hiveContext演示
使用 hiveContext 之前首先要确认以下两点:
1 使用的 Spark 是支持 hive
2 Hive 的配置文件 hive-site.xml 已经存在 conf 目录中
前者可以查看 lib 目录下是否存在以 datanucleus 开头的 3 个 JAR 来确定,后者注意是否在
hive-site.xml 里配置了 uris 来访问 Hive Metastore。
1. 启动 hive
nohup hive --service metastore > metastore.log 2>&1 &2. 在 SPARK_HOME/conf 目录下创建 hive-site.xml
<configuration>
<property>
<name>hive.metastore.urisname>
<value>thrift://hadoop1:9083value>
<description>Thrift URI for the remote metastore. Used by metastore client to
connect to remote metastore.description>
property>
configuration>3. 启动spark-shell
spark-shell --master:moon://70773. 要使用 hiveContext,需要先构建 hiveContext:
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)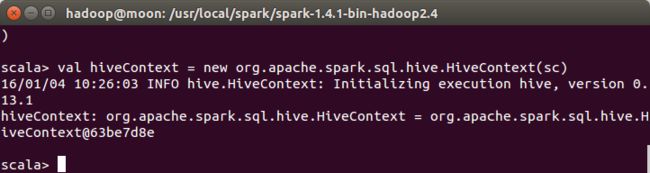
4.然后就可以对 Hive 数据进行操作了

hiveContext.sql("show tables").collect().foreach(println)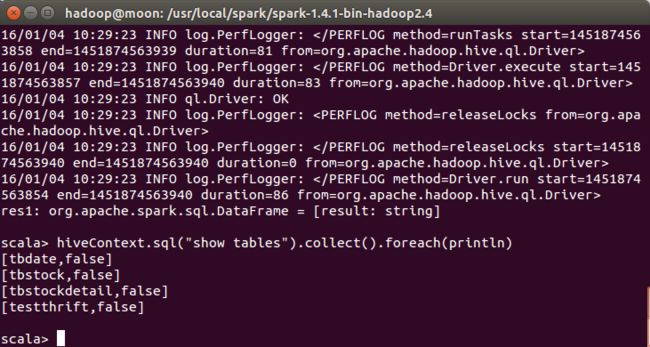
计算所有订单中每年的销售单数、销售总额
//所有订单中每年的销售单数、销售总额
//三个表连接后以 count(distinct a.ordernumber)计销售单数,sum(b.amount)计销售总额
hiveContext.sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear order by c.theyear").collect().foreach(println)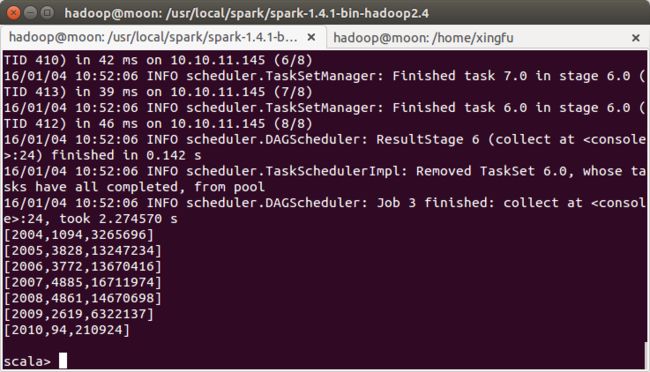
计算所有订单每年最大金额订单的销售额
第一步 实现分析
所有订单每年最大金额订单的销售额:
1、先求出每份订单的销售额以其发生时间
select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber2、以第一步的查询作为子表,和表 tbDate 连接,求出每年最大金额订单的销售额
select c.theyear,max(d.sumofamount) from tbDate c join (select
a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join
tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber )
d on c.dateid=d.dateid group by c.theyear sort by c.theyear第二步 实现 SQL 语句
scala>hiveContext.sql("select c.theyear,max(d.sumofamount) from tbDate c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d on c.dateid=d.dateid group by c.theyear sort by c.theyear").collect().foreach(println)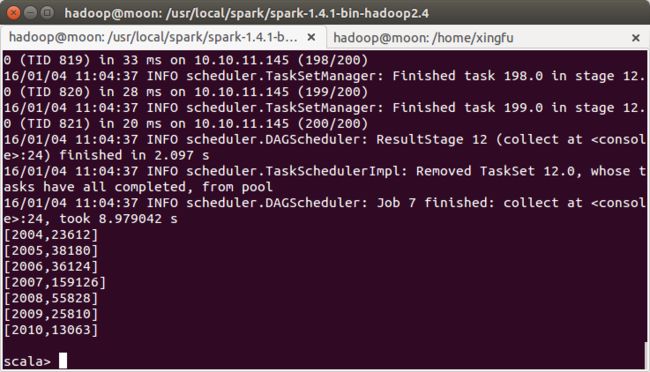
hiveContext 中混合使用演示
第一步 创建 hiveTable 从本地文件系统加载数据
//创建一个 hiveTable 并将数据加载,注意 people.txt 第二列有空格,所以 age 取 string 类型
scala>hiveContext.sql("CREATE TABLE hiveTable(name string,age string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ")scala>hiveContext.sql("LOAD DATA LOCAL INPATH '/usr/local/spark/spark-1.4.1-bin-hadoop2.4/examples/src/main/resources/people.txt' INTO TABLE hiveTable")
第二步 创建 parquet 表,从 HDFS 加载数据
//创建一个源自 parquet 文件的表 parquetTable2,然后和 hiveTable 混合使用
不知道为什么用moon会拒绝连接
scala>hiveContext.parquetFile("hdfs://localhost:9000/user/users.parquet").registerTempTable("parquetTable2")
Cache 使用
sparkSQL 的 cache 可以使用两种方法来实现:
CacheTable()方法
CACHE TABLE 命令
千万不要先使用 cache SchemaRDD,然后 registerAsTable;使用 RDD 的 cache()将使用原
生态的 cache,而不是针对 SQL 优化后的内存列存储。
第一步 对 rddTable 表进行缓存
//cache 使用
scala>val sqlContext=new org.apache.spark.sql.SQLContext(sc)
scala>import sqlContext.createSchemaRDD
scala>case class Person(name:String,age:Int)
scala>val
rddpeople=sc.textFile("hdfs://moon:9000/user/hadoop/people.txt").map(_.split(",")).map(p
=>Person(p(0),p(1).trim.toInt))
scala>rddpeople.registerTempTable("rddTable")
scala>sqlContext.cacheTable("rddTable")
scala>sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <=
19").map(t => "Name: " + t(0)).collect().foreach(println)第二步 对 parquetTable 表进行缓存
scala>val parquetpeople =
sqlContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet")
scala>parquetpeople.registerTempTable("parquetTable")
scala>sqlContext.sql("CACHE TABLE parquetTable")
scala>sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 13 AND age
<= 19").map(t => "Name: " + t(0)).collect().foreach(println)第三步 解除缓存
//uncache 使用
scala>sqlContext.uncacheTable("rddTable")
scala>sqlContext.sql("UNCACHE TABLE parquetTable")