记一次堆外内存溢出排查过程
一、内存溢出现象
异常堆栈:
top 信息:
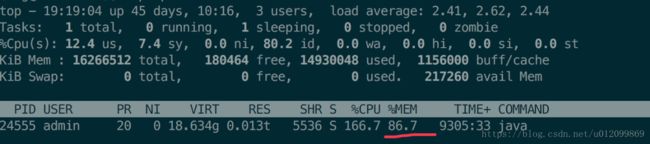
现象描述:
服务器发布/重启后,进程占用内存 21% 3g 左右,观察进程占用内存,以一天5%左右的速度增长,一定时间过后,java 进程内存增长到接近 90%,服务器报警。此时 old 区内存在 50%左右,由于未达到 CMS GC 的阈值,因此不会触发 CMS GC,而导致服务器内存溢出崩溃。
JVM配置:
8核16G
JVM 参数:
-Xms8g (初始化堆内存8g)
-Xmx8g (最大堆内存8g)
-Xmn3g (young 区3g)
-Xss512k (线程堆栈大小)
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
-XX:-UseGCOverheadLimit (不限制GC运行时间)
-XX:+DisableExplicitGC (不允许 System.gc())
-XX:+UseConcMarkSweepGC (ParNew+CMS+Serial Old收集器组合进行垃圾收集。Serial Old作为CMS收集器出现Concurrent Mode Failure的备用垃圾收集器。)
-XX:+CMSParallelRemarkEnabled (允许并发标记,针对 CMS 收集器)
-XX:+UseCMSInitiatingOccupancyOnly (通过 CMSInitiatingOccupancyFraction 进行每一次 CMS 收集)
-XX:+UseFastAccessorMethods (原始类型的快速优化)
-XX:CMSInitiatingOccupancyFraction=70 (old 区达到70%执行 CMS GC)
二、排查过程
1.异常堆栈分析
根据异常堆栈,可看出是因为调用 hbase.write() 分配直接内存导致的堆外内存溢出。
观察 JVM 参数,未设置直接内存大小参数: -XX:MaxDirectMemorySize ,CMS GC 情况下直接内存大小为: Young 区 - 一个Survivor区 + Old 区,此处大约 7.8G。
JVM 申请直接内存时,会判断是否超过可申请的直接内存阈值,如果超过则会调用 System.gc() 触发GC,如果 GC 后内存还是不足,则抛出 OutOfMemoryError 异常。而此处设置了 -XX:+DisableExplicitGC 禁止了 System.gc() 操作。
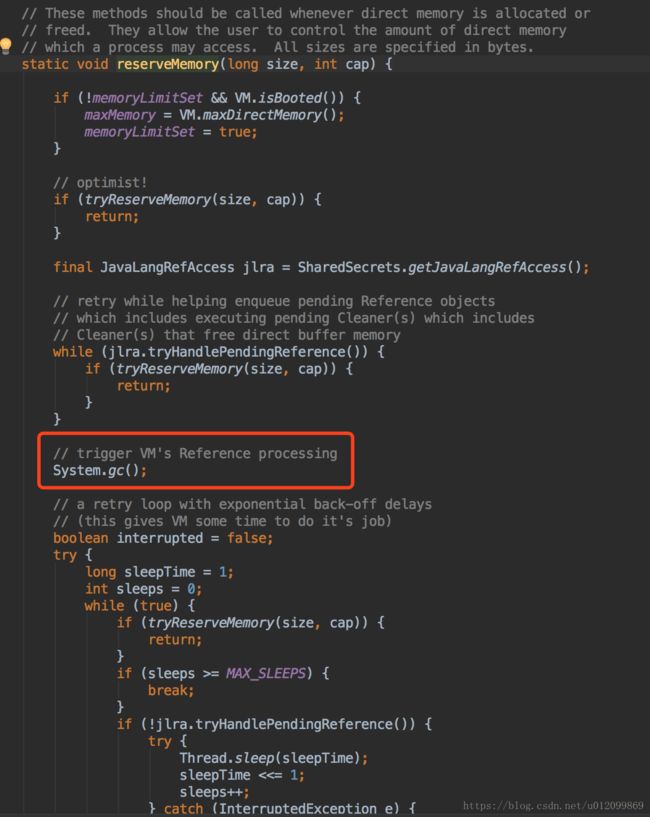
此处可用 -XX:+ExplicitGCInvokesConcurrent 代替 -XX:+DisableExplicitGC 的参数,通过 并行 GC 的方式,提升 System.gc() 的效率。但为了找出具体原因,此处先不修改。
于是打算现在性能环境压测,看是否能复现内存溢出现象。
2.压测主流程接口
压测调用比较频繁的主流程接口。压测方式:使用 jmeter 压测调用量比较大的主流程接口。
但压测之后一段时间之后,观察堆内存和进程内存均增长缓慢,且未出现堆外内存溢出现象。
3.hbase client 资源释放
主流程压测未复现问题,此时将目光转到异常堆栈上,观察 hbase client 使用方式,发现调用 write(), read() 等方法之后未调用 close() 方法释放资源,查看 close() 方法(具体实现查看 HTable.close() 源码):
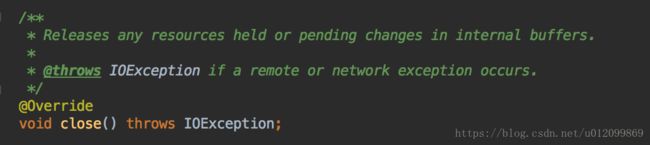
因此加上 close() ,并进行线上验证:

上线后观察了几天,发现虽然堆外内存分配少了一些,但一段时间后还是会溢出,因此问题不在于资源的释放上。
4.压测特定功能
主流程压测未出现问题,也不是 hbase client 资源未释放的问题。但 hbase 肯定有问题,结合前面 HTable 未 close() ,因此方向调整为: hbase client OOM: direct buffer memory,查找资料发现 hbase 的 issue 列表里有一个内存溢出的 case:document the mysterious direct memory leak in hbase
在关联的一篇文章中,找到了相同的异常堆栈:

文章中列举的原因,是使用了由于 Java NIO HeapByteBuffer ,如果有 IO 操作,JDK 会在堆外复制一个临时的 DirectByteBuffer 对象,并缓存该对象,且不限制对象大小,如果线程一直存活,则可能导致内存溢出(内存溢出分析之垃圾回收知识):

查看 dump 文件 java.nio.ByteBuffer[] 垃圾回收根节点,发现引用对象是 HConnection 对象,该对象在项目初始化时创建,并一直存活:

再查看 hbase client 1.2.3 源码,果然调用的是 HeapByteBuffer (具体查看源码)。基本和前面 hbase issue 描述的一致。
系统中用到的 hbase 接口主要为读写两个接口,于是单独压测这两个接口,一次性读写/写入400条数据(约68k):

但压测一段时间后,并无内存溢出现象,且堆外内存并无明显变化。此时陷入了迷茫。
再观察 issue 里提到的,统计所有大于 4M 的 DirectByteBuffer 对象:

想到线上内存一天增长大概5%(大概800M),增长比较缓慢,说明偶尔有往 hbase 大量写入的请求,查询线上日志,发现每天都有几个请求写入1000条以上数据,1000条数据大概170k,因此前面压测写入的数据量可能太小了。
想到这里,将写入数据量调整为 10万 (大约 17M):

运行半小时左右,果然出现堆外内存溢出:
同时观察 gperftools, jvisual VM 监控,发现分配了大量的直接内存:
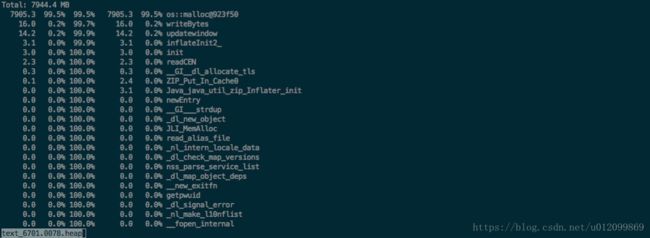
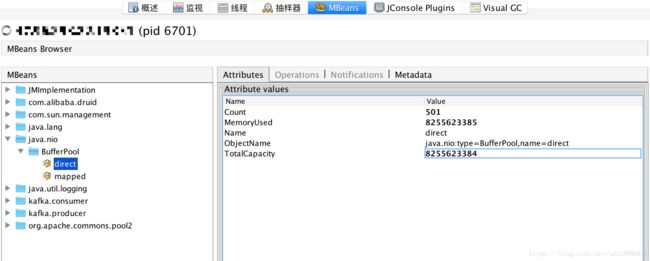
至此,实锤 hbase client 是导致堆外内存溢出的一个原因。
5.升级 hbase client 至 2.x
至此,能确定 hbase client 是导致堆外内存溢出的其中一个原因,查看官方版本,发现 2.x 选用了 Netty 作为实现 NIO 的框架,更好的管理直接内存,因此将 hbase client 升级为 2.1.0。
上线观察几天之后,与升级之前相比,相同 old 区占用情况下,堆外内存占用远小于升级之前。目前堆外内存增长速度平缓,系统比较稳定。
三、相关知识
堆外内存计算方式
广义堆外内存为:进程内存 - (Young 区占用 + Old 区占用)
狭义堆外内存为:java.nio.DirectByteBuffer 创建的时候分配的内存。
查看堆内存命令
jstat -gc 1000 : 每秒输出堆内存实际大小信息
jstat -gcutil 1000 : 每秒输出堆内存百分比信息
关联文章
内存溢出分析之工具篇
内存溢出分析之垃圾回收知识
document the mysterious direct memory leak in hbase
java-bytebuffer-leak
JVM源码分析之堆外内存完全解读
JVM源码分析之不可控的堆外内存