RDD、DataFrame和Dataset 怎么选择才好?
最令开发者们高兴的事莫过于有一组API,可以大大提高开发者们的工作效率,容易使用、非常直观并且富有表现力。Apache Spark广受开发者们欢迎的一个重要原因也在于它那些非常容易使用的API,可以方便地通过多种语言,如Scala、Java、Python和R等来操作大数据集。
在本文中,我将深入讲讲Apache Spark 2.2以及以上版本提供的三种API——RDD、DataFrame和Dataset,在什么情况下你该选用哪一种以及为什么,并概述它们的性能和优化点,列举那些应该使用DataFrame和Dataset而不是RDD的场景。我会更多地关注DataFrame和Dataset,因为在Apache Spark 2.0中这两种API被整合起来了。
这次整合背后的动机在于我们希望可以让使用Spark变得更简单,方法就是减少你需要掌握的概念的数量,以及提供处理结构化数据的办法。在处理结构化数据时,Spark可以像针对特定领域的语言所提供的能力一样,提供高级抽象和API。
弹性分布式数据集(Resilient Distributed Dataset,RDD)
从一开始RDD就是Spark提供的面向用户的主要API。从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层API进行并行处理。
在什么情况下使用RDD?
下面是使用RDD的场景和常见案例:
- 你希望可以对你的数据集进行最基本的转换、处理和控制;
- 你的数据是非结构化的,比如流媒体或者字符流;
- 你想通过函数式编程而不是特定领域内的表达来处理你的数据;
- 你不希望像进行列式处理一样定义一个模式,通过名字或字段来处理或访问数据属性;
- 你并不在意通过DataFrame和Dataset进行结构化和半结构化数据处理所能获得的一些优化和性能上的好处;
Apache Spark 2.0中的RDD有哪些改变?
可能你会问:RDD是不是快要降级成二等公民了?是不是快要退出历史舞台了?
答案是非常坚决的:不!
而且,接下来你还将了解到,你可以通过简单的API方法调用在DataFrame或Dataset与RDD之间进行无缝切换,事实上DataFrame和Dataset也正是基于RDD提供的。
DataFrame
与RDD相似,DataFrame也是数据的一个不可变分布式集合。但与RDD不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。设计DataFrame的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。它提供了特定领域内专用的API来处理你的分布式数据,并让更多的人可以更方便地使用Spark,而不仅限于专业的数据工程师。
在我们的Apache Spark 2.0网络研讨会以及后续的博客中,我们提到在Spark 2.0中,DataFrame和Dataset的API将融合到一起,完成跨函数库的数据处理能力的整合。在整合完成之后,开发者们就不必再去学习或者记忆那么多的概念了,可以通过一套名为Dataset的高级并且类型安全的API完成工作。
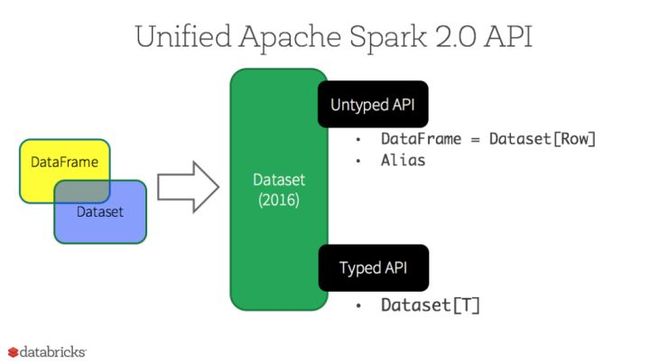
Dataset
如下面的表格所示,从Spark 2.0开始,Dataset开始具有两种不同类型的API特征:有明确类型的API和无类型的API。从概念上来说,你可以把DataFrame当作一些通用对象Dataset[Row]的集合的一个别名,而一行就是一个通用的无类型的JVM对象。与之形成对比,Dataset就是一些有明确类型定义的JVM对象的集合,通过你在Scala中定义的Case Class或者Java中的Class来指定。
有类型和无类型的API

注意:因为Python和R没有编译时类型安全,所以我们只有称之为DataFrame的无类型API。
Dataset API的优点
在Spark 2.0里,DataFrame和Dataset的统一API会为Spark开发者们带来许多方面的好处。
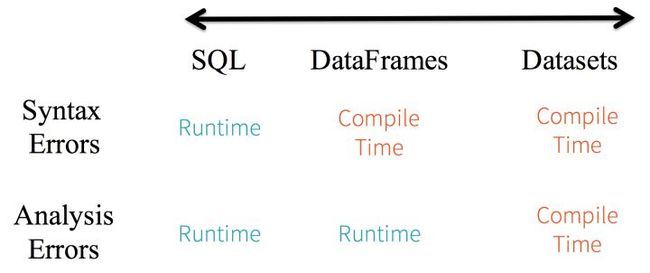
1、静态类型与运行时类型安全
从SQL的最小约束到Dataset的最严格约束,把静态类型和运行时安全想像成一个图谱。比如,如果你用的是Spark SQL的查询语句,要直到运行时你才会发现有语法错误(这样做代价很大),而如果你用的是DataFrame和Dataset,你在编译时就可以捕获错误(这样就节省了开发者的时间和整体代价)。也就是说,当你在DataFrame中调用了API之外的函数时,编译器就可以发现这个错。不过,如果你使用了一个不存在的字段名字,那就要到运行时才能发现错误了。
图谱的另一端是最严格的Dataset。因为Dataset API都是用lambda函数和JVM类型对象表示的,所有不匹配的类型参数都可以在编译时发现。而且在使用Dataset时,你的分析错误也会在编译时被发现,这样就节省了开发者的时间和代价。
所有这些最终都被解释成关于类型安全的图谱,内容就是你的Spark代码里的语法和分析错误。在图谱中,Dataset是最严格的一端,但对于开发者来说也是效率最高的。
2、关于结构化和半结构化数据的高级抽象和定制视图
把DataFrame当成Dataset[Row]的集合,就可以对你的半结构化数据有了一个结构化的定制视图。比如,假如你有个非常大量的用JSON格式表示的物联网设备事件数据集。因为JSON是半结构化的格式,那它就非常适合采用Dataset来作为强类型化的Dataset[DeviceIoTData]的集合。
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ",
"ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland",
"latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius",
"temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408,
"lcd": "red", "timestamp" :1458081226051}你可以用一个Scala Case Class来把每条JSON记录都表示为一条DeviceIoTData,一个定制化的对象。
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2:
String, cca3: String, cn: String, device_id: Long, device_name: String,
humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double,
scale:String, temp: Long, timestamp: Long)接下来,我们就可以从一个JSON文件中读入数据。
// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read
.json(“/databricks-public-datasets/data/iot/iot_devices.json”)
.as[DeviceIoTData]上面的代码其实可以细分为三步:
- Spark读入JSON,根据模式创建出一个DataFrame的集合;
- 在这时候,Spark把你的数据用“DataFrame = Dataset[Row]”进行转换,变成一种通用行对象的集合,因为这时候它还不知道具体的类型;
- 然后,Spark就可以按照类DeviceIoTData的定义,转换出“Dataset[Row] -> Dataset[DeviceIoTData]”这样特定类型的Scala JVM对象了。
许多和结构化数据打过交道的人都习惯于用列的模式查看和处理数据,或者访问对象中的某个特定属性。将Dataset作为一个有类型的Dataset[ElementType]对象的集合,你就可以非常自然地又得到编译时安全的特性,又为强类型的JVM对象获得定制的视图。而且你用上面的代码获得的强类型的Dataset[T]也可以非常容易地用高级方法展示或处理。
3、方便易用的结构化API
虽然结构化可能会限制你的Spark程序对数据的控制,但它却提供了丰富的语义,和方便易用的特定领域内的操作,后者可以被表示为高级结构。事实上,用Dataset的高级API可以完成大多数的计算。比如,它比用RDD数据行的数据字段进行agg、select、sum、avg、map、filter或groupBy等操作简单得多,只需要处理Dataset类型的DeviceIoTData对象即可。
用一套特定领域内的API来表达你的算法,比用RDD来进行关系代数运算简单得多。比如,下面的代码将用filter()和map()来创建另一个不可变Dataset。
// Use filter(), map(), groupBy() country, and compute avg()
// for temperatures and humidity. This operation results in
// another immutable Dataset. The query is simpler to read,
// and expressive
val dsAvgTmp = ds.filter(d => {d.temp > 25})
.map(d => (d.temp, d.humidity, d.cca3))
.groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)4、性能与优化
除了上述优点之外,你还要看到使用DataFrame和Dataset API带来的空间效率和性能提升。原因有如下两点:
首先,因为DataFrame和Dataset API都是基于Spark SQL引擎构建的,它使用Catalyst来生成优化后的逻辑和物理查询计划。所有R、Java、Scala或Python的DataFrame/Dataset API,所有的关系型查询的底层使用的都是相同的代码优化器,因而会获得空间和速度上的效率。尽管有类型的Dataset[T] API是对数据处理任务优化过的,无类型的Dataset[Row](别名DataFrame)却运行得更快,适合交互式分析。

其次,Spark作为一个编译器,它可以理解Dataset类型的JVM对象,它会使用编码器来把特定类型的JVM对象映射成Tungsten的内部内存表示。结果,Tungsten的编码器就可以非常高效地将JVM对象序列化或反序列化,同时生成压缩字节码,这样执行效率就非常高了。
该什么时候使用DataFrame或Dataset呢?
- 如果你需要丰富的语义、高级抽象和特定领域专用的API,那就使用DataFrame或Dataset;
- 如果你的处理需要对半结构化数据进行高级处理,如filter、map、aggregation、average、sum、SQL查询、列式访问或使用lambda函数,那就使用DataFrame或Dataset;
- 如果你想在编译时就有高度的类型安全,想要有类型的JVM对象,用上Catalyst优化,并得益于Tungsten生成的高效代码,那就使用Dataset;
- 如果你想在不同的Spark库之间使用一致和简化的API,那就使用DataFrame或Dataset;
- 如果你是R语言使用者,就用DataFrame;
- 如果你是Python语言使用者,就用DataFrame,在需要更细致的控制时就退回去使用RDD;
注意只需要简单地调用一下.rdd,就可以无缝地将DataFrame或Dataset转换成RDD。例子如下:
// select specific fields from the Dataset, apply a predicate
// using the where() method, convert to an RDD, and show first 10
// RDD rows
val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level")
.where($"c02_level" > 1300)
// convert to RDDs and take the first 10 rows
val eventsRDD = deviceEventsDS.rdd.take(10)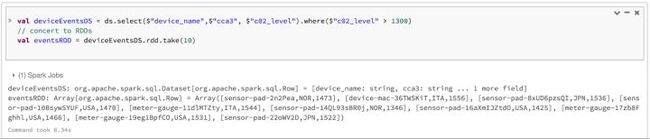
总结
总之,在什么时候该选用RDD、DataFrame或Dataset看起来好像挺明显。前者可以提供底层的功能和控制,后者支持定制的视图和结构,可以提供高级和特定领域的操作,节约空间并快速运行。
当我们回顾从早期版本的Spark中获得的经验教训时,我们问自己该如何为开发者简化Spark呢?该如何优化它,让它性能更高呢?我们决定把底层的RDD API进行高级抽象,成为DataFrame和Dataset,用它们在Catalyst优化器和Tungsten之上构建跨库的一致数据抽象。
DataFrame和Dataset,或RDD API,按你的实际需要和场景选一个来用吧,当你像大多数开发者一样对数据进行结构化或半结构化的处理时,我不会有丝毫惊讶。