Python多线程爬虫
随着信息化社会的不断发展,目前全球的网站持有量在逐步上升,各行各业的数据都以数字化的形式在互联网上传播。网络爬虫这个名词应运而生,最初用于搜索引擎,像百度,谷歌等。本文主要以python为编程语言,实现了自动化工作的爬虫,并且可以有选择性的爬取各种网页内容,以及爬取范围。最后对比了单线程和多线程两种爬虫实现,得出了并行爬虫高效率的结论。
1 爬虫的实现
该爬虫简单的实现了对2345导航网站的网址进行爬取,为了便于后边的多线程爬虫实验,我们需要获取500多个网址库。爬取深度为1
def getWeb():
headers = {\
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64)'\
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140'\
' Safari/537.36',\
'Host':'www.2345.com'
}
r = requests.get("https://www.2345.com/",headers = headers)
r.encoding = "gb2312"
#使用了bs4的网页元素审查,比较方便,也可以直接用正则表达式筛选网页元素
bs = BeautifulSoup(r.text,'lxml')
fc = bs.find_all('a')
# This function is used to write the data to a file
strs=''
for i in fc:
if(re.match("http",i.get("href")) != None): #使用正则匹配,判断URL格式
strs +="\n" + i.get("href")
return strs
2 文件操作
通过基本的文件操作函数,将爬取到的网址暂时写入文件,持久化到硬盘。这里仅仅为了方便,如果数据量庞大,建议写入数据库并建立合适的索引。
# This function is used to write the data to a file
def writeToFile(URI,data):
f = open(URI,"w+")
f.write(data)
f.close()
3 爬取的网址库如下
http://www.2345.com/product/
http://bbs.2345.cn/forumdisplay.php?fid=1&tid=1&f=2345index#quickpost
http://passport.2345.com/login.php?forward=http://www.2345.com
http://passport.2345.com/login.php?forward=http://www.2345.com
http://passport.2345.com/reg.php?forward=http://www.2345.com
http://my.ie.2345.com/onlinefav/web/
http://jifen.2345.com/?f=index
http://shouji.2345.cn/?f=index
http://passport.2345.com/?f=index
http://passport.2345.com/?f=index
http://my.ie.2345.com/onlinefav/web/
http://jifen.2345.com/?f=index
http://shouji.2345.cn/?f=index
http://passport.2345.com/login_for_index_0327.php?action=logout&forward=http://www.2345.com
http://passport.2345.com/?f=index
http://www.2345.com/help/repair.htm
http://tianqi.2345.com/indexs.htm
......
......
......4 实现多线程爬虫
这里简单实现多线程爬虫,基本框架如下:
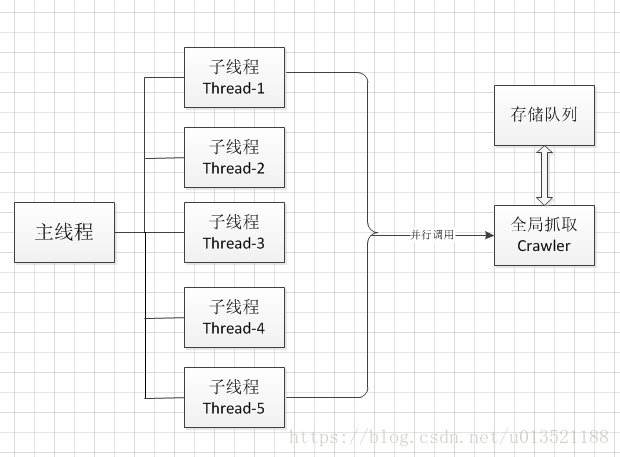
import threading
import requests
import time
import Queue
threads = []
start = time.time()
#建立队列,存储爬取网址
que = Queue.Queue(1000)
#线程类,每个子线程调用,继承Thread类并重写run函数,以便执行我们的爬虫函数
class myThread(threading.Thread):
def __init__(self,threadName,que):
threading.Thread.__init__(self)
self.threadName = threadName
self.que = que
def run(self):
print("Start--" + self.threadName)
while True:
try:
crawler(self.name,self.que)
except:
break
print("Exiting "+self.name)
#爬取的函数,爬虫的程序
def crawler(threadName,que):
url = que.get(timeout=2)
try:
r = requests.get(url,timeout=15)
print(que.qsize(),threadName,r.status_code,url)
except:
print('ERROR')
threadList = ['thread-1','thread-2','thread-3','thread-4','thread-5', \
'thread-6','thread-7']
# Filling the queue
f = open("./website1.txt",'r')
ss=''
ss = f.read()
f.close()
webList = []
webList = ss.split("\n")
for url in webList:
que.put(url)
#Create the queue
for tName in threadList:
thread = myThread(tName,que)
thread.start()
threads.append(thread)
#同步线程,避免主线程提前终止,保证整个计时工作
for t in threads:
t.join()
end = time.time()
#输出时间并结束
print("The total time is:",end-start)5 结果分析
单线程:(’The total time is:’, 123.79839992523193)
7线程:(‘The total time is:’, 59.76098895072937)
根据执行的效果,单线程耗时123.7s , 同时开7个线程为 59.7s ,可以明显看出多线程的优势。在Python中存在GIL线程锁,每次只有一个线程在运行,其效率并不高,由于在抓取网页中存在访问时间上的延时,多线程的优势会体现的特别明显。下一篇文件将在多进程上展现python爬虫的效率。