【监控告警】02-Promtheus的学习之路
prometheus采用的是 拉模式为主,推模式为辅 的方式采集数据。
Prometheus 作为一个指标系统天生就不是精确的——由于指标本身就是稀疏采样的,事实上所有的图表和警报都是”估算”,我们也就不必太纠结于图表和警报的对应性,能够帮助我们发现问题解决问题就是一个好监控系统。
当然,有时候我们也得证明这个警报确实没问题,那可以看一眼 `ALERTS` 指标。`ALERTS` 是 Prometheus 在警报计算过程中维护的内建指标,它记录每个警报从 Pending 到 Firing 的整个历史过程,拉出来一看也就清楚了。

更多关于监控告警项目内容请参考:【监控告警】01-网关的需求与改造
Prometheus 的局限
Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。
对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择 Federate、Cortex、Thanos等方案。
监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说 Thanos 去重的时候会提到。
Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做统计和推断,产生一些反直觉的结果,这个后面会详细展开。二来查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方。
Prometheus 为避免时区混乱,在所有组件中专门使用 Unix Time 和 Utc 进行显示。不支持在配置文件中设置时区,也不能读取本机 /etc/timezone 时区。
PromQL之APISIX
根据APISIX原生监控指标基础上,进行的二次加工和计算
其中,route="448693711467971471" 指的是实际配置在APISIX中的路由ID
1、异常率
sum(apisix_http_status{route="448693711467971471",code="500"}- apisix_http_status{route="448693711467971471",code="500"} offset 5m) / sum(apisix_http_status{route="448693711467971471"} - apisix_http_status{route="448693711467971471"} offset 5m)2、异常次数
sum(apisix_http_status{route="448693711467971471",code="500"} - apisix_http_status{route="448693711467971471",code="500"} offset 5m)3、访问次数
sum(apisix_http_status{route="448693711467971471"} - apisix_http_status{route="448693711467971471"} offset 5m)4、处理时间
histogram_quantile(0.90, sum(rate(apisix_http_latency_bucket{type="upstream",route="448693711467971471"}[1m])) by (le))HTTP API
通过HTTP API,我们可以利用http请求,向Prometheus传递计算表达式,返回我们想要的结果
具体调用方法如下:
http://192.168.2.80:19090/api/v1/query?query=sum(apisix_nginx_http_current_connections{state="accepted", instance=~"192.168.2.80:9092"})&time=1677178798.683如果不太确定请求的URL格式,比较简单的查看查询语句的方式是:
在浏览器chrome调试窗口中可以发现真正请求的URL:
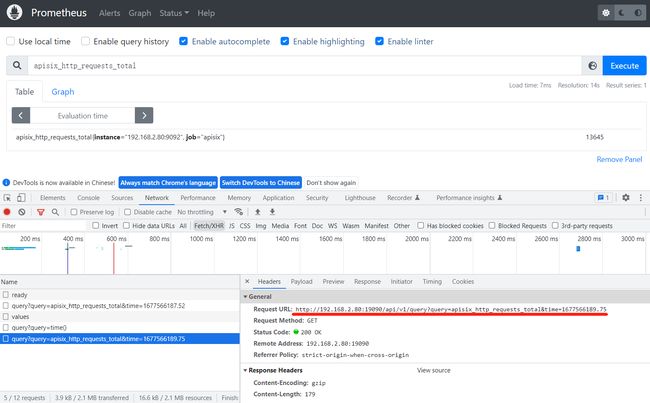
在业务对接APISIX监控时,就遇到了这样的一个需求:业务系统需要获取某个路由的异常次数、异常率、访问次数、响应时间。
此时就可以利用Prometheus提供的HTTP API,URL中传递query参数。 Prometheus接收到计算公式后,会根据公式计算并返回结果。
监控指标
histogram_quantile 的"反直觉"
摘自: Prometheus 常用函数 histogram_quantile 的若干“反直觉”问题
P90/P99 表示什么
有什么实际含义和用处?
经常用来衡量服务响应延迟。
以最常用的 p99 为例,它衡量了 99% 的情况下,能达到的最大服务响应延迟,99%的延迟都低于这个数值,即绝大多数情况下的最差响应情况。
以p90为例,它衡量了 90% 的情况下,能达到的最大服务响应延迟,90%的延迟都低于这个数值,即多数情况下的最差响应情况。
监控统计区间问题
问题描述:
在进行业务测试的过程中,有些指标会出现:在单案例、单场景中正常告警;在多案例、多场景的测试中存在未告警的情况。
之所以出现这样问题的原因 ,是因为这些监控指标的统计区间不一样。
例如:Prometheus判断延迟5s的情况下,虽然触发了报警,但是还没有达到发送到Alertmanger的条件(处于Pending状态),由于案例测试的时间太短了,到了实际生产上,可能就是一个网络抖动的一个场景。
鉴于1分钟的区间数据很快就会恢复,5分钟的话差不多就能避免这个问题。这只是告警,能够保证在接受范围内发出邮件就可以了,如果问题严重的话还是得靠开发人员去解决。
设置的区间范围越短,可以理解为越不灵敏,但是可以规避很多网络问题。区间越长,因为有足够的采样数据,就越灵敏。但是,如果时间长的话,还会有另外一个问题,就是可能会出现即使服务恢复正常了,它还是会报警。因为在区间范围内,还会包含之前的异常数据。所以计算出来的还是异常的。
在设计告警统计区间时,需要考虑多个因素。时间范围的长度应该根据实际情况而定,不能一概而论。如果过短,会导致灵敏度不足,无法及时捕捉问题;如果过长,会导致误报警情况的出现。因此,需要综合考虑时间长度和实际情况,才能制定出最合适的告警统计区间策略,确保系统能够及时准确地发现并解决问题。
告警规则配置
Prometheus 告警规则配置:监控服务器宕机的时间超过1分钟就发送告警邮件。
groups:
- name: Test-001 # 组的名字,在这个文件中必须要惟一
rules:
- alert: InstanceDown # 告警的名字,在组中须要惟一
expr: up == 0 # 表达式, 执行后果为true: 示意须要告警
# 超过多少工夫才认为须要告警(即up==0须要持续的时间) 这个参数主要用于降噪
# 很多类似响应时间这样的指标都是有抖动的,通过指定 Pending Duration,我们可以 过滤掉这些瞬时抖动,让 on-call 人员能够把注意力放在真正有持续影响的问题上。
for: 1m
labels:
severity: warning # 定义标签
annotations:
summary: "服务 {{ $labels.instance }} 下线了"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- name: Cpu
rules:
- alert: Cpu01
expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 80"
for: 1m
labels:
service: demo
severity: info # 自定一个一个标签 info 级别
annotations:
summary: "服务 {{ $labels.instance }} cpu 使用率过高"
description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过来5分钟内应用过高,cpu 使用率 {{humanize $value}}."
- alert: Cpu02
expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 90"
for: 1m
labels:
service: demo
severity: warning # 自定一个一个标签 warning 级别
annotations:
summary: "服务 {{ $labels.instance }} cpu 使用率过高"
description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过来5分钟内应用过高,cpu 使用率 {{humanize $value}}."配置字段含义
Prometheus 告警规则文件,下列字段的含义:
summary: 描述告警的概要信息
description: 用于描述告警的详细信息
$labels.
$value: 则可以获取当前PromQL表达式计算的样本值

recording rules
recording rules 是提前设置好一个比较花费大量时间运算或经常运算的表达式,其结果保存成一组新的时间序列数据。当需要查询的时候直接会返回已经计算好的结果,这样会比直接查询快,同时也减轻了PromQl的计算压力,同时对可视化查询的时候也很有用,可视化展示每次只需要刷新重复查询相同的表达式即可。
在配置的时候,除却 record:
groups:
- name: http_requests_total
rules:
- record: job:http_requests_total:rate10m
expr: sum by (job)(rate(http_requests_total[10m]))
lables:
team: operations
- record: job:http_requests_total:rate30m
expr: sum by (job)(rate(http_requests_total[30m]))
lables:
team: operationsPrometheus 时区问题
Prometheus 时区问题的讨论
关于 timezone 的讨论,可以看这个issue
https://github.com/prometheus/prometheus/issues/500
Prometheus 内存问题
随着规模变大,Prometheus 需要的 CPU 和内存都会升高,内存一般先达到瓶颈,这个时候要么加内存,要么集群分片减少单机指标。这里我们先讨论单机版 Prometheus 的内存问题。
原因:
Prometheus 的内存消耗主要是因为每隔2小时做一个 Block 数据落盘,落盘之前所有数据都在内存里面,因此和采集量有关
加载历史数据时,是从磁盘到内存的,查询范围越大,内存越大。这里面有一定的优化空间
一些不合理的查询条件也会加大内存,如 Group 或大范围 Rate
我的指标需要多少内存:
How much RAM does Prometheus 2.x need for cardinality and ingestion?
有什么优化方案:
Sample 数量超过了 200 万,就不要单实例了,做下分片,然后通过 Victoriametrics,Thanos,Trickster 等方案合并数据。
评估哪些 Metric 和 Label 占用较多,去掉没用的指标。2.14 以上可以看 Tsdb 状态。
查询时尽量避免大范围查询,注意时间范围和 Step 的比例,慎用 Group。
如果需要关联查询,先想想能不能通过 Relabel 的方式给原始数据多加个 Label,一条Sql 能查出来的何必用Join,时序数据库不是关系数据库。
Prometheus 内存占用分析:
通过 pprof分析:
Optimising Prometheus 2.6.0 Memory Usage with pprof
启动参数
Prometheus 启动命令
#启动prometheus软件,指定配置文件设置数据保留时间为90天设置日志级别
nohup ./prometheus --config.file=/software/prometheus-2.33.3.linux-amd64/etc/prometheus.yml --log.level=debug > /software/prometheus-2.33.3.linux-amd64/prometheus.log 2>&1 &
#确认9090端口是否启动,此时命令应该有输出。
ss -alntup | grep -i 9090 生产推荐配置
Prometheus 生产推荐配置
数据采集频率配置:
scrape_interval: 15s # 每15s采集一次数据,默认1min,经验值为10s-60s
evaluation_interval: 15s # 每15s做一次告警检测,计算一条规则配置的时间间隔参考资料:
https://blog.csdn.net/yujia_666/article/details/109311340
https://blog.csdn.net/u012516914/article/details/124905920?spm=1001.2014.3001.5506