高级数据库三:浅谈数据库事务(transaction)
事务的定义
事务(txn)是一系列在共享数据库上执行的行为,以达到更高层次更复杂逻辑的功能。事务是DBMS中最基础的单位,事务不可分割。
ACID
ACID,是指在可靠数据库管理系统(DBMS)中,事务(transaction)所应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
原子性
原子性是指事务是一个不可再分割的工作单位,事务中的操作要么都发生,要么都不发生。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
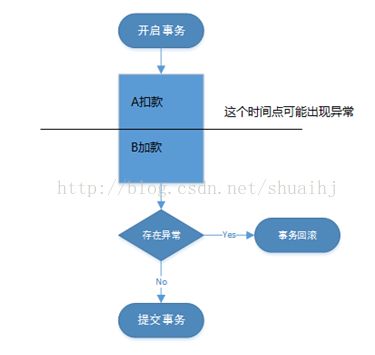
假设A要给B转钱,在事务中的扣款和加款两条语句,要么都执行,要么就都不执行。否则如果只执行了扣款语句,就提交了,此时突然断电,A账号已经发生了扣款,B账号却没收到加款,在生活中就会引起纠纷。
一致性
一致性是指事务使得系统从一个一致的状态转换到另一个一致状态。这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。
对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNT表中A和B的存款总额始终为2000元。如果一个人扣100元,一个人得50元,就破坏了一致性。
事务的一致性决定了一个系统设计和实现的复杂度。事务可以不同程度的一致性:
- 强一致性:读操作可以立即读到提交的更新操作。
- 弱一致性:提交的更新操作,不一定立即会被读操作读到,此种情况会存在一个不一致窗口,指的是读操作可以读到最新值的一段时间。
- 最终一致性:是弱一致性的特例。事务更新一份数据,最终一致性保证在没有其他事务更新同样的值的话,最终所有的事务都会读到之前事务更新的最新值。如果没有错误发生,不一致窗口的大小依赖于:通信延迟,系统负载等。
- 其他一致性变体还有:
- 单调一致性:如果一个进程已经读到一个值,那么后续不会读到更早的值。
- 会话一致性:保证客户端和服务器交互的会话过程中,读操作可以读到更新操作后的最新值。
隔离性
多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。
这指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。
并行时可能出现的问题:
- 脏读:事务A修改了一个数据,但未提交,事务B读到了事务A未提交的更新结果,如果事务A提交失败,事务B读到的就是脏数据。
- 不可重复读:在同一个事务中,对于同一份数据读取到的结果不一致。比如,事务B在事务A提交前读到的结果,和提交后读到的结果可能不同。
- 幻读:在同一个事务中,同一个查询多次返回的结果不一致。事务A新增了一条记录,事务B在事务A提交前后各执行了一次查询操作,发现后一次比前一次多了一条记录。
不同的隔离级别:
- Read Uncommitted:最低的隔离级别,什么都不需要做,一个事务可以读到另一个事务未提交的结果。所有的并发事务问题都会发生。
- Read Committed:只有在事务提交后,其更新结果才会被其他事务看见。可以解决脏读问题。
- Repeated Read:在一个事务中,对于同一份数据的读取结果总是相同的,无论是否有其他事务对这份数据进行操作,以及这个事务是否提交。可以解决脏读、不可重复读。
- Serialization:事务串行化执行,隔离级别最高,牺牲了系统的并发性。可以解决并发事务的所有问题。
| 隔离级别 | 脏读 | 丢失更新 | 不可重复读 | 幻读 | 并发模型 | 更新冲突检测 |
|---|---|---|---|---|---|---|
| 未提交读:Read Uncommited | √ | √ | √ | √ | 悲观 | × |
| 已提交读:Read commited | × | √ | √ | √ | 悲观 | × |
| 可重复读:Repeatable Read | × | × | × | √ | 悲观 | × |
| 可串行读:Serializable | × | × | × | × | 悲观 | × |
持久性
持久性,意味着在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
即使出现了任何事故比如断电等,事务一旦提交,则持久化保存在数据库中。
行为分类
- 不受保护的行为(unprotected actions):
- 不需要进行undone/redone
- 除了一致性,没有其他的ACID特性,他们的作用不可以依靠
- 例如,在事务期间对临时文件的操作
- 受保护的行为(protected actions):
- 可以也必须进行undone/redone
- 在结束之前不会显示出结果,具有完全的ACID特性
- 例如,数据库操作
- 真实的行为(real action):
- 不能被undone的操作
- 这些操作直接作用于物理世界,非常难或者几乎不可能进行撤销
- ATM机取钱
事务模式
平面型事务(FLAT TRANSACTIONS)
计算的是本地的变量,不会被DBMS看到,所以不会在之后过多讨论;
使用调用或语句级别的接口访问DBMS,一般开始于Begin,接着是一系列操作,最后以COMMIT或者ROLLBACK结束。

特点
- 无内部结构
- 只能面向单一的DBMS,在同一时间只能运行一个事务
- 只适用于简单的应用
一旦回滚,则将整个事务的所有操作进行回滚,所有在没有COMMIT之前的操作全部丢失
改进
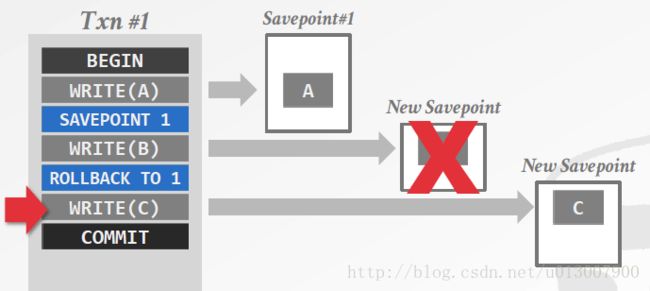
存档点(savepoint)
当事务检测到数据库需要回滚它之前做的部分操作的时候,事务可以直接自己取消自己之前的操作,也可以使用ROLLBACK机制去undo这些操作。
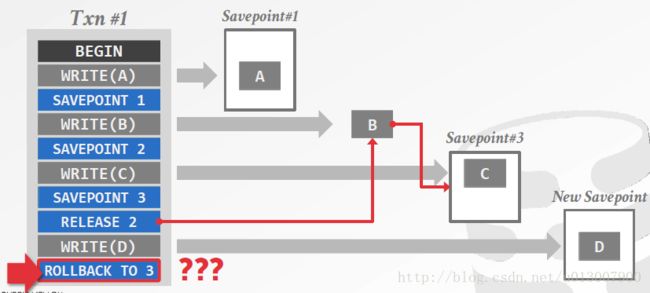
当我们把savepoint2给释放了,操作做出的改变还在,但是我们已经不能够通过savepoint回到那个位置了;而且savepoint3依赖于savepoint2,在释放后者的同时,也会把前者给释放了,因此我们也无法回到savepoint3。
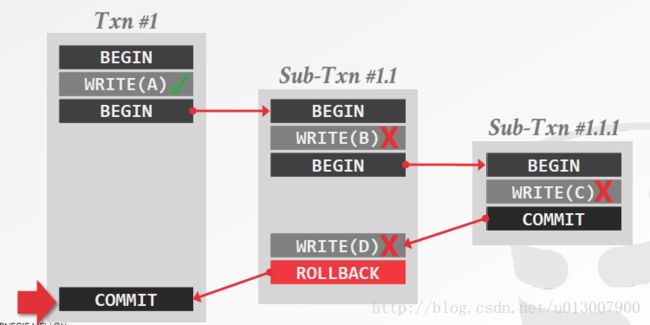
嵌套事务(NESTED TRANSACTIONS)
savepoint将事务变成一系列的每一个都可以单独回滚的行为。
嵌套事务是一套有层次的操作,子事务的结果要依赖于它父亲事务的操作。
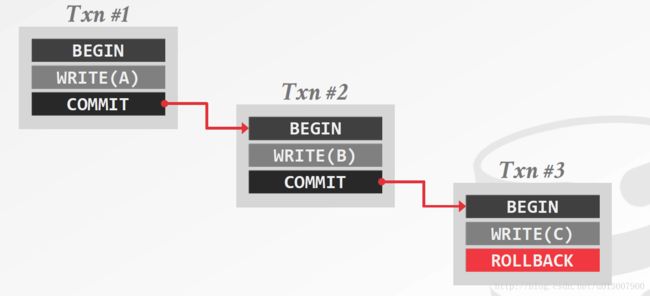
链式事务(Chained Txns)
多个事务顺序执行,一个事务COMMIT之后,另一个事务马上BEGIN,没有事务可以两个事务之间对数据进行修改。
和savepoint不同的地方在于:
- COMMIT允许DBMS释放所有的锁
- 后面的子事务不能回滚到之前的子事务中去,所以该事务不具备原子性
批量更新问题
批量更新(bulk update)本身就是一个天然事务,如果一旦失败则全部回滚。
虽然链式事务模型解决了这个问题,但是它要求应用自己去解决维护数据库状态、解决失败操作这些问题。因为DBMS没有办法将整个事务回滚。
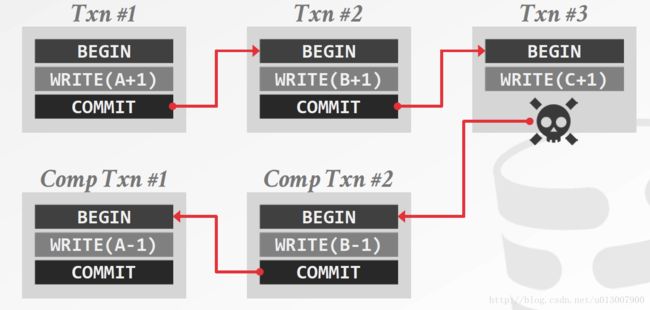
补偿事务(compensating transactions)
一种特殊类型的事务,用于将之前事务的操作结果进行消除。这种消除只能是逻辑层面的,而不是物理层面的。
SAGE事务
由两个链式事务构成,分别是是 T1,T2,…,Tn ,和对应事务的补偿事务 C1,C2,…,Cn 。
事务的提交顺序只能是两种:
- 按顺序提交 T1,…,Tn 。
- 按顺序提交 T1,…,Tj,Cj,…,\C1 。
特意解释一句,这种事务在设计到更加复杂的更新的时候就(应该)难以进行维护。同时,这种事务是不能通过DBMS实现的,而是在应用层面上进行维护的。
参考文章
谈谈数据库的ACID