通过Alertmanager实现Prometheus的告警
Prometheus本身不支持的告警功能,主要通过插件Alertmanager来实现告警。Alertmanager用于接收Prometheus发送的告警信息并对告警进行一系列的处理后发送给指定的用户或组。
Prometheus触发一条告警的过程如下:
prometheus server —>触发法制—>超出指定时间—>alertmanager—>分组|抑制|静默—>媒体类型—>邮件|钉钉|微信等等。
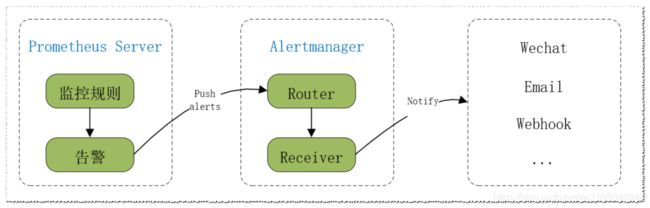
一、安装配置Alertmanager
下载解压
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.20.0/alertmanager-0.20.0.linux-amd64.tar.gz
tar -zxf alertmanager-0.20.0.linux-amd64.tar.gz -C /usr/local/
$ cd /usr/local/
$ mv alertmanager-0.20.0.linux-amd64 alertmanager
这里先讲一个坑:
Alermanager会将数据保存到本地中,默认的存储路径为data/,我们在启动文件中直接用--storage.path参数指定,不然会报错如下:
Jun 01 17:04:56 localhost.localdomain alertmanager[9742]: level=error ts=2020-06-01T09:04:56.626Z caller=main.go:236 msg="Unable to create data directory" err="mkdir data/: permission denied"
创建存储目录
mkdir -p /usr/local/alertmanager/data
并用--config.file指定alertmanager配置文件路径。
创建启动文件
cat > /usr/lib/systemd/system/alertmanager.service <<EOF
[Unit]
Description=alertmanager
Documentation=https://github.com/prometheus/alertmanager
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/usr/local/alertmanager/data
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
配置告警信息
在配置之前,先备份下alertmanager的配置文件
cp /usr/local/alertmanager/alertmanager.yml /usr/local/alertmanager/alertmanager.yml_bak
然后修改alertmanager.yml
$ cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'PNRUAELMPDOMTEMP' # 这里是邮箱的授权密码,不是登录密码
smtp_require_tls: false
route: # route用来设置报警的分发策略
group_by: ['alertname'] # 采用哪个标签来作为分组依据
group_wait: 30s # 组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出
group_interval: 10s # 两组告警的间隔时间
repeat_interval: 20m # 重复告警的间隔时间,减少相同邮件的发送频率
receiver: 'default-receiver' # 设置默认接收人
routes: # 可以指定哪些组接收哪些消息
- receiver: 'default-receiver'
continue: true
group_wait: 10s
- receiver: 'ding-receiver'
group_wait: 10s
match_re: # 根据标签分组,匹配标签dest=hzjf的为ding-receiver组
dest: hzjf
receivers:
- name: 'default-receiver'
email_configs:
- to: '[email protected]'
- name: "ding-receiver"
webhook_configs:
- url: 'http://xx.xx.xx.xx/dingtalk'
send_resolved: true
启动Alertmanager
$ chown -R prometheus:prometheus /usr/local/alertmanager
$ systemctl daemon-reload
$ systemctl start alertmanager.service
$ systemctl enable alertmanager.service
$ systemctl status alertmanager.service
$ ss -tnl|grep 9093
web ui查看 : http://alertmanager_ip:9093
然后再说一个坑:上面配置了使用邮件报警,但是在发送邮件的时候会有报错Jun 05 13:35:21 localhost.localdomain postfix/sendmail[9446]: fatal: parameter inet_interfaces: no local interface found for ::1,需要改一下postfix的配置文件:
vim /etc/postfix/main.cf
# 把
inet_interfaces = localhost
# 改为
inet_interfaces = all
# 即可
二、配置Prometheus与Alertmanager通信
vim /usr/local/prometheus/prometheus.yml
alerting:
alertmanagers: # 配置alertmanager
- static_configs:
- targets:
- 127.0.0.1:9093 #alertmanager服务器ip端口
rule_files: # 告警规则文件
- 'rules/*.yml'
三、配置报警规则
上面已经定义了,把报警规则的定义文件放在rules目录下,所以先要创建这个目录:
mkdir -p /usr/local/prometheus/rules
然后来创建报警规则,这里我们创建三个报警规则:
cat > /usr/local/prometheus/rules/node.yml <<"EOF"
groups:
- name: hostStatsAlert
rules:
- alert: InstanceDown
expr: up == 0
for: 30s
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 30 seconds."
- alert: hostCpuUsageAlert
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 85
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 85
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
EOF
- alert:报警规则名称
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附件到告警上的一组附加标签
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
检查告警规则
$ /usr/local/prometheus/promtool check rules /usr/local/prometheus/rules/node.yml
Checking /usr/local/prometheus/rules/node.yml
SUCCESS: 3 rules found
重启prometheus使告警规则生效。
$ chown -R prometheus:prometheus /usr/local/prometheus/rules
$ systemctl restart prometheus
四、验证
首先在prometheus界面的alert可以看到配置的3条报警规则。

1、验证InstanceDown报警规则
停止192.168.0.182节点上的node_exporter服务,然后查看效果。
$ systemctl stop node_exporter
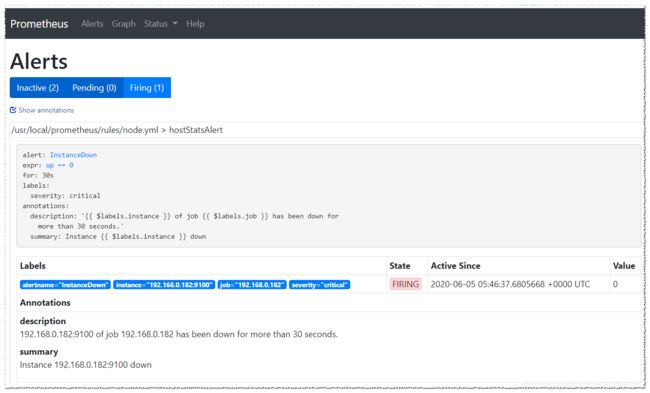
- 绿色表示正常。
- 红色状态为
PENDING表示alerts还没有发送至Alertmanager,因为rules里面配置了for: 30s。 - 30s之后状态由
PENDING变为FIRING,此时,prometheus才将告警发给alertmanager,在Alertmanager中可以卡看到有一个aleret。
收到邮件:
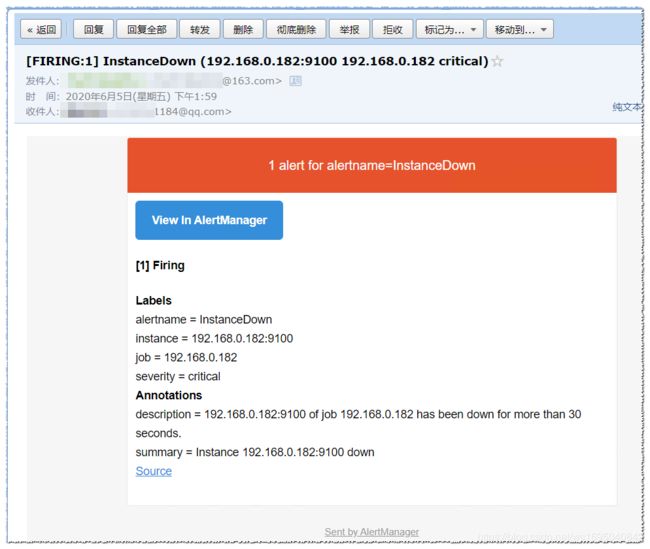
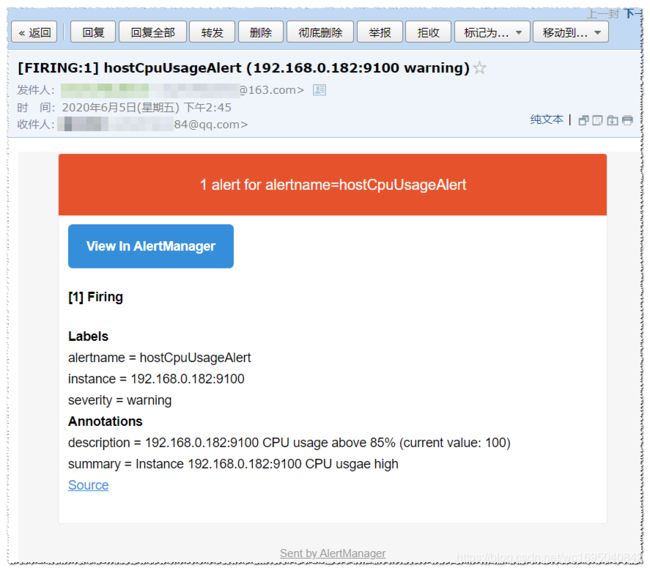
2、验证
我们可以手动拉高系统的CPU使用率:
cat /dev/zero>/dev/null
运行命令后cpu使用量会迅速上升。
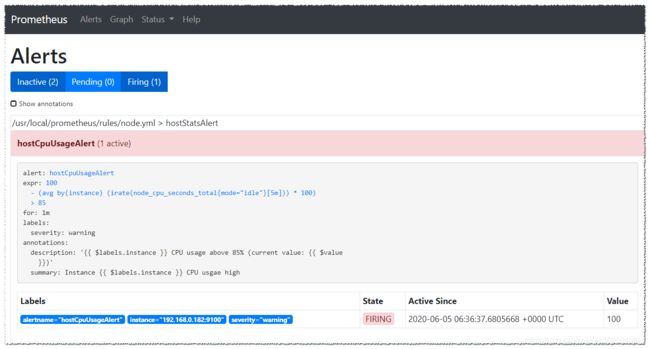
收到邮件:
参考文章:
https://www.cnblogs.com/xiaobaozi-95/p/10740511.html
https://www.bookstack.cn/read/prometheus-book/alert-prometheus-alert-rule.md