使用BeautifulSoup爬取无锡美团美食店铺数据
使用BeautifulSoup爬取无锡美团美食店铺数据
简单说明
博主爬虫初学,近期在网上搜了很多爬虫学习的教程,基本上来就是各种函数,看的晕头转向,于是自己动手写了一个脚本,记录一下初学者的整个爬虫过程,尽量详细。
以下是爬虫前的说明:
- 爬取的是无锡美团美食数据,前50页,每页15个数据;
- 爬取的数据有店铺名,店铺ID,店铺评分,地址,评论数和平均价格;
- 用到的包有requests、bs4中的BeautifulSoup、pandas和time;
- 我个人用的是Chrome浏览器及Python3.7,编译器是Spyder。
感谢博主poptox的文章,本博客基本上是在该博客的基础上完成的,只是完善了相关代码说明,并且保存文本的方式进行了变化,侵删。
另外,初学难免各种理解不到位和错误,欢迎拍砖。
headers请求头的构造
有一些简单的网站,无需登录即可访问,但是对于一些互联网大厂,都有较好的反爬机制,这样就需要使用User-Agent、cookie、host等实现模拟登录,美团只需要User-Agent。
在爬虫的最前面,需要写一个headers字典,把上面的这些信息写进去,由于每个人用的浏览器不一样,每个人的headers也不一样,我的是:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
headers的获取方式:
- 打开网页无锡美团美食首页,单击右键点击“检查”(Chrome浏览器的快捷键是Ctrl+Shift+I);
- 在跳出的界面中点击network,然后刷新网页,点击左侧name第一个值,请求头在对应的右侧,看图片;
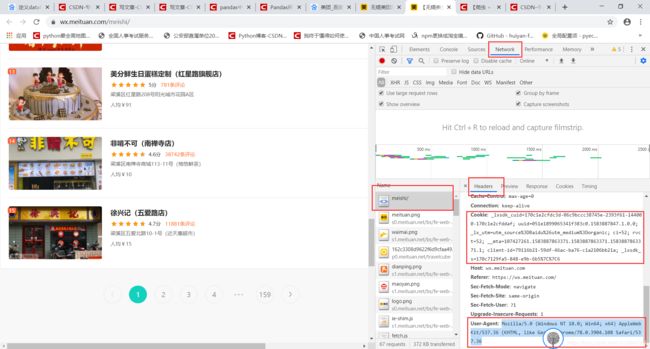
- 把User-Agent按请求头的方式写到headers里面去。
第一段代码:
import requests
import time
import json
#import csv
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
爬虫主体
直接上代码块,接上面的代码
#results是爬虫结果最后的输出,首先创建一个空列表
results = []
#raw是无锡美团美食的首页
raw = 'https://wx.meituan.com/meishi/'
#取前50页的数据,每页里面有15个店铺数据,所以这里要用两个循环
for index in range(50):
if index == 0:
continue
url = raw + 'pn' + str(index) + '/'
#用requests获取网页内容,这里就用到了请求头模拟登录
page = requests.get(url = url,headers = headers)
#用time隔2s访问一次,避免被美团识别爬虫
time.sleep(2)
#下面这两行主要是看网页的状态,状态码不等于200的话,网页不正常
print(index)
print(page.status_code)
if(page.status_code != 200):
print('error')
continue
#下面是BeautifulSoup对网页文本类容的解析
#选一个解析器,这里用lxml
soup = BeautifulSoup(page.text,'lxml')
#查找所有的‘script’
soup = soup.find_all('script')
text = soup[14].get_text().strip()
text = text[19:-1]
result = json.loads(text)
result = result['poiLists']
result = result['poiInfos']
rows = []
for i in result:
rows.append([i['title'],str(i['poiId']),str(i['avgScore']),i['address'],str(i['allCommentNum']),str(i['avgPrice'])])
results = results + rows
这里我要解释一下这几行代码的意思:
soup = soup.find_all('script')
text = soup[14].get_text().strip()
text = text[19:-1]
text = soup[14].get_text().strip()这里的14定位到的内容是这样的:

这里需要有一定的js基础,我个人也不太熟练,我们需要提取的信息就是从这里开始的。
text = text[19:-1]看上面的图,是为去掉window._appState = ,获取json数据
后面就是常规的json数据处理了
数据导出
博主poptox用的是写入csv的形式,个人更倾向使用to_csv或者to_excel,结果results是一个嵌套的列表,可以先用pandas转一下DataFrame格式,再to_excel
output = pd.DataFrame(results,columns = ['店名','店铺ID','评分','地址','评论数','平均价格'])
output.to_excel('无锡美团店铺爬取.xls')
结果如下:

完整代码
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 11 08:52:37 2020
@author: HG
"""
import requests
import time
import json
import csv
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
results = []
raw = 'https://wx.meituan.com/meishi/'
for index in range(50):
if index == 0:
continue
url = raw + 'pn' + str(index) + '/'
page = requests.get(url = url,headers = headers)
time.sleep(2)
print(index)
print(page.status_code)
if(page.status_code != 200):
print('error')
continue
soup = BeautifulSoup(page.text,'lxml')
soup = soup.find_all('script')
text = soup[14].get_text().strip()
text = text[19:-1]
result = json.loads(text)
result = result['poiLists']
result = result['poiInfos']
rows = []
for i in result:
rows.append([i['title'],str(i['poiId']),str(i['avgScore']),i['address'],str(i['allCommentNum']),str(i['avgPrice'])])
results = results + rows
output = pd.DataFrame(results,columns = ['店名','店铺ID','评分','地址','评论数','平均价格'])
output.to_excel('无锡美团店铺爬取.xls')
5月27日更新
感谢博主D_dalei提出的问题,之前的代码已经不能使用,text = soup[14].get_text().strip()解析出来的数据已经是空值了,将下面两行代码:
text = soup[14].get_text().strip()
text = text[19:-1]
替换为:
text = str(soup[14]).replace('', '')
即可正常运行。
由于美团网页代码可能会随时更新,以及各个包的升级,代码可能会出现无法运行的情况,博主有空时会持续跟进,也欢迎及时指出问题。
完