WORD:command_type}\s+%{DATA:db_name}\s+\w+\:\s+%{GREEDYDATA:command}\s+%{INT:spend_time}ms$"]
}
}
date {
match => [ "timestamp","UNIX", "YYYY-MM-dd HH:mm:ss", "ISO8601"]
remove_field => [ "timestamp" ]
}
}
}3. 输出至 elastcisearch。
指定 es 的 host 和索引。另外测试结果输出一份到屏幕便于观察。
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "mongolog"
}
stdout {
codec => rubydebug
}
}配置文件搞定之后就可以运行
bin/logstash -f config/mongo-logstash.conf为了验证 logstash 的结果,重启下moa 服务,可以看到有大量的接入请求和查询请求。
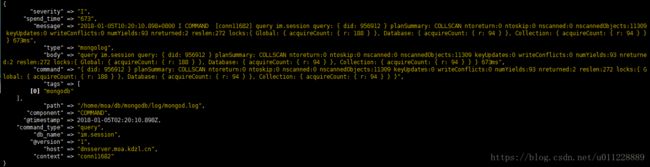
同时在es 服务器 127.0.0.1:9200上也可以看到数据

Kibana
kibana 是在es 数据的基础上进行可视化的分析并生成各种报表。在配置文件中指定es 的地址,并运行即可
#修改配置文件为如下所示
[root@dnsserver ~]# cat /usr/local/kibana/config/kibana.yml | grep elasticsearch.url
elasticsearch.url: "http://127.0.0.1:9200"
#运行
[root@dnsserver ~]# bin/kibana kibana 主界面分为 Discover 、Visualize、DashBoard、Setting。Discover用于查看所有元数据,Visualize 用于生成报表和图形,DashBorad 可以将 Visulalize 生成的多个结果放在一起对比。
1. Setting
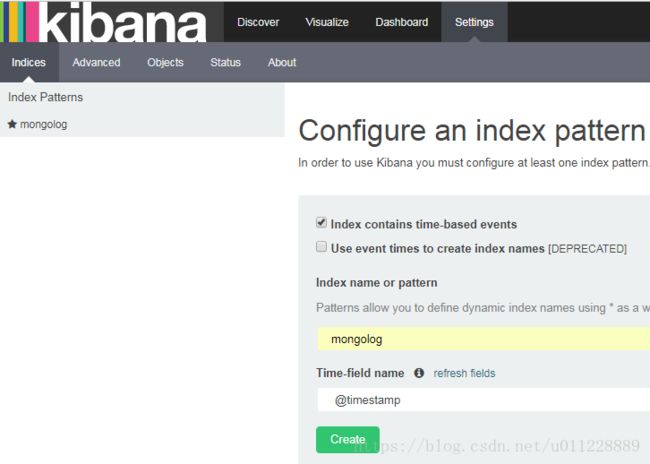
先在setting 界面新增一个 index_pattern,选择一个需要分析的索引,可以使用正则表达式匹配多个索引进行分析。logstash 会自动为每条数据生成一个时间相关的字段@timestamp 。
2. Discover
Discover 看到的是es 元数据,默认只显示最近15 分钟的数据,如果需要查看更多,可以修改右上角的timefilter。可以用正则去搜索数据,并保存正则表达式用于多次搜索。

图- timefilter
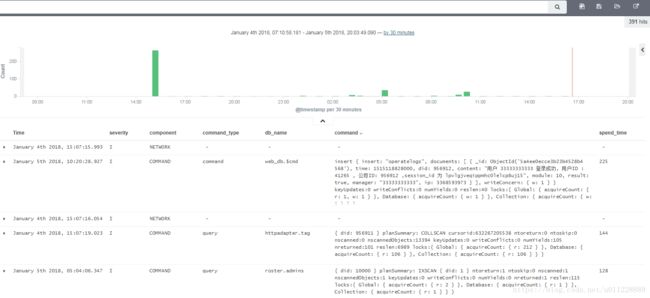
图- Discover界面的数据
3. Visualize
Visualize 可以生成多种类型的图表,并支持保存。

比如需要查看一段时间内数据库所有表的查询次数,以直方图的形式展现出来。
根据一段时间内数据库查询生成所有表的查询次数直方图
应用场景发散
可以看到上述平台几乎可以非常轻松的搭建在任何服务器上,使得对文本型日志的监控运维更方便更高效。
如果线下专门搭建一个用于分析的 es 服务器,定时从线上数据库的副本同步数据到本地,可以进行各种分析。
- 比如现在领导们需要看一些统计报表,就可以不需要我们去写脚本运行了(当然建立合适的索引是es能否胜任报表分析维度的关键)。
- 比如现在的统计需求,如果产品那边不要求实时性的话,我们完全可以摒弃掉使用程序接口来统计数据的方式。这样极大提高生产力。
问题总结与优化
- 日志写入速率和 ES 导入数据速率不匹配的情况。如果用于线上大型的日志收集的话,这是可能出现的一种情况,logstash 作为一个管道,并没有缓存数据的功能,需要额外加入中间件来保证日志的写入速率和数据导入数据匹配。
- 线下测试环境发现,ES 服务器的单个进程可用文件描述符应开到2048以上,否则容易出现文件描述符不够用的情况,导致 logstash 无法写入数据。
- 对于日志采集端来说,logstash 其实是很重的组件,可以考虑使用更加轻量的 filebeats 来作为日志采集器,提高服务器性能的利用率。
- 当前没有使用大量的数据进行压力测试,因此对es 的性能问题无法全面的估计。
- 整个环境的部署可以进一步集成和简化,将相应版本的安装包和配置文件上传到 SVN,然后在任意服务器均可打包安装。
参考资料
kibana官方文档:https://www.elastic.co/guide/en/kibana/current/index.html
官方下载地址: https://www.elastic.co/downloads