28.MyBatis应用分析与最佳实践
1.为什么使用mybatis
1.1.JDBC连接数据库
// 注册 JDBC 驱动
Class.forName("com.mysql.jdbc.Driver");
// 打开连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/gp-mybatis", "root", "123456");
// 执行查询
stmt = conn.createStatement();
String sql = "SELECT bid, name, author_id FROM blog where bid = 1";
ResultSet rs = stmt.executeQuery(sql);
// 获取结果集
while (rs.next()) {
Integer bid = rs.getInt("bid");
String name = rs.getString("name");
String authorId = rs.getInt("author_id");
blog.setAuthorId(authorId);
blog.setBid(bid);
blog.setName(name);
}
首 先 ,在 pom.xml中引入MySQL驱动的依赖。
第一步,Class.forName注册驱动。
第二步,获取一个Connection第三步,创建一个Statement对象。
第四步,execute方法执行SQL。execute方法返回一个ResultSet结果集。
第五步,通过ResultSet获取数据,给 POJO的属性赋值。
第六步,关闭数据库相关的资源,包括ResultSet、Statement、Connection。
JDBC连接数据库的问题
1、 重复代码
2、 资源管理
3、 结果集处理
4、 SQL耦合
1.2.Spring JDBC
Spring对原生的JDBC进行了封装。解决了以下问题:
1、代码重复一一Spring提供了一个模板方法JdbcTemplate,里面封装了各种各样
的 execute, query 和 update 方法。 JDBCTemplate这个类 :
它是JDCB的核心包的中心类。简化了 JDBC的使用,可以避免常见的异常。它封装了 JDBC的核心流程,应用只要提供SQL,提取结果集就可以了。它是线程安全的。
初始化的时候可以设置数据源,所以资源管理的问题也可以解决。
2、对结果集处理,Spring JDBC提供了一个RowMapper接口,可以把结果集转换成Java对象,它作为JdbcTemplate的参数使用。
Spring JDBC,对JDBC做了轻量级封装的框架,帮助我们解决的问题:
1、 对操作数据的增删改查的方法进行了封装;
2、 无论是QueryRunner还是JdbcTemplate,都可以传入一个数据源进行初始化,也就是资源管理这一部分的事情,可以交给专门的数据源组件去做,不用我们手动创建和关闭;
3、 可以帮助我们映射结果集,无论是映射成List、Map还是POJO。
但仍存在不足:
1、 SQL语句都是写死在代码里面的,依旧存在硬编码的问题;
2、 参数只能按固定位置的顺序传入(数组), 它是通过占位符去替换的不能传入
对象和Map,不能自动映射;
3、 在方法里面,可以把结果集映射成实体类,但是不能直接把实体类映射成数据
库的记录(没有自动生成SQL的功能);
4、 查询没有缓存的功能,性能还不够好。
要解决这些问题,使用这些工具类还是不够的,这个时候用到ORM框架了。
1.3.Hibernate
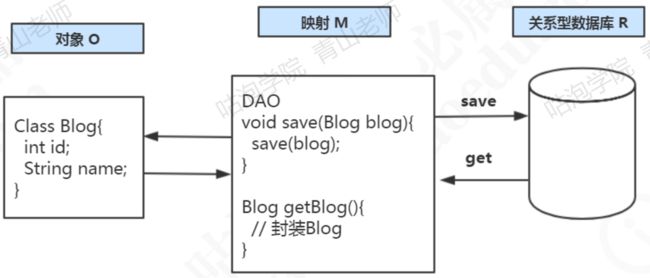
什么是ORM?为什么叫ORM?
ORM的全拼是Object Relational Mapping,也就是对象与关系的映射,对象是程
序里面的对象,关系是它与数据库里面的数据的关系。也就是说,ORM框架帮助我们解
决的问题是程序对象和关系型数据库的相互映射的问题。
O:对象—— M :映射—— R :关系型数据库
总 结 Hibernate的特性:
1、 根据数据库方言自动生成SQ L,移植性好;
2、 自动管理连接资源(支持数据源);
3、 实现了对象和关系型数据库的完全映射,操作对象就像操作数据库记录一样;
4、 提供了缓存功能机制。
Hibernate问题:
1、比如使用get、update()、save( ) 对象的这种方式,实际操作的是所有字段, 没有办法指定部分字段,换句话说就是不够灵活。
2、自动生成SQL的方式,如果要基于SQL去做一些优化的话,是非常困难的,也就是说可能会出现性能的问题。
3、不支持动态SQ L,比如分表中的表名、条件、参数变化等,无法根据条件自动生
成 SQL。
我们需要一个更加灵活的框架。
1.4.MyBatis
MyBatis 的前身是 ibatis, 2001 年开始开发,是 "internet"和 "abatis(障碍物)"两个单词的组合。04年捐赠给Apache。2010年更名为MyBatis。
在 MyBatis里面,SQL和代码是分离的,所以会写SQL基本上就会用MyBatis,没有额外的学习成本。
2.myBatis使用案例
2.1.MyBatis API方式
先引入 mybatis jar包。
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.4-snapshotversion>
dependency>
创建一个全局配置文件,这里面是对MyBatis的核心行为的控制,比如
mybatis-config.xml。这里面只定义的数据源和Mapper映射器路径。
<configuration>
<properties resource="db.properties">properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
dataSource>
environment>
environments>
<mappers>
<mapper resource="BlogMapper.xml"/>
mappers>
configuration>
db.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8&rewriteBatchedStatements=true
jdbc.username=root
jdbc.password=123456
第二个就是我们的映射器文件:Mapper.xml,通常来说一张表对应一个,我们会在 这个里面配置我们增删改查的SQL语句,以及参数和返回的结果集的映射关系。
<mapper namespace="com.gupaoedu.mapper.BlogMapper">
<resultMap id="BaseResultMap" type="blog">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<result column="author_id" property="authorId" jdbcType="INTEGER"/>
resultMap>
<select id="selectBlogById" resultMap="BaseResultMap" statementType="PREPARED" >
select * from blog where bid = #{bid}
select>
mapper>
配置好了,怎么通过MyBatis执行一个查询呢?
既然MyBatis的目的是简化JDBC的操作,那么它必须要提供一个可以执行增删改 查的对象,这个对象就是SqISession接口,我们把它理解为跟数据库的一个连接,或者一次会话。
SqISession怎么创建呢?因为数据源、MyBatis核心行为的控制(例如是否开启缓 存)都在全局配置文件中,所以必须基于全局配置文件创建。这里它不是直接new出来 的,而是通过一个工厂类创建的。
所以整个的流程就是这样的(如下代码)。最后我们通过SqISession接口上的方法,
传入我们的Statement ID来执行Mapper映射器中的SQL。
@Before
public void prepare() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
/**
* 使用 MyBatis API方式
* @throws IOException
*/
@Test
public void testStatement() throws IOException {
SqlSession session = sqlSessionFactory.openSession();
try {
Blog blog = (Blog) session.selectOne("com.gupaoedu.mapper.BlogMapper.selectBlogById", 1);
System.out.println(blog);
} finally {
session.close();
}
}
通过这样的调用方式,解决了重复代码、资源管理、SQL耦合、结果集映射这4大问题。
但仍存在下面问题:
(1) Statement ID是硬编码,维护起来很不方便;
(2) 不能在编译时进行类型检查,如果namespace或者Statement ID输错了,
只能在运行的时候报错。
2.2.Mapper接口方式
所以我们通常会使用第二种方式,也是新版的MyBatis里面推荐的方式:定义一个
Mapper接口的方式。这个接口全路径必须跟Mapper.xml里面的namespace对应起 来,方法也要跟Statement ID---- 对应。
/**
* 通过 SqlSession.getMapper(XXXMapper.class) 接口方式
* @throws IOException
*/
@Test
public void testSelect() throws IOException {
SqlSession session = sqlSessionFactory.openSession(); // ExecutorType.BATCH
try {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlogById(1);
System.out.println(blog);
} finally {
session.close();
}
}
MyBatis的核心特性/解决主要的问题:
- 使用连接池对连接进行管理
- SQL和代码分离,集中管理
- 结果集映射
- 参数映射和
- 动态SQL
- 重复SQL的提取
- 缓存管理
- 插件机制
3.核心对象的生命周期
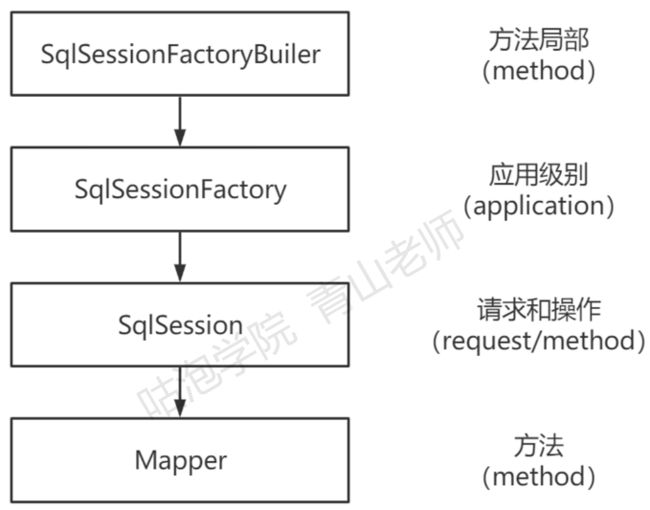
MyBatis里面的几个核心对象:
SqISessionFactoryBuiler、 SqISessionFactory、 SqlSession 和 Mapper 对象。这几个
核心对象在MyBatis的整个工作流程里面的不同环节发挥作用。如果说我们不用容器, 自己去管理这些对象的话,我们必须思考一个问题:什么时候创建和销毁这些对象?
1) SqISessionFactoryBuiler
首先是 SqISessionFactoryBuiler它是用来构建 SqISessionFactory 的 ,而 SqISessionFactory只需要一个,所以只要构建了这一个SqISessionFactory,它的使命
就完成了,也就没有存在的意义了。所以它的生命周期只存在于方法的局部。
2) SqISessionFactory (单例)
SqISessionFactory是用来创建SqISession的,每次应用程序访问数据库,都需要
创建一个会话。因为我们一直有创建会话的需要,所以SqISessionFactory应该存在于 应用的整个生命周期中(作用域是应用作用域)。创建SqISession只需要一个实例来做 这件事就行了,否则会产生很多的混乱,和浪费资源。所以我们要采用单例模式。
3) SqISession
SqISession是一个会话,因为它不是线程安全的,不能在线程间共享。所以我们在 请求开始的时候创建一个SqISession对象,在请求结束或者说方法执行完毕的时候要及
时关闭它(一次请求或者操作中)。
4) Mapper
Mapper (实际上是一个代理对象)是从SqISession中获取的。
BlogMapper mapper = session.getMapper(BlogMapper.class);
它的作用是发送SQL来操作数据库的数据。它应该在一个SqISession事务方法之
内。
总结如下:
4.核心配置解读
第一个是config文件。
一级标签
4.1.configuration
configuration是整个配置文件的根标签,实际上也对应着MyBatis里面最重要的配置类Configuration。它贯穿MyBatis执行流程的每一个环节。我们打开这个类看一 下,这里面有很多的属性,跟其他的子标签也能对应上。
4.2.properties
第一个一级标签是properties,用来配置参数信息,比如最常见的数据库连接信息。
为了避免直接把参数写死在xml配置文件中,我们可以把这些参数单独放在 properties文件中,用 properties标签引入进来,然 后 在 xml配置文件中用${}引用就
可以了。
可以用resource引用应用里面的相对路径,也可以用url指定本地服务器或者网络
的绝对路径。
4.3.settings
settlings里面是 MyBatis的一些核心配置。
4.4.typeAlias
TypeAlias是类型的别名,跟 Linux系统里面的alias一样,主要用来简化类名全路 径的拼写。比如我们的参数类型和返回值类型都可能会用到我们的Bean,如果每个地方 都配置全路径的话,那么内容就比较多,还可能会写错。
我们可以为自己的Bean创建别名,既可以指定单个类,也可以指定一个package,
自动转换。
<typeAliases>
<typeAlias alias="blog" type="com.gupaoedu.domain.Blog" />
typeAliases>
配 置 了 别 名 以 后 ,在 配 置 文 件 中 只 需 要 写 别 名 就 可 以 了 ,比如
com.gupaoedu.domain.Blog 可以简化成 blog
<select id="selectBlogByBean" parameterType="blog" resultType="blog" >
select bid, name, author_id authorId from blog where name = '${name}'
select>
MyBatis里面有很多系统预先定义好的类型别名,在 TypeAliasRegistry中。所以可 以用 string 代替 java.lang.String。
4.5.typeHandlers
由于Java类型和数据库的JDBC类型不是— 对应的(比如String与varchar、char、
text), 所以我们把Java对象转换为数据库的值,和把数据库的值转换成Java对象,需 要经过一定的转换,这两个方向的转换就要用到TypeHandler
当参数类型和返回值是一个对象的时候,我没有做任何的配置,为什么对象里面的
个 String属性,可以转换成数据库里面的varchar字段?
这是因为MyBatis已经内置了很多TypeHandler (在 type包下), 它们全部全部 注册在TypeHandlerRegistry中,他们都继承了抽象类BaseTypeHandler,泛型就是要
处理的Java数据类型。
如果我们需要自定义一些类型转换规则,或者要在处理类型的时候做一些特殊的动
作,就可以编写自己的TypeHandler,跟系统自定义的TypeHandler —样,继承抽象类 BaseTypeHandler
set方法从Java类型转换成JDBC类型的,get方法是从JDBC类型转换成Java类
型的。
| 从 Java类型到JDBC类型 | 从 JDBC类型到Java类型 |
|---|---|
| setNonNullParameter:设置非空参数 | getNullableResult:获取空结果集(根据列名),一般都是调用这个 getNullableResult:获取空结果集(根据下标值) getNullableResult:存储过程用的 |
举个例子:
一个商户,在登记的时候需要注册它的经营范围。比如1手机,2电脑,3相机,4
平板,在界面上是一个复选框(checkbox)
在数据库保存的是用逗号分隔的字符串,例 如 “1,3,4”, 而返回给程序的时候是整
形数组{1,3,4}。
在每次获取数据的时候转换?还是在bean的get方法里面转换?似乎都不太合适。
这时候我们可以写一个lnteger[]类型的TypeHandler。
public class MyTypeHandler extends BaseTypeHandler<String> {
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType)
throws SQLException {
// 设置 String 类型的参数的时候调用,Java类型到JDBC类型
// 注意只有在字段上添加typeHandler属性才会生效
// insertBlog name字段
System.out.println("---------------setNonNullParameter1:"+parameter);
ps.setString(i, parameter);
}
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
// 根据列名获取 String 类型的参数的时候调用,JDBC类型到java类型
// 注意只有在字段上添加typeHandler属性才会生效
System.out.println("---------------getNullableResult1:"+columnName);
return rs.getString(columnName);
}
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
// 根据下标获取 String 类型的参数的时候调用
System.out.println("---------------getNullableResult2:"+columnIndex);
return rs.getString(columnIndex);
}
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
System.out.println("---------------getNullableResult3:");
return cs.getString(columnIndex);
}
}
第二步,在 mybatis-config.xml文件中注册:
<typeHandlers>
<typeHandler handler="com.gupaoedu.type.MyTypeHandler">typeHandler>
typeHandlers>
第三步,在我们需要使用的字段上指定,比如:
插入值的时候,从 Java类型到JDBC类型,在字段属性中指定typehandler:
<insert id="insertBlog" parameterType="blog">
insert into blog
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="bid != null">
bid,
if>
<if test="name != null">
name,
if>
<if test="authorId != null">
author_id,
if>
trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="bid != null">
#{bid,jdbcType=INTEGER},
if>
<if test="name != null">
#{name,jdbcType=VARCHAR},
if>
<if test="authorId != null">
#{authorId,jdbcType=INTEGER},
if>
trim>
insert>
返回值的时候,从 JDBC类型到Java类型,在 resultMap的列上指定typehandler:
<result column="name" property="name" jdbcType="VARCHAR" typeHandler="com.gupaoedu.type.MyTypeHandler"/>
4.6.object Factory
当我们把数据库返回的结果集转换为实体类的时候,需要创建对象的实例,由于我们不知道需要处理的类型是什么,有哪些属性,所以不能用new的方式去创建。只能通过反射来创建。
在 MyBatis里面,它提供了一个工厂类的接口,叫做ObjectFactory,专门用来创建对象的实例(MyBatis封装之后,简化了对象的创建),里面定义了 4 个方法。
| 方法 | 作用 |
|---|---|
| void setProperties (Properties properties); | 设置参数时调用 |
| 创建对象(调用无参构造函数) | |
|
创建对象(调用带参数构造函数) |
|
判断是否集合 |
ObjectFactory有一个默认的实现类DefaultobjectFactoryo 创建对象的方法最终 都调用了 instantiateClass(),这里面能看到反射的代码。
默认情况下,所有的对象都是由DefaultObjectFactory创建。
如果想要修改对象工厂在初始化实体类的时候的行为,就可以通过创建自己的对象
工厂,继承DefaultObjectFactory来实现(不再需要实现0 bjectFactory接 口 )。
1、 什么时候调用了 objectFactory.create?
创建DefaultResultSetHandler的时候,和创建对象的时候。
2、 创建对象后,已有的属性为什么被覆盖了?
在 DefaultResultSetHandler 类的 395 行 getRowValueQ方法里面里面调用了 applyPropertyMappings()
3、 返回结果的时候,ObjectFactory和 TypeHandler哪个先工作?
肯定是先创建对象,所以先是Object Factory,再是TypeHandler。
PS: step out可以看到一步步调用的层级
4.7.plugins
插件是MyBatis的一个很强大的机制。跟很多其他的框架一样,MyBatis预留了插 件的接口,让 MyBatis更容易扩展。
SqISession是对外提供的接口。而 SqISession增删改查的方法都是由Executor完
成 的 (点开DefualtSqISession源码的相关方法)。
Executor是真正的执行器的角色,也是实际的SQL逻辑执行的开始。
而 MyBatis中又把SQL的执行,按照过程,细分成了三个对象:ParameterHandler 处理参数,StatementHandler执行 SQL, StatementHandler处理结果集。
4.8.environments、environment
environments标签用来管理数据库的环境,比如我彳门可以有开发环境、测试环境、 生产环境的数据库。可以在不同的环境中使用不同的数据库地址或者类型。
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
dataSource>
environment>
environments>
一 个 environment标签就是一个数据源,代表一个数据库。这里面有两个关键的标 签,一个是事务管理器,一个是数据源。
4.9.transactionManager
如果配置的是JDBC,则会使用Connection对象的 commit、rollback、close()
管理事务。
如果配置成MANAGED,会把事务交给容器来管理,比 如 JBOSS, Weblogic。因
为我们跑的是本地程序,如果配置成MANAGE不会有任何事务。
如 果 是 Spring + MyBatis , 则 没 有 必 要 配 置 , 因 为 我 们 会 直 接 在
applicationContext.xml里面配置数据源和事务,覆 盖 MyBatis的配置。
4.10.dataSource
数据源,顾名思义,就是数据的来源,一个数据源就对应一个数据库。在 Java里面, 它是对数据库连接的一个抽象。
一般的数据源都会包括连接池管理的功能,所以很多时候也把DataSource直接称为连接池,准确的说法应该是:带连接池功能的数据源。
4.11.为什么要用连接池?
如果没有连接池,那么每一个用户、每_次会话连接数据库都需要直接创建和释放
连接,这个过程是会消耗的一定的时间的,并且会消耗应用和服务器的性能。
如果采用连接池技术,在应用程序里面关闭连接的时候,物理连接没有被真正关闭
掉,只是回到了连接池里面。
从这个角度来考虑,一般的连接池都会有初始连接数、最大连接数、回收时间等等
这些参数,提供提前创建/资源重用/数量控制/超时管理等等这些功能。
4.12.mappers
我们有四种指定Mapper文件的方式:
1、 使用相对于类路径的资源 引 用 (resource)
<mappers>
<mapper resource="BlogMapper.xml">
mappers>
2、 使用完全限定资源定位符(绝对路径) (URL)
<mappers>
<mapper resource="file:///app/sale/mappers/BlogMapper.xml">
mappers>
3、 使用映射器接口实现类的完全限定类名
<mappers>
<mapper class="com.gupaoedu.mapper.BlogMapper"/>
mappers>
4、 将包内的映射器接口实现全部注册为映射器(最常用)
<mappers>
<mapper class="com.gupaoedu.mapper">
mappers>
4.13.settings
4.14.Mapper.xml映射配置文件
映射器里面最主要的是配置了 SQL语句,也解决了我们的参数映射和结果集映射的问题。一共有8个标签:
-
-给定命名空间的缓存配置(是否开启二级缓存)。 -
- 其他命名空间缓存配置的引用。缓存相关两个标签我们在讲解缓存
的时候会详细讲到。 -
-是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。 -
- 可被其他语句引用的可重用语句块。
增删改查标签:
-
- 映射插入语句 -
- 映射更新语句 -
- 映射删除语句
4.15.总结
5.MyBatis最佳实践
5.1.动态SQL
MyBaits的动态SQL就帮助我们解决了这个问题,它是基于OGNL表达式的。
动态标签有哪些?
按照官网的分类,MyBatis的动态标签主要有四类:if, choose (when, otherwise), trim (where, set), foreach
-
if—— 需要判断的时候,条件写在test中:
-
choose (when, otherwise)-----需要选择一个条件的时候:
-
trim (where, set)---- 需要去掉where、and、逗号之类的符号的时候:
-
trim用来指定或者去掉前缀或者后缀:
-
foreach---- 需要遍历集合的时候:
动态SQL主要是用来解决SQL语句生成的问题。
5.2.批量操作
在 MyBatis里面是支持批量的操作的,包括批量的插入、更新、删除。我们可以直 接传入一个List、Set、Map或者数组,配合动态SQL的标签,MyBatis会自动帮我们 生成语法正确的SQL语句。
5.3.批量插入
在 Mapper文件里面,我们使用foreach标签拼接values部分的语句:
可以看到,动态SQL批量插入效率要比循环发送SQL执行要高得多。最关键的地方
就在于减少了跟数据库交互的次数,并且避免了开启和结束事务的时间消耗。
5.4.批量更新
批量更新的语法是这样的,通过case when,来匹配id相关的字段值。
所以在Mapper文件里面最关键的就是case when和 where的配置。
5.5.Batch Executor
当然MyBatis的动态标签的批量操作也是存在一定的缺点的,比如数据量特别大的 时候,拼接出来的SQL语句过大。
在我们的全局配置文件中,可以配置默认的Executor的类型(默认是SIMPLE)。
其中有一种 Batch Executor。
<setting name="defaultExecutorType" value="BATCH" />
也可以在创建会话的时候指定执行器类型:
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
思考:三种类型的区别? (通过doUpdate方法对比)
-
SimpleExecutor:每执行一次 update 或 select,就开启一个 Statement 对象, 用完立刻关闭Statement对象。
-
ReuseExecutor:执行 update 或 select,以 sql 作为 key 查找 Statement 对象,
存在就使用,不存在就创建,用完后,不关闭Statement对象 而是放置于Map内, 供下一次使用。简言之,就是重复使用Statement对象。 -
BatchExecutor:执行 update (没有 select, JDBC 批处理不支持 select),将
所有sql都添加到批处理中(addBatch()), 等待统一执行(executeBatch()), 它缓
存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执 行 executeBatchQ批处理。与 JDBC批处理相同。
executeUpdate()是一个语句访问一次数据库,executeBatch。是一批语句访问一次
数据库 (具体一批发送多少条SQL跟服务端的max_allowed_packet有关)。
BatchExecutor 底层是对 JDBC ps.addBatch()和 ps. executeBatch的封装。
5.6.嵌套(关联)查询/ N+1 / 延迟加载
我们在查询业务数据的时候经常会遇到关联查询的情况,比如查询员工就会关联部
门 (一对一), 查询学生成绩就会关联课程(一对一),查询订单就会关联商品(一对
多 )。
映射结果有两个标签,一个是
<resultType>是select标签的一个属性,适用于返回JDK类型(比如Integer. String
等等)和实体类。这种情况下结果集的列和实体类的属性可以直接映射。如果返回的字
段无法直接映射,就要用<resultMap>来建立映射关系。
对于关联查询的这种情况,通常不能用<resultType>来映射。用<resultMap >映射,
要么就是修改dto (Data Transfer Object), 在里面增加字段,这个会导致增加很多无
关的字段。要么就是引用用关联的对象,比如Blog里面包含了一个Author对象(多对一), 这种情况下就要用到关联查询(association,或者嵌套查询),MyBatis可以帮我们自 动做结果的映射。
association 和 collection 的区别:
association是用于一对一和多对一,而 collection是用于一对多的关系。
一对一的关联查询有两种配置方式:
1、嵌套结果:
单元测试类:com.gupaoedu.MyBatisTest#testSelectBlogWithAuthorResult
<resultMap id="BlogWithAuthorResultMap" type="com.gupaoedu.domain.associate.BlogAndAuthor">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<association property="author" javaType="com.gupaoedu.domain.Author">
<id column="author_id" property="authorId"/>
<result column="author_name" property="authorName"/>
association>
resultMap>
2、嵌套查询:
单元测试类:com.gupaoedu.MyBatisTest#testSelectBlogWithAuthorQuery
<resultMap id="BlogWithAuthorQueryMap" type="com.gupaoedu.domain.associate.BlogAndAuthor">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<association property="author" javaType="com.gupaoedu.domain.Author"
column="author_id" select="selectAuthor"/>
resultMap>
<select id="selectAuthor" parameterType="int" resultType="com.gupaoedu.domain.Author">
select author_id authorId, author_name authorName
from author where author_id = #{authorId}
select>
我们只执行了一次查询Blog信息的SQL (所谓的1), 如果返回了 N条记录(比 如 10条 Blog), 因为一个Blog就有至少一个Author,就会再发送N条到数据库查询 Author信 息 (所谓的N), 这个就是我们所说的N + 1的问题。这样会白白地浪费我们 的应用和数据库的性能。
如果我们用了嵌套查询的方式,怎么解决这个问题?能不能等到使用Author信息的 时候再去查询?这个就是我们所说的延迟加载,或者叫懒加载。
在 MyBatis里面可以通过开启延迟加载的开关来解决这个问题。
在 settings标签里面可以配置:
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="true"/>
<setting name="proxyFactory" value="CGLIB" />
lazyLoadingEnabled决定了是否延迟加载(默认false)
aggressiveLazyLoading决定了是不是对象的所有方法都会触发查询。
5.7.翻页
在写存储过程的年代,翻页也是一件很难调试的事情,我们要实现数据不多不少准
确地返回,需要大量的调试和修改。但是如果自己手写过分页,就能清楚分页的原理。
逻辑翻页与物理翻页
在我们查询数据库的操作中,有两种翻页方式,一种是逻辑翻页(假分页),一种
是物理翻页(真分页)。逻辑翻页的原理是把所有数据查出来,在内存中删选数据。 物
理翻页是真正的翻页,比如MySQL使用limit语句,Oracle使用rownum语句,SQL Server使用top语句。
5.8.逻辑翻页
MyBatis里面有一个逻辑分页对象RowBounds,里面主要有两个属性,offset和
limit (从第几条开始,查询多少条)
我们可以在Mapper接口的方法上加上这个参数,不需要修改xml里面的SQL语句。
如果数据量大的话,这种翻页方式效率会很低(跟查询到内存中再使用
subList(start/end)没什么区别)。所以我们要用到物理翻页。
5.9.物理翻页
物理翻页是真正的翻页,它是通过数据库支持的语句来翻页。
第一种简单的办法就是传入参数(或者包装一个page对象),在 SQL语句中翻页。
第一个问题是我们要在Java业务代码里面去计算起止序号;第二个问题是:每个需 要翻页的Statement都要编写limit语句,会造成Mapper映射器里面很多代码冗余。
那我们就需要一种通用的方式,不需要去修改配置的任何一条SQL语句,我们只要
传入当前是第几页,每页多少条就可以了,自动计算出来起止序号。
我们最常用的做法就是使用翻页的插件,比如PageHelper
PageHelper是通过MyBatis的拦截器实现的,插件的具体原理我们后面的课再分 析。简单地来说,它会根据PageHelper的参数,改写我们的SQL语句。比如MySQL
会生成limit语句,Oracle会生成rownum语句,SQL Server会生成top语句。
5.10.MBG 与 Example
我们在项目中使用MyBaits的时候,针对需要操作的一张表,需要创建实体类、 Mapper映射器、Mapper接口,里面又有很多的字段和方法的配置,这部分的工作是 非常繁琐的。而大部分时候我们对于表的基本操作是相同的,比如根据主键查询、根据
Map查询、单条插入、批量插入、根据主键删除等等等等。当我们的表很多的时候,意 味着有大量的重复工作。
所以有没有一种办法,可以根据我们的表,自动生成实体类、Mapper映射器、 Mapper接口,里面包含了我们需要用到的这些基本方法和SQL呢?
MyBatis也提供了一个代码生成器,叫做MyBatis Generator,简称MBG (它是
MyBatis的一个插件)。我们只需要修改一个配置文件,使用相关的jar包命令或者Java 代码就可以帮助我们生成实体类、映射器和接口文件。
MBG的配9 置文件里面有一个Example的开关,这个东西用来构造复杂的筛选条件 的,换句话说就是根据我们的代码去生成where条件。
原理:在实体类中包含了两个有继承关系的Criteria,用其中自动生成的方法来构建 查询条件。把这个包含了 Criteria的实体类作为参数传到查询参数中,在解析Mapper 映射器的时候会转换成SQL条件。
5.11.通用Mapper
问题:当我们的表字段发生变化的时候,我们需要修改实体类和Mapper文件定义 的字段和方法。如果是增量维护,那么一个个文件去修改。如果是全量替换,我们还要
去对比用MBG生成的文件。字段变动一次就要修改一次,维护起来非常麻烦。
解决这个问题,我们有两种思路。
第 一 个 , 因 为 MyBatis的 Mapper是 支 持 继 承 的 ( 见 :
https://github.com/mybatis/mybatis-3/issues/35 ) 。 所 以 我 们 可 以 把 我 们 的
Mapper.xml和 Mapper接口都分成两个文件。一个是MBG生成的,这部分是固定不变 的。然后创建DAO类继承生成的接口,变化的部分就在DAO里面维护。
所以以后只要修改Ext的文件就可以了。这么做有一个缺点,就是文件会增多。
思考:既然针对每张表生成的基本方法都是一样的,也就是公共的方法部分代码都
是一样的,我们能不能把这部分合并成一个文件,让它支持泛型呢?
编写一个支持泛型的通用接口,比如叫GPBaseMapper
自 定 义 的 Mapper接 口 继 承 该 通 用 接 口 , 例 如 BlogMapper extends
GPBaseMapper
我们能想到的解决方案,早就有人做了这个事了,这个东西就叫做通用Mapper。
https://github.com/abel533/Mapper/wiki
用途:主要解决单表的增删改查问题,并不适用于多表关联查询的场景。
除了配置文件变动的问题之外,通用Mapper还可以解决:
1、 每个Mapper接口中大量的重复方法的定义; 2、 屏蔽数据库的差异;
3、 提供批量操作的方法;
4、 实现分页。
使用方式:在 Spring中使用时,引入jar包,替换applicationContext.xml中的 sqISessionFactory 和 configure。
<bean class="tk.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.gupaoedu.crud.dao">
bean>
5.12.MyBatis-Plus
MyBatis-Plus是原生MyBatis的一个增强工具,可以在使用原生MyBatis的所有
功能的基础上,使用p山s特有的功能。
MyBatis-Plus的核心功能:
通 用 C R U D : 定义好Mapper接口后,只需要继承BaseMapper
条件构造器:通过EntityWrapper
代码生成器:支持一系列的策略配 置与全局配置,比 MyBatis的代码生成更好
用。
另外MyBatis-Plus也有分页的功能。
6.MyBatis常见问题
6.1.用注解还是用xml配置?
常用注解:@lnsert、@Select、 @Update、 @Delete、@Param、 @Results、 @Result
在 MyBatis的工程中,我们有两种配置SQL的方式。一种是在Mapper.xml中集中 管理,一种是在Mapper接口上,用注解方式您配置SQL。很多同学在工作中可能两种方 式都用过。那到底什么时候用XML的方式,什么时候用注解的方式呢?
注解的缺点是SQL无法集中管理,复杂的SQL很难配置。所以建议在业务复杂的项
目中只使用XML配置的形式,业务简单的项目中可以使用注解和XML混用的形式。
6.2.Mapper 接口无法注入或 Invalid bound statement (not found)
我们在使用MyBatis的时候可能会遇到Mapper接口无法注入,或 者 mapper statement id跟 Mapper接口方法无法绑定的情况。基于绑定的要求或者说规范,我们 可以从这些地方去检查一下:
1、扫描配置,xml文件和Mapper接口有没有被扫描到 2、namespace的值是否和接口全类名一致 3、检查对应的sql语句ID是否存在
6.3.怎么获取插入的最新自动生成的ID
insert成功之后,mybatis会将插入的值自动绑定到插入的对象的Id属性中,我们 用 get Id就能取到最新的ID。
6.4.什么时候用#{},什么时候用${}?
在 Mapper.xml里面配置传入参数,有两种写法:#{)、${}。作为OGNL表达式, 都可以实现参数的替换。这两种方式的区别在哪里?什么时候应该用哪一种?
要搞清楚这个问题,我们要先来说一下PrepareStatement和 Statement的区别。
1、 两个都是接口,PrepareStatement是继承自Statement的;
2、 Statement处理静态SQL, PreparedStatement主要用于执行带参数的语句;
3、 PreparedStatement的 addBatch。方法一次性发送多个查询给数据库;
4、 PS相似SQL只编译一次(对语句进行了缓存,相当于一个函数),比如语句相
同参数不同,可以减少编译次数;
5、PS可以防止SQL注入。
MyBatis任意语句的默认值:PREPARED
这两个符号的解析方式是不一样的:
#会解析为Prepared Statement的参数标记符,参数部分用?代替。传入的参数会 经过类型检查和安全检查。
$只会做字符串替换
#和$的区别:
1、 是否能防止SQL注入:$方式不会对符号转义,不能防止SQL注入
2、 性能:$方式没有预编译,不会缓存
结论:
1、 能用#的地方都用#
2、 常量的替换,比如排序条件中的字段名称,不用加单引号,可以使用$
6.5.XML中怎么使用特殊符号,比如小于&
1、 转义 < < (大于可以直接写)
2、 使用—— 当 XML遇到这种格式就会把口里面的内容原样输出,不
进行解析
6.6.如何实现模糊查询LIKE
1、字符串拼接
在Java代码中拼接% %,直接LIKE。因为没有预编译,存在SQL注入的风险,不推
荐使用。
2、CONCAT (推荐)
<select id="selectBlogListChoose" parameterType="blog" resultMap="BaseResultMap" >
select bid, name, author_id authorId from blog
<where>
<choose>
<when test="bid !=null">
bid = #{bid, jdbcType=INTEGER}
when>
<when test="name != null and name != ''">
AND name LIKE CONCAT(CONCAT('%', #{name, jdbcType=VARCHAR}),'%')
when>
<when test="authorId != null ">
AND author_id = #{authorId, jdbcType=INTEGER}
when>
<otherwise>
otherwise>
choose>
where>
select>
3、bind标签
参考资料:
1.咕泡学院·MyBatis应用分析与最佳实践·青山