推荐系统召回模型之MIND用户多兴趣网络

MIND算法全称为:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall,由阿里的算法团队开发。
1. 概括
工业界的推荐系统通常包括召回阶段和排序阶段。召回阶段我们根据用户的兴趣从海量的商品中去检索出用户(User)感兴趣的候选商品( Item),满足推荐相关性和多样性需求。目前的深度学习模型的套路是将User和Item在同一向量空间中进行Embedding表示,使用User的Embedding表示User的兴趣。然而实际情况是User的兴趣是多种多样的,使用一个Embedding不足以全面的表示User的兴趣信息。
该文的创新点在于:
1. 通过Mulit-Interest Extractor Layer 获取User的多个兴趣向量表达。提出了具有动态路由特点的多兴趣网络,利用Dynamic Routing以自适应地聚合User历史行为到User兴趣表达向量中;
2. 通过Label-Aware Attention 标签感知注意力机制,指导学习User的多兴趣表达Embedding;
2. MIND模型结构
MIND模型的整体结构如下:
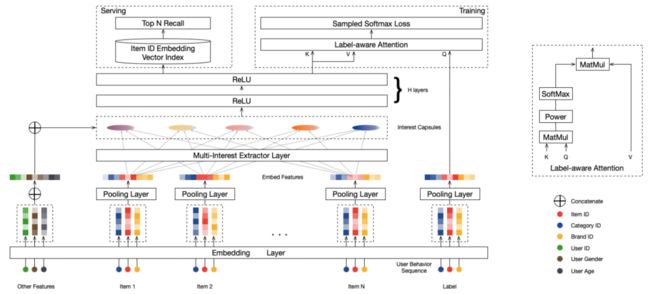
图1 MIND网络结构图
输入层:
User画像特征;
User行为特征,即产生行为(历史点击或购买等)的Item列表和Item属性列表;
正标签,即User真实发生行为(下一次点击或购买等)的 Item ID;
Embedding层:
将ID信息映射成稠密向量,即Embedding;
Pooling层:
将行为序列的Item和Item属性的Embedding表达进行mean, sum或max等池化操作;
Multi-interest Extractor 层:(本文重点)
输入:User行为序列的Embedding Features,即 Pooling层 结果;
输出:Interest Capsules,用户的多兴趣Embedding表达;
H layers:
多个兴趣Embedding分别经过两个全连接层,得到User最终的多个兴趣Embedding表达;
Training服务:
输入层:
H layers 结果作为 Label-aware Attention层的Keys和Values(此时Keys=Values);
正标签,即User真实发生行为(下一次点击或购买等)的 Item ID,作为Query;
Label-aware Attention层:
对输入的Keys和Query做内积、Softmax等操作作为Keys的权重值w;
使用w与Values做内积,然后对应元素求和,得到一个Embedding,作为User对当前正标签Item的兴趣分布;
Sampled Softmax Loss层:
抽取多个负标签,与正标签组成 Sampled 组;
使用 tf.nn.sampled_softmax_loss 函数得到正标签的概率;
Serving服务:
输入层:
H layers 结果作为 User 最终的多个兴趣Embedding表达;
全集 Item 的Embedding表达;
TopN Recall:
针对User的多兴趣Embedding,根据faiss或annoy在全集 Item 池中检索,获得User兴趣Embedding所感兴趣的候选Item集合;
3. MIND模型理论部分
3.1 MIND模型的问题定义
每个User-Item的实例可以使用三元组 表示,其中 表示User发生行为的Item集合, 表示User的画像特征(例如:性别,年龄等), 表示目标Item的画像特征(例如Id, 类型Id, 品牌Id等)。
MIND模型的主要任务:
(1)学习一个函数可以将User-Item实例映射为User的兴趣Embedding表达集合:
其中: 表示Embedding的向量长度, 表示User的兴趣Embedding个数。
(2)学习Item的Embedding表达:
(3)线上Serving服务检索,获得N个User感兴趣的候选Item池:
3.2 Embedding和Pooling层
MIND模型的输入是:User特征 ,User行为序列特征 ,和label Item 。
User Embedding:User Id(例如:年龄,性别等)经过Embedding 后通过Concat 操作后作为用户侧特征输入;
Item Embedding:Item Id(例如:Item Id,类型Id,品牌Id等)经过Embedding 后统一经过Pooling 层得到Item侧特征输入;
User行为序列特征Embedding:多个Item Embedding&Pooling 后,得到用户行为序列输入 。
3.3 Multi-Interest Extractor Layer
该层主要是采用多个向量来表达 User 不同的兴趣,将 User 的历史行为分组到多个 Interest Capsules 的过程。实现逻辑如下:

输入:
User行为序列特征Embedding, ;
迭代次数 ;
兴趣胶囊个数 ;
输出:
兴趣胶囊Embedding,
定义:
(1)动态兴趣个数 ;
(2)低阶行为向量Embedding表达: 代表User的行为向量(同 );
(3)高阶兴趣向量Embedding表达: 代表User的兴趣向量(同 );
(4)行为向量 与兴趣向量 之间的 路由logit:
(5)双线性映射矩阵:
步骤:
(1)计算兴趣Embedding个数 ;
(2)初始化 (使用正态分布初始化);
(3)遍历迭代次数 :
(3.1)对所有的行为路由 ,计算 ;
(3.2)对所有的兴趣路由 ,计算 ,和 ;
(3.3)迭代更新 ;
3.4 Label-aware Attention Layer
通过多兴趣提取器层,对用户行为序列embedding 我们得到多个个兴趣Capsule 表达用户多样的兴趣分布,不同的兴趣Capsule表示用户兴趣的不同偏好。为了评估多个兴趣Capsule对目标Item 相关度及贡献度,我们设计标签意识的Attention 机制来衡量目标Item 选择使用哪个兴趣Capsule,具体表述见 Training服务。表达式:
其中: 是指数。
3.5 Training & Serving
训练的目标是:使用User的Embedding ,正标签 Item Embedding ,和随机抽样负标签 Items Embedding ,使用如下公式进行计算:
损失函数:
ok,MIND的理论部分介绍到此结束,欢迎讨论交流。
参考:
1. Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
2. Dynamic Routing Between Capsules
3. Attention Is All You Need
![]()
欢迎关注“python科技园”,然后添加小编进群交流。
