The SQL layer in CockroachDB --CockroachDB 的SQL层
Last update: September 2018
This document provides an architectural overview of the SQL layer in CockroachDB. The SQL layer is responsible for providing the "SQL API" that enables access to a CockroachDB cluster by client applications.
本文档提供了CockroachDB中SQL层体系结构的概述。SQL层负责提供“SQL API”,使客户端应用程序能够访问CockroachDB集群。
Original author: knz
Table of contents:
- Prologue
- Overview
- Detailed model - Query Processing phases
- Detailed model - Statements vs. Components
- Detailed model - Components and Data Flow
- Component details:
- pgwire
- SQL front-end
- SQL middle-end
- SQL back-end
- Executor
- Auxiliaries
- Other components
Prologue 序言
This document complements the prior document "Life of a SQL query" by Andrei. Andrei's document is structured as an itinerary, where the reader follows the same path as a SQL query and its response data through the architecture of CockroachDB. This architecture document is a top-down perspective of all the components involved side-by-side, which names and describes the relationships between them. In short, Life of a SQL query answers the question "what happens and how" and this document answers the question "what are the parts involved".
该文档补充了Andrei以前的文档"Life of a SQL query"“SQL查询的一生”。Andrei的文档是按照sql的执行过程写的,读者可以了解SQL查询的执行路径以及如何通过CockroachDB返回数据。本文档的结构是一个自上而下的透视图,它包含了所有涉及到的组件,组件的命名以及它们之间的关系。简而言之,“SQL查询的一生”回答了“发生了什么以及如何发生”,本文档回答的是“所涉及的部分是什么”。
Disclaimer / How to read this document
免责声明/如何阅读本文件
tl;dr: there is an architecture, but it is not yet visible in the source code.
In most state-of-the-art software projects, there exists a relatively good correspondence between the main conceptual items of the overall architecture (and its diagrams, say) and the source code.
在大多数最先进的软件项目中,总体体系结构的主要概念项(以及它的图表)与源代码之间存在着相对较好的对应关系。
For example, if the architecture calls out a thing called e.g. "query runner", which takes as input a logical query plan (a data structure) and outputs result rows (another data structure), you'd usually expect a thing in the source code called "query runner" that looks like a class whose instances would carry the execution's internal state providing some methods that take a logical plan as input, and returning result rows as results.
例如,如果体系结构命名一个叫“query runner”的东西,它以逻辑查询计划(数据结构)作为输入,并输出结果行(另一种数据结构),您通常会期望源代码中也有一个叫做“query runner”的东西,它看起来像一个类,它的实例将携带执行的内部状态,提供一些方法:以逻辑计划作为输入,返回结果行。
In CockroachDB's source code, this way of thinking does not apply: instead, CockroachDB's architecture is an emergent property of its source code.
在CockroachDB的源代码中,这种思维方式并不适用:相反,CockroachDB架构是其源代码的新兴属性。
"Emergent" means that while it is possible to understand the architecture by reading the source code, the idea of an architecture can only emerge in the mind of the reader after an intense and powerful mental exercise of abstraction. Without this active effort, the code just looks like a plate of spaghetti until months of grit and iterative navigation and tinkering stimulates the reader's subconscious mind to run through the abstraction exercise on its own, and to slowly and incrementally reveal the architecture, while the reader's experience builds up.
“Emergent”意味着,虽然可以通过阅读源代码来理解体系结构,但只有在进行了强烈而强大的抽象之后,才能在读者的脑海中出现一个体系结构的概念。如果没有这种积极的努力,代码看起来就像一盘意大利面,直到几个月艰苦的代码迭代修补,刺激读者的潜意识思维,让读者自己完成抽象,并慢慢地、逐步地揭示体系结构,同时读者的经验积累起来。
There are multiple things that can be said about this state of affairs:
关于这种状况,有许多事情可以说:
-
this situation sounds much worse than it really is. While the code is initially difficult to map to an overarching architecture, every person who has touched the code has made their best effort at maintaining good separation of responsibilities between different components. The fact that this document is able to reconstruct a relatively sane architectural model from the source code despite the lack of explicit overarching architectural guidelines so far is a testament to the quality of said source code and the work of all past and current contributors.
这种情况听起来比实际情况要糟糕得多。虽然代码最初很难映射到总体架构,但每个接触过代码的人都尽了最大努力维护不同组件之间良好的职责分离。尽管到目前为止缺乏明确的总体架构指南,但本文档能够从源代码中重建一个相对合理的体系结构模型,这证明了所述源代码的质量以及所有过去和现在的贡献者的工作。
-
nevertheless, it exerts a high resistance against the onboarding of new team members, and it constitutes an obstacle to the formation of truly decoupled teams. Let me explain.
然而,它对团队新成员的入职产生了很大的阻力,并构成了组建真正解耦团队的障碍。让我解释一下。
While our "starter projects" ensure that new team members get quickly up to speed with our engineering process, they are rather powerless at creating any high-level understanding whatsoever of how CockroachDB's SQL layer really works. My observations so far suggest that onboarding a contributor to CockroachDB's SQL code such that they can contribute non-trivial changes to any part of the SQL layer requires four to six months of incrementally complex assignments over all of the SQL layer.
虽然我们的“入门项目”确保新团队成员能够快速掌握我们的工程流程,但他们在任何有关CockroachDB SQL层真正工作方式的高层次理解方面无能为力。 到目前为止,我的观察结果表明,即使对与CockroachDB SQL代码的贡献者,他们可以对SQL层的任何部分进行非平凡的更改,但是也需要在所有SQL层上做四到六个月的递增复杂的工作。
The reason for this is that (until this document was written) the internal components of the SQL layer were not conceptually isolated, so one had to work with all of them to truly understand their boundaries. By the time any good understanding of any single component could develop, the team member would have needed to look at and comprehend every other component. And therefore teams could not maintain strong conceptual isolation between areas of the source code, for any trainee would be working across boundaries all the time.
这样做的原因是(在编写本文档之前)SQL层的内部组件在概念上没有被隔离,因此必须与所有这些组件一起工作才能真正理解它们的边界。 要想对任何单个组件都有了良好的理解,团队成员需要查看并理解所有其他组件。因此,团队不能在源代码区域之间保持强烈的概念隔离,因为任何受训人员都会一直跨边界工作。
-
finally, this situation is changing, and will change further. As the number of more experienced engineers grows, more of us are starting to consciously realize that this situation is untenable and that we must start to actively address complexity growth and the lack of internal boundaries. Me authoring this document serves as witness to this change of winds. Moreover, some feature work (e.g. concurrent execution of SQL statements) is already motivating some good refactorings by Nathan, and more are coming on the horizon. Ideally, this entire "disclaimer" section in this architecture document would eventually disappear.
最后,这种情况正在发生变化,而且还将进一步改变。随着更多经验丰富的工程师人数增加,我们中越来越多的人开始意识到这种情况是站不住脚的,我们必须开始积极处理复杂性增长和缺乏内部边界的问题。我撰写这份文件就是这种风向变化的见证。此外,一些特性工作(例如,SQL语句的并发执行)已经激发了Nathan的一些良好的重构,还会有更多的重构。理想情况下,这个文档中的整个“免责声明”部分最终会消失。
There is probably space for a document that would outline how we wish CockroachDB's SQL architecture to look like; this is left as an exercise for a next iteration, and we will focus here on recognizing what is there without judgement.
文档可能还有空间,可以概括我们希望CockroachDB的SQL体系结构的样子;这留给下一次迭代的练习,我们将在此集中于识别其中有什么,而不做判断。
In short, the rest of this document is a model, not a specification.
简而言之,这个文档的其余部分是模型,而不是规范。
Also, several sections have a note "Whom to ask for details". This reflects the current advertised expertise of several team members, so as to serve as a possible point of entry for questions by newcomers, but does not intend to denote "ownership": so far I know, we don't practice "ownership" in this part of the code base.
此外,几个章节有一个注释“谁问细节”。这反映了一些团队成员当前所宣传的专业知识,以便作为新手提问的可能入口,但不打算表示“所有权”:到目前为止,我知道,我们在代码库的这个部分并不实践“所有权”。
Overview
概述
The flow of data in the SQL layer during query processing can be summarized as follows:
查询处理过程中,SQL层中的数据流可以概括如下:
There are overall five main component groups:
-
pgwire: the protocol translator between clients and the executor;
-
the SQL front-end, responsible for parsing, desugaring, free simplifications and semantic analysis; this comprises the two blocks "Parser" and "Expression analysis" in the overview diagram.
-
the SQL middle-end, responsible for logical planning and optimization.
-
the SQL back-end, which comprises "physical planning" and "query execution".
-
the executor, which coordinates between the previous four things, the session data, the state SQL transaction and the interactions with the state of the transaction in the KV layer.
总体上有五个主要组成部分:
- pgwire:客户端和执行器之间的协议转换器;
- SQL前端,负责解析、去噪、自由简化和语义分析;这包括概览图中的两个块“Parser”和“Expression.”。
- SQL中间端,负责逻辑计划和优化。
- SQL后端,包括“物理计划”和“查询执行”。
- executor 执行器,它协调前面四个,会话数据、SQL事务的状态以及与KV层中事务状态的交互。
Note that these components are a fictional model: for efficiency and engineering reasons, the the front-end and middle-end are grouped together in the code; meanwhile the back-end is here considered as a single component but is effectively developed and maintained as multiple separate sub-components.
请注意,这些组件是虚构的模型:出于效率和工程原因,前端和中端在代码中组合在一起; 同时,后端在这里被视为单个组件,但是作为多个单独的子组件进行开发和维护。
Besides these components on the "main" data path of a common SQL query, there are additional auxiliary components that can also participate:
除了常见SQL查询的“主”数据路径上的这些组件外,还有其他辅助组件也可以参与:
- the lease manager for access to SQL object descriptors;
- 用于访问SQL对象描述符的租约管理器;
- the schema change manager to perform schema changes asynchronously;
- 模式更改管理器以异步方式执行模式更改;
- the memory monitors for memory accounting.
- 内存监视器用于内存计量。
Although they are auxiliary to the main components above, only the memory monitor is relatively simple -- a large architectural discussion would be necessary to fully comprehend the complexity of SQL leases and schema changes.
虽然它们是对上述主要组件的辅助,但是只有内存监视器相对简单——为了全面理解SQL租约和模式更改的复杂性,需要进行大量体系结构的讨论。
The detailed model section below describes these components further and where they are located in the source code.
下面的详细模型部分进一步描述了这些组件以及它们在源代码中的位置。
Detailed model - Query processing phases详细模型-查询处理阶段
It is common for SQL engines to separate processing of a query into two phases: preparation and execution. This is especially valuable because the work of preparation can be performed just once for multiple executions.
SQL引擎通常将查询的处理分为两个阶段:准备和执行。这特别有价值,因为准备工作对于多次执行可以只执行一次。
In CockroachDB this separation exists, and the preparation phase is itself split into sub-phases: logical preparation and physical preparation.
在蟑螂DB中,存在这种分离,并且准备阶段本身被分成子阶段:逻辑准备和物理准备。
This can be represented as follows:
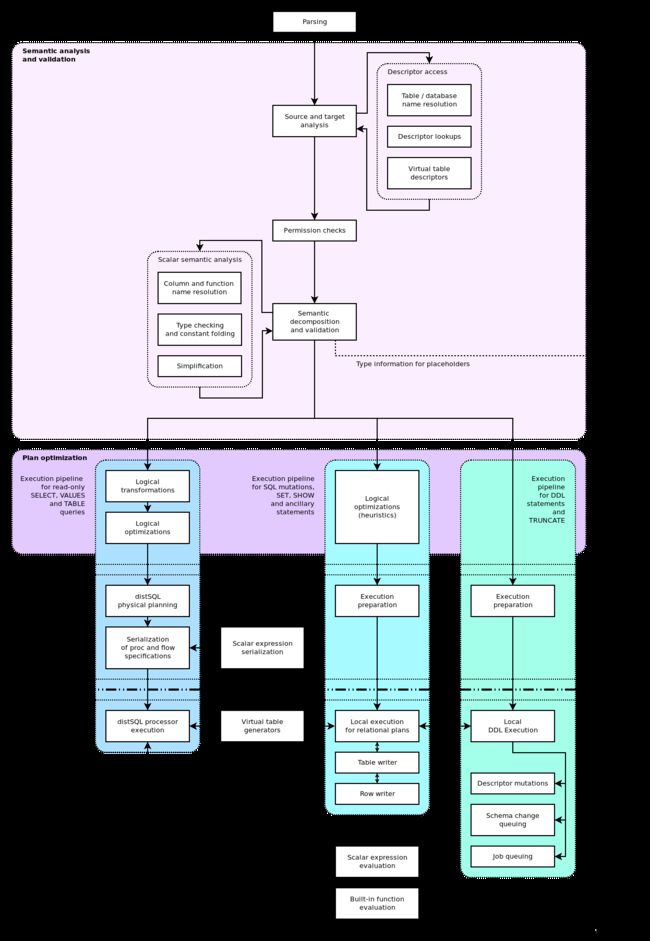
This diagram reveals the following:
该图揭示如下:
-
There are 3 main “groups” of statements 有三个主要的“群体”陈述::
- “Read-only” queries which only use SELECT, TABLE and VALUES.
- DDL statements (CREATE, ALTER etc) which incur schema changes.
- The rest (non-DDL), including SHOW, SET and SQL mutations.
- 只使用SELECT、TABLE和VALUES的“只读”查询。
- 引起模式更改的DDL语句(CREATE、ALTER等)。
- 其余(非DDL),包括SHOW、SET和SQL突变。
-
The logical preparation phase contains two sub-phases逻辑准备阶段包含两个子阶段::
- Semantic analysis and validation, which is common to all SQL statements;
- 语义分析和验证,这对所有SQL语句都是通用的;
- Plan optimization, which uses different optimization implementations (or none) depending on the statement group.
- 执行计划优化,根据语句组使用不同的优化实现(或没有)。
-
The physical preparation is performed differently depending on the statement group.
-
根据声明组不同地进行物理准备。
-
Query execution is also performed differently depending on the statement group, but with some shared components across statement groups.
-
查询执行也根据语句组的不同而不同,但是使用跨语句组的一些共享组件来执行。
Detailed model - Statements vs. Components
详细模型 - 语句与组件
The previous section revealed that different statements pass through different stages in the SQL layer. This can be further illustrated in the following diagram:
上一节揭示了不同的语句在SQL层中经过不同的阶段。这可以在下面的图表中进一步说明:
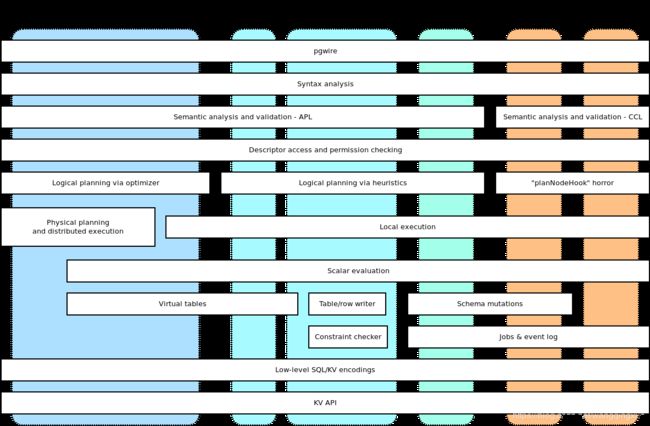
This diagram reveals the following:此图显示以下内容:
-
There are actually 6 statement groups currently:当前实际上有6个语句组:
- The “read-only” queries introduced above,
- DDL statements introduced above,
- SHOW/SET and other non-mutation SQL statements,
- SQL mutation statements,
- Bulk I/O statements in CCL code that influence the schema: IMPORT/EXPORT, BACKUP/RESTORE,
- Other CCL statements.
-
There are 2 separate, independent and partly redundant implementations of semantic analysis and validation. The CCL code uses its own. (This is bad and ought to be changed, see below.)
-
语义分析和验证有两个单独的、独立的和部分冗余的实现。CCL代码使用自己的代码。(这是不好的,应该进行更改,请参见下面的内容。)
-
There are 3 separate, somewhat independent but redundant implementations of logical planning and optimizations.
-
-
逻辑计划和优化有3种独立但冗余的实现。
the SQL cost-based planner and optimizer is the new “main” component. - the heuristic planner and optimizer was the code used before the cost-based optimizer was implemented, and is still used for every statement not yet supported by the optimizer. This code is being phased out as its features are being taken over by the cost-based optimizer.
- 启发式计划器和优化器是在实现基于成本的优化器之前使用的代码,并且仍然用于优化器尚未支持的每个语句。该代码正在逐步淘汰,因为它的特性正在被基于成本的优化器接管。
- the CCL planning code exists in a separate package and tries hard (and badly) to create logical plans as an add-on package. It interfaces with the heuristic planner via some glue code that was organically grown over time without any consideration for maintainability. So it's bad on its own and also heavily relies on another component (the heuristic planner) which is already obsolete. (This is bad; this code needs to disappear.)
- CCL计划代码存在于一个单独的包中,并努力(而且很不好地)将逻辑计划创建为一个附加程序包。它通过一些胶水代码与启发式规划器接口,这些胶水代码是随着时间的推移而有机地增长的,而没有考虑到可维护性。因此,它本身并不好,而且严重依赖于另一个已经过时的组件(启发式规划器)。(这很糟糕;此代码需要消失。)
-
-
There are 2 somewhat independent but redundant execution engines for SQL query plans: distributed and local.
-
SQL查询计划有两个独立但冗余的执行引擎:分布式和本地。
These two are currently being merged, although CCL statements have no way to integrate with distributed execution currently and still heavily rely on local execution. (This is bad; this needs to change.) -
虽然CCL语句目前无法与分布式执行集成,并且仍然严重依赖于本地执行,但是这两个语句目前正在被合并。(这是坏的,这需要改变。)
-
The remaining components are used adequately by the statement types that require them and not more.
-
其余组件由需要它们的语句类型充分使用,而不是更多。
This proliferation of components is a historical artifact of the CockroachDB implementation strategy in 2017, and is not to remain in the long term. The desired situation looks more like the following:
组件的这种扩散是CockroachDB实现2017年策略的历史产物,并且不会长期存在。期望的情况看起来更像下面这样:
That is, use the same planning and execution code for all the statement types.
也就是说,对于所有的语句类型都使用相同的计划和执行代码。
Detailed model - Components and Data Flow详细模型 - 组件和数据流
Here is a more detailed version of the summary of data flow interactions between components, introduced at the beginning:
下面是组件之间数据流交互概述的更详细版本,在开始部分介绍:
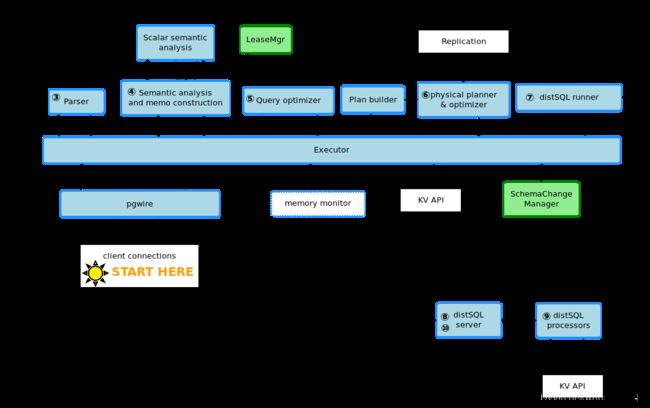
(Right-click then "open image in new window" to zoom in and keep the diagram open while you read the rest of this document.)
Boundary interfaces边界接口
There are two main interfaces between the SQL layer and its "outside world":
SQL层与其“外部世界”之间有两个主要接口:
- the network SQL interface, for clients connections that want to speak SQL (via pgwire);
- 网络SQL接口,用于SQL连接的客户端连接(通过pgwire);
- the transactional KV store, CockroachDB's next high-level abstraction layer;
- 事务性KV存储,CockroachDB的下一个高级抽象层;
I call these "main" interfaces because they are fundamentally necessary to provide any kind of SQL functionality. Also they are rather conceptually narrow: the network SQL interface is more or less "SQL in, rows out" and the KV interface is more or less "KV ops out, data/acks in".
我将这些称为“主要”接口,因为它们基本上是提供任何类型的SQL功能所必需的。 它们在概念上也相当狭窄:网络SQL接口就是“SQL in,rows out”,而KV接口就是“KV ops out,data / acks in”。
In addition, there exist also a few interfaces that are a bit less visible and emerge as a side-effect of how the current source code is organized:
此外,还存在一些不太明显的接口,并且作为当前源代码组织方式的副作用而出现:
-
the distSQL flows to/from "processors" running locally and on other nodes.
-
distSQL流,流向/流出本地和其他节点上的“处理器”。
- these establish their own network streams (on top of gRPC) to/from other nodes.
- 这些建立自己的网络流(在gRPC之上)到/来自其他节点。
- the interface protocol is more complex: there are sub-protocols to set up and tear down flows; managing errors, and transferring data between processors.
- 接口协议更加复杂:有一些子协议来建立和拆卸流;管理错误,以及在处理器之间传输数据。
- distSQL processors do not access most of the rest of the SQL code; the only interactions are limited to expression evaluation (a conceptually very small part of the local runner) and accessing the KV client interface.
- distSQL处理器不访问大部分SQL代码; 唯一的交互仅限于表达式评估(在概念上,本地运行的很小的一部分程序)和访问KV客户端接口。
-
the distSQL physical planner also talks directly to the distributed storage layer to get locality information about which nodes are leaseholders for which ranges.
-
distSQL物理计划器还直接与分布式存储层通信,以获得关于哪些节点是range的租约持有者的所在地信息。
-
the internal SQL interface, by which other components of CockroachDB can use the SQL interface to access lower layers without having to open a pgwire connection. The users of the internal interface include:
-
-
内部SQL接口,通过该接口,CockroachDB的其他组件可以使用SQL接口访问较低层,而无需打开pgwire连接。内部接口的用户包括:
within the SQL layer itself, the lease manager and the schema change manager, which are outlined below, - 在SQL层本身中,租约管理器和模式更改管理器,如下所述,
- the admin RPC endpoints, used by CLI tools and the admin web UI.
- RPC端点,使用CLI工具和管理员Web UI管理。
- outside of the SQL layer: metrics collector (db stats), database event log collector (db/table creation/deletion etc), etc
- SQL层之外:度量收集器(db stats)、数据库事件日志收集器(db/tablecreate/deletion等)
-
-
the memory monitor interface; this is currently technically in the SQL layer but it aims to regulate memory allocations across client connections and the admin RPC, so it has global state independent of SQL and I count it as somewhat of a fringe component.
-
内存监视器接口;从技术上讲,这是在SQL层中,但是它的目标是跨客户端连接和管理RPC调节内存分配,因此它具有独立于SQL的全局状态,我把它看作一个边缘组件。
-
the event logger: this is is where the SQL layer saves details about important events like when a DB or table was created, etc.
-
事件记录器:这是SQL层保存有关重要事件的详细信息的地方,比如何时创建DB或表等。
pgwire
(This is perhaps the architectural component that is the most recognizable as an isolated thing in the source code.
这也许是源代码中最容易识别为孤立事物的体系结构组件。)
Roles角色:
- primary: serve as a protocol translator between network clients that speak pgwire and the internal API of the SQL layer.
- 主要:作为pgwire的网络客户端和SQL层的内部API之间的协议转换器。
- secondary: authenticate incoming client connections.
- 其次:对传入的客户端连接进行身份验证。
How如何:
Overall architecture: event loop, one per connection (in separate goroutines, v3Conn.serve()). Get data from network, call into executor, put data into network when executor call returns, rinse, repeat.
总体架构:事件循环,每个连接一个(是一个单独的gonroutines,v3Conn.serve())。从网络中获取数据,调用执行器,在执行器调用返回时将数据放入网络,清洗,重复。
Interfaces接口:
-
The network side (
v3Conn.connimplementingnet.Conn): gets bytes of pgwire protocol in from the network, sends bytes of pgwire protocol out to the network. -
网络端(v3Conn.conn实现net.Conn):从网络中获取pgwire协议的字节,将pgwire协议的字节发送到网络。
-
memory monitor (
Server.connMonitor): pre-reserves chunks of memory from the global SQL pool (Server.sqlMemoryPool), that can be reused for smallish SQL sessions without having to grab the global mutex. -
内存监视器(Server.connMonitor):预先从全局SQL池(Server.sqlMemoryPool)中预留内存块,这些内存块可以在较小的SQL会话中重用,而无需获取全局互斥锁。
-
Executor: pgwire queues input SQL queries and COPY data packets to the "conn executor" in the
sqlpackage. For each input SQL query pgwire also prepares a "result collector" that goes into the queue. The executor monitors this queue, executes the incoming queries and delivers the results via the result collectors. pgwire then translates the results to response packets towards the client. -
Executor:pgwire队列将SQL查询和COPY数据包输入到sql包中的“conn executor”。对于每个输入SQL查询,pgwire也准备进入队列中的“结果收集器”。执行器Executor监视这个队列,执行传入的查询,并通过结果收集器返回结果。pgwire然后将结果转换为响应数据包发送给客户端。
Code lives in sql/pgwire.
Whom to ask for details: mattj, jordan, alfonso, nathan.
SQL front-end SQL前端
- the "Parser" (really: lexer + parser), in charge of syntactic analysis.
- scalar expression semantic analysis, including name resolution, constant folding, type checking and simplification.
- statement semantic analysis, including e.g. existence tests on the target names of schema change statements.
- “解析器Parser”(真:词素+语法分析器),负责句法分析。
- 标量表达式语义分析,包括名称解析、常量折叠、类型检查和简化。
- 语句语义分析,包括例如对模式更改语句的目标名称的存在性测试。
Reminder: "semantic analysis" as a general term is the phase in programming language transformers where the compiler determines if the input makes sense. The output of semantic analysis is thus conceptually a yes/no answer to the question "does this make sense" and the input program, optionally with some annotations.
提醒:“语义分析”作为一个通用术语是编程语言转换器的阶段,在此阶段,编译器确定输入是否有意义。因此,语义分析的输出在概念上是对“这是否有意义”的问题和输入程序的“是/否”的答案,可选地带有一些注释。
Syntactic analysis句法分析
Role: transform SQL strings into syntax trees将SQL字符串转换为语法树。
Interface:
- SQL string in, AST (Abstract Syntax Tree) out.
- 输入SQL字符串,输出AST(抽象语法树)
- mainly
Parser.Parse()insql/parser/parse.go. - 在sql/parser/parse.go中的Parser.Parse()方法
How:
The code is a bit spread out but quite close to what every textbook suggests.
代码有点散,但非常接近教科书的建议。
-
Parser.Parse()really:- creates a LL(2) lexer (
Scannerinscan.go) - invokes a go-yacc-generated LALR parser using said scanner (
sql.gogenerated fromsql.y)- go-yacc generates LALR(1) logic, but SQL really needs LALR(2) because of ambiguities with AS/NOT/WITH; to work around this, the LL(2) scanner creates LALR(1) pseudo-tokens marked with
_LAbased on its 2nd lookahead.
- go-yacc generates LALR(1) logic, but SQL really needs LALR(2) because of ambiguities with AS/NOT/WITH; to work around this, the LL(2) scanner creates LALR(1) pseudo-tokens marked with
- expects either an error or a
Statementlist from the parser, and returns that to its caller.
- creates a LL(2) lexer (
-
the list of tokens recognized by the lexer is automatically derived from the yacc grammar (cf.
sql/parser/Makefile) -
many AST nodes!!!
- until now we have wanted to be able to pretty-print the AST back to its original SQL form or as close as possible
- no good reason from a product perspective, it was just useful in tests early on so we keep trying out of tradition
- so the parser doesn't desugar most things (there can be
ParenExprorParenSelectnodes in the parsed AST...) - except it does actually desugars some things like
TRIM(TRAILING ...)toRTRIM(...).
- too many nodes, really, a hell to maintain. "IR project" ongoing to auto-generate all this code.
- until now we have wanted to be able to pretty-print the AST back to its original SQL form or as close as possible
-
AST nodes have a slot for a type annotation, filled in the middle-end (below) by the type checker.
Whom to ask for details: pretty much anyone.
Scalar expression semantic analysis标量表达式语义分析
Role: check AST expressions are valid, do some preliminary optimizations on them, provide them with types.
检查AST表达式是有效的,对它们进行一些初步优化,为它们提供类型。
Interface:
ExprAST in,TypedExprAST out (actually: typed+simplified expression)- via
analyzeExpr()(sql/analyze.go)
How:
- name resolution (in various places): replaces column names by
parser.IndexedVarinstances, replaces function names byparser.FuncDefreferences. parser.TypeCheck()/parser.TypeCheckAndRequire():- performs constant folding;
- performs type inference;
- performs type checking;
- memoizes comparator functions on
ComparisonExprnodes; - annotates expressions and placeholders with their types.
parser.NormalizeExpr(): desugar and simplify expressions:- for example,
(a+1) < 3is transformed toa < 2 - for example,
-(a - b)is transformed to(b - a) - for example,
a between c and dis transformed toa >= c and a <= d - the name "normalize" is a bit of a misnomer, since there is no real normalization going on. The historical motivation for the name was the transform that tries hard to pull everything but variable names to the right of comparisons.
- for example,
The implementation of these sub-tasks is nearly purely functional. The only wart is that TypeCheck spills the type of SQL placeholders ($1, $2 etc) onto the semantic context object passed through the recursion in a way that is order-sensitive.
Note: it's possible to inspect the expressions without desugaring and simplification using EXPLAIN(EXPRS, TYPES).
Whom to ask for details: the SQL team(s).
Statement semantic analysis语句语义分析
Role: check that SQL statements are valid.检查SQL语句是否有效。
Interface:
- There are no interfaces here, unfortunately. The code for statement semantic analysis is currently interleaved with the code to construct the logical query plan.
- 不幸的是,这里没有接口。语句语义分析的代码当前与构建逻辑查询计划的代码交织在一起。
- This does use (call into) expression semantic analysis as described above.
- 这确实使用了(调用)表达式语义分析,如上所述。
How:
- check the existence of databases or tables for statements that assume their existence
- 检查数据库或表是否存在
- this interacts with the lease manager to access descriptors
- 这与租约管理器交互来访问描述符。
- check permissions for statements that require specific privileges.
- 检查需要特定特权的语句的权限。
- perform expression semantic analysis for every expression used by the statement.
- 对语句使用的每个表达式执行表达式语义分析。
- check the validity of requested schema change operations for DDL statements.
- 检查DDL语句所请求的模式更改操作的有效性。
Code: in the opt package, also currently some code in the sql package.
Whom to ask for details: the SQL team(s).
SQL middle-endSQL中端
Two things are involved here:
- logical planner: transforms the annotated AST into a logical plan.
- 逻辑计划器:将注释的AST转换成逻辑计划。
- logical plan optimizer: makes the logical plan better.
- 逻辑计划优化器:使逻辑计划更好。
Logical planner逻辑计划器
Role: turn the AST into a logical plan.把AST变为逻辑计划。
Interface: see opt/optbuilder.
How:
- in-order depth-first recursive traversal of the AST;
- AST的有序深度优先递归遍历;
- invokes semantics checks on the way;
- 在途中调用语义检查;
- constructs a tree of “relational expression nodes”. This tree is also called “the memo” because of the data structure it uses internally.
- 构造一个“关系表达式节点”的树。 由于内部使用的数据结构,此树也称为“备忘录”。
- the resulting tree is the logical plan.
- 生成的树是逻辑计划。
Whom to ask for details: the SQL team(s).
Logical plan optimizer逻辑计划优化器
Role: make queries run faster.使查询更快。
Interface: see opt.
Whom to ask for details: the optimizer team.
SQL back-endSQL后端
Physical planner and distributed execution物理计划器额分布执行
Role: plan the distribution of query execution (= decide which computation goes to which node) and then actually run the query.
计划查询执行的分布(=决定哪个计算转到哪个节点),然后实际运行查询。
See the distSQL RFC and "Life of a SQL query" for details.
Code: pkg/sql/distsql{plan,run}
Whom to ask for details: the SQL execution team.
Distributed processors分布式处理器
Role: perform individual relational operations in a currently executing distributed plan.
在当前执行的分布式计划中执行单独的相关操作。
Whom to ask for details: the SQL execution team.
Executor执行器
Roles:
- coordinate between the other components
- 其他组件之间的协调
- maintain the state of the SQL transaction
- 维护SQL事务的状态
- maintain the correspondence between the SQL txn state and the KV txn state
- 维护SQL txn状态和KV txn状态之间的对应关系
- perform automatic retries of implicit transactions, or transactions entirely contained in a SQL string received from pgwire
- 执行隐式事务的自动重试,或完全包含在从pgwire接收的SQL字符串中的事务
- track metrics
- 跟踪指标
Interfaces:
-
from pgwire:
ExecuteStatements(),Prepare(),session.PreparedStatements.New()/Delete(),CopyData()/CopyDone()/CopyEnd(); -
for the internal SQL interface:
QueryRow(),queryRows(),query(),exec(); -
对于内部SQL接口:
QueryRow(),queryRows(),query(),exec(); -
into the other components within the SQL layer: see the interfaces in the previous sections of this document;
-
进入SQL层中的其他组件:参见本文前面部分中的接口;
-
towards the memory monitor: to account for result set accumulated in memory between transaction boundaries;
-
面向内存监视器:对在事务边界之间的内存中累积的结果集进行说明;
How:
- maintains its state in the
Sessionobject; - 在Session对象中维护其状态;
- there's a monster spaghetti code state machine in
executor.go; - 在executor.go中有一个怪物意大利面条代码状态机;
- there's a monster "god class" called
planner; - 有一个叫做planner的怪物“神类”;
- it's a mess, and yet it works!
- 这是一团糟,但它的能正常工作!
Whom to ask for details: andrei, nathan
The two big auxiliaries量大辅助对象
SQL table lease managerSQL表租约管理器
This thing is responsible for leasing cached descriptors to the rest of SQL.
这件事负责其余的SQL缓存描述符。
Interface:
- the lease manager presents an interface to "get cached descriptors" for the rest of the SQL code.
- 租赁管理器为其余的SQL代码提供了“获取缓存描述符”的接口。
Why:
- we don't want to retrieve the schema descriptors using KV in every transaction, as this would be slow, so we cache them.
- 我们不希望在每个事务中使用KV检索模式描述符,因为这会很慢,所以我们缓存它们。
- since we cache descriptors, we need a cache consistency protocol with other nodes to ensure that descriptors are not cached forever and that cached copies are not so stale as to be invalid when there are schema changes. The lease manager abstracts this protocol from the rest of the SQL code.
- 因为我们缓存描述符,所以我们需要与其他节点建立缓存一致性协议,以确保描述符不会永远缓存,并且缓存副本不会过时,以至于在存在模式更改时无效。 租约管理器从其余的SQL代码中抽象出该协议。
How:
It's quite complicated.这很复杂。
However the state of the lease manager is itself stored in a SQL table system.leases, and thus internally the lease manager must be able to issue SQL queries to access that table. For this, it uses the internal SQL interface. It's really like "SQL calling into itself". The reason why we don't get "turtles all the way down" is that the descriptor for system.leases is not itself cached.
然而,租约管理器的状态本身存储在SQL表system.leases中,因此租约管理器在内部必须能够发出SQL查询来访问该表。为此,它使用内部SQL接口。这真的像“SQL调用自己”。我们之所以没有获得“turtles all way down”,是因为system.leases的描述符本身没有被缓存。
Note that the lease manager uses the same KV txn object as the ongoing SQL session, to ensure that newly leased descriptors are atomically consistent with the rest of the statements in the same transaction.
注意,租约管理器使用与正在进行的SQL会话相同的KV txn对象,以确保新租用的描述符与同一事务中的其余语句在原子上一致。
Code: sql/lease.go.
Whom to ask for details: vivek, dt, andrei.
Schema change manager模式变更管理器
This is is responsible for performing changes to the SQL schema.
负责执行对SQL模式的更改。
Interface:
- "intentions" to change the schema are defined as mutation records on the various descriptors,
- 改变模式的“意图”被定义为各种描述符上的突变记录。
- once mutation records are created, client components can write the descriptors back to the KV store, however they also must inform the schema change manager that a schema change must start via
notifySchemaChange. - 一旦创建了突变记录,客户端组件就可以将描述符写回KV存储,但是它们也必须通知模式更改管理器模式更改必须通过notifySchemaChange开始。
Why:
Adding a column to a very large table or removing a column can be very long. Instead of performing these operations atomically within the transaction where they were issued, CockroachDB runs schema changes asynchronously.
将列添加到非常大的表或删除列可能时间很长。CockroachDB不是在发出它们的事务中自动执行这些操作,而是异步运行模式更改。
Then asynchronously the schema change manager will process whatever needs to be done, such as backfilling a column or populating an index, using a sequence of separate KV transactions.
然后,模式更改管理器将异步地处理需要执行的任何操作,例如使用一系列单独的KV事务回填列或填充索引。
How:
It's quite complicated.这很复杂。
Unlike the lease manager, the current state of ongoing schema changes is not stored in a SQL table (it's stored directly in the descriptors); however the schema change manager is (soon) to maintain an informational "job table" to provide insight to users about the progress of schema changes, and that is a SQL table.
与租约管理器不同,正在进行的模式更改的当前状态不存储在SQL表中(它直接存储在描述符中);但是,模式更改管理器(很快)将维护一个信息“作业表”,以便向用户提供关于模式更改进度的展示,那是一个SQL表。
So like the lease manager, the schema change manager uses the internal SQL interface, and we have another instance here of "SQL calling into itself". The reason why we don't get "turtles all the way down" is that the schema change manager never issues SQL that performs schema changes, and thus never issues requests to itself.
因此,与租约管理器一样,模式更改管理器使用内部SQL接口,这里还有“SQL调用自身”的另一个实例。我们之所以没有得到“turtles all way down”,是因为模式更改管理器从不发出执行模式更改的SQL,因此从不向自身发出请求。
Also the schema change manager internally talks to the lease manager: leases have to stay consistent with completed schema changes!
此外,模式更改管理器在内部与租约管理器通信:租约必须与完成的模式更改保持一致!
Code: sql/schema_changer.go.
Whom to ask for details: vivek, dt.
Fringe interfaces and components边缘界面与构件
Memory monitors内存监控器
Memory monitors have a relatively simple role: remember how much memory has been allocated so far and ensure that the sum of allocations does not exceed some preset maximum.
内存监视器具有相对简单的作用:记住到目前为止已分配了多少内存,并确保分配总和不超过某个预设的最大值。
To ensure this:
- monitors get initialized with the maximum value ("budget") they will support;
- 监视器以他们支持的最大值(“预算”)初始化;
- other things register their allocations to their monitor using an "account";
- 其他东西用“帐户”将他们的分配登记到他们的监视器上;
- registrations can fail with an error "not enough budget";
- 注册可能失败,错误显示“预算不足”;
- all allocations can be de-registered at once by calling
Closeon an account. - 所有分配都可以通过在帐户上调用“close”来立即注销。
In addition a monitor can be "subservient" to another monitor, with its allocations counted against both its own budget and the budget of the monitor one level up.
此外,监视器可以“从属于”另一个监视器,其分配根据其自己的预算和上一级监视器的预算。