【机器学习+sklearn框架】(一) 线性模型之Linear Regression
前言
一、原理
1.算法含义
2.算法特点
二、实现
1.sklearn中的线性回归
2.用Python自己实现算法
三、思考(面试常问)
参考
前言
线性回归(Linear Regression)基本上可以说是机器学习中最简单的模型了,但是实际上其地位很重要(计算简单、效果不错,在很多其他算法中也可以看到用其其作为一部分)。机器学习所针对的问题有两种:一种是回归,一种是分类。回归是解决连续数据的预测问题,而分类是解决离散数据的预测问题。线性回归是一个典型的回归问题。其实中学时期我们就接触过,叫最小二乘法。
一、原理
1.算法含义
“线性回归”试图学得一个线性模型以尽可能准确地预测实值输出标记。(《机器学习》--周志华 )
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合(自变量都是一次方)。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。(百度百科)
2.算法特点
优点:计算简单,结果易于理解。
缺点:对非线性数据拟合不好。
适用数据类型:数值型和标称型数据。
二、实现
1.sklearn中的线性回归
(1) sklearn对广义线性模型(Generalized Linear Models)的定义如下:
拟合一条直线使得损失最小,损失可以有很多种,比如平方和最小等等;

【注】y是输出,x是输入,输出是输入的一个线性组合。

【注】系数矩阵就是coef_,截距就是intercept_
(2) sklearn对广义线性模型中的线性回归算法(Linear Regression)的定义如下:
首先sklearn将线性回归称做Ordinary Least Squares ( 普通最小二乘法 ),sklearn定义 LinearRegression 类是拟合系数为 ![]() 的线性模型, 目的在于最小化样本集中观测点和线性近似的预测点之间的残差平方和。
的线性模型, 目的在于最小化样本集中观测点和线性近似的预测点之间的残差平方和。
其实就是解决如下的一个数学问题:![]()
(3)线性回归基本图形
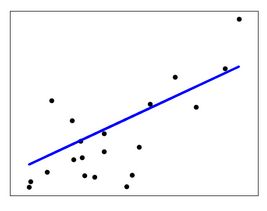
(4)sklear中LinearRegression的参数与实现
成员函数:
fit (X,y) : 以数组X和y为输入
成员变量:
coef_ : 存储线性模型的系数 w存储
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])结果如下:
reg.coef_结果如下:
![]()
(5) 特殊情况
然而,最小二乘的系数估计依赖于模型特征项的独立性。当特征项相关,并且设计矩阵X 的列近似线性相关时,设计矩阵便接近于一个奇异矩阵,此时最小二乘估计对观测点中的随机误差变得高度敏感,产生较大方差。例如,当没有试验设计的收集数据时,可能会出现这种多重共线性(multicollinearity )的情况。
【注】multicollinearity :指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
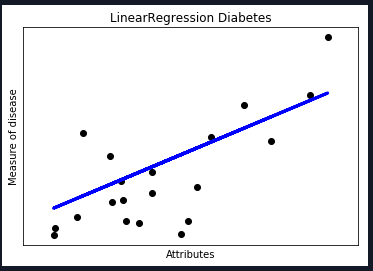
本文以sklearn自带的糖尿病数据集()为例:
Diabetes:包含442个患者的10个生理特征(年龄,性别、体重、血压)和一年以后疾病级数指标
载入数据,同时将diabetes糖尿病数据集分为测试数据和训练数据,其中测试数据为最后20行,训练数据为前422行。
#数据集获取
diabetes = datasets.load_diabetes() #载入数据
diabetes_x = diabetes.data[:, np.newaxis] #获取一个特征
#数据集划分
diabetes_x_temp = diabetes_x[:, :, 2]
diabetes_x_train = diabetes_x_temp[:-20] #训练样本
diabetes_x_test = diabetes_x_temp[-20:] #测试样本 后20行
diabetes_y_train = diabetes.target[:-20] #训练标记
diabetes_y_test = diabetes.target[-20:] #预测对比标记
print(u'划分行数:', "[总数据量]",len(diabetes_x_temp)," [训练集]", len(diabetes_x_train)," [测试集]", len(diabetes_x_test))
print(diabetes_x_test) #20行测试数据,每行仅一个特征
#回归训练及预测
clf = linear_model.LinearRegression()
clf.fit(diabetes_x_train, diabetes_y_train) #注: 训练数据集详细代码见https://download.csdn.net/download/walk_power/10716974
测试结果如下:
数据集划分
![]()
系数,残差平方和,方差

图形(散点:实际位置 ,直线:预测位置)
2.用Python自己实现算法
公式推导:
给定数据集D={(x1,y1),(x2,y2),…,(xm,ym)},一共有m个样本,其中每个样本有d个属性,即xi = (xi1,xi2,…,xid)。线性回归是试图学到一个线性模型 f(x) = w1*x1+w2*x2+…+wd*xd + b以尽可能准确的预测实值输出标记。 其中w=(w1,w2,…,wd), w和b是通过学习之后,模型得以确定。
w和b的确定是通过损失函数确定的:

用最小二乘法对w和b进行估计。把w和b吸收入向量形式,w’ = (w;b),相应的数据集D表示为一个m*(d+1)的矩阵X,其中每一行对应一个示例,该行前d个元素对应于示例的d个属性值,最后一个元素恒为1。则对于上面的公式有:
![]()
对w’求导得:

令上式为零(当X^TX为满秩矩阵或正定矩阵时可得):
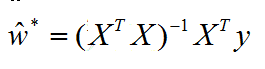
令xi’ = (xi;1)则线性回归模型为:
![]()
核心公式:![]() ,而
,而![]()
import numpy as np
X_=np.linalg.inv(X.T.dot(X)) #调用numpy里的求逆函数
theta=X.dot(X.T).dot(Y) #X.T表示转置,X.dot(Y)表示矩阵相乘具体实现:
'''
线性回归算法
'''
class LinearRegression_SelfDefined():
def __init__(self): #1.新建变量
self.w = None
def fit(self, X, y): #2.训练集的拟合
X = np.insert(X, 0, 1, axis=1) #增加一个维度
print (X.shape)
X_ = np.linalg.inv(X.T.dot(X)) #公式:求X的转置(.T)与X矩阵相乘(.dot(X)),再求其逆矩阵(np.linalg.inv())
self.w = X_.dot(X.T).dot(y) #上述公式与X的转置进行矩阵相乘,再与y进行矩阵相乘
def predict(self, X): #3.测试集的测试反馈
X = np.insert(X, 0, 1, axis=1) #增加一个维度
y_pred = X.dot(self.w) #X与self.w所表示的矩阵相乘
return y_pred详细代码见https://download.csdn.net/download/walk_power/10716982
结果如下:

三、思考(面试常问)
1.什么是线性分类模型,什么是非线性分类模型,它们各有什么有优缺点?
区分是否为线性模型,主要是看一个乘法式子中自变量x前的系数w,如果w只影响一个x(注:应该是说x只被一个w影响),那么此模型为线性模型。或者判断决策边界是否是线性的。不满足线性模型的情况即为非线性模型。只考虑二类的情形,所谓线性分类器即用一个超平面将正负样本分离开,表达式为 y=wx 。这里是强调的是平面。而非线性的分类界面没有这个限制,可以是曲面,多个超平面的组合等。
线性分类模型(LR,贝叶斯分类,单层感知机、线性回归)优缺点:算法简单和具有“学习”能力。线性分类器速度快、编程方便,但是可能拟合效果不会很好。
非线性分类模型(决策树、RF、GBDT、多层感知机)优缺点:非线性分类器编程复杂,但是效果拟合能力强
2.线性回归和逻辑回归有什么区别和联系?
①区别:线性回归用来预测(如:房价预测),逻辑回归用来分类(如:疾病诊断);线性回归是拟合函数,逻辑回归是预测函数;线性回归的参数计算方法是最小二乘法,逻辑回归的参数计算方法是梯度下降法。(附上吴恩达讲解)
②联系:逻辑回归比线性回归多了一个Sigmoid函数,使样本能映射到[0,1]之间的数值,用来做分类问题。
3.写出线性回归算法的步骤并分析其优缺点。
见上文
参考
1. 线性回归公式推导(二)
2. 回归算法——python实现线性回归
3.【Python数据挖掘课程】五.线性回归知识及预测糖尿病实例
4. 《机器学习》周志华
5. Scikit-learn API文档