前段时间下载了网上流传的 52G葫芦娃 ,解压之后,是txt文件。
网上流传的52G葫芦娃

文件列表

花了点时间,写了个脚本把数据入库。第一次用python写东西,写的不好请指正!
因为数据量很大,运行需要很长时间。在我的破电脑上,跑了一天才入库完成。
献上代码:
# coding=utf-8 import os import time import pymysql.cursors import re import threading from queue import Queue from queue import Empty # 程序会根据邮箱前的账号长度生成不同的表 # 如:[email protected],会存入 email_8 这个表 # 生成的表有 5 个字段: # id 主键自增序号 # email 邮箱账号 ,如 zhangsan # password 密码 # email_type 邮箱类型,163 表示 163.com, 126 表示126.com,其他存全名 # remark 备注,源数据有些包含了 昵称,MD5 等等其他信息 # 错误日志存放位置,必须是文件夹,会生成多个文件,保存未成功处理的数据 error_log_dir = "I:\\3_data\\error" # 原始数据位置,程序会遍历此文件夹下的所有文件 data_file_path = "I:\\3_data\\52G葫芦娃" # 缓冲区大小,超出后会提交到数据库 buf_size = 50000 # 提交队列大小,超过后会阻塞 queue_size = 15 # 表名称前缀 table_name = "email_" # 单个错误日志文件最大行数 max_log_line_num = 400000 separators = ("------", "-----", "----", ",", "\t", "|", " ", " ", " ", " ", " ", " ", " ") # 数据库连接信息 connection = pymysql.connect(host='127.0.0.1', user='root', password='123456', db='163_email', port=3306, charset='utf8') class DataTransfer: def __init__(self, _data_submit): self.__handler_dict = {} self.data_num = 0 self.data_submit = _data_submit def transfer_data(self, account, password, email_type, remark): self.data_num = self.data_num + 1 handler = self.__get_handler(account) handler.handle_data(account, password, email_type, remark) def flush(self): handlers = sorted(list(self.__handler_dict.values()), key=lambda x: x.table_name) for handler in handlers: handler.flush() print("\n 共插入数据 {0} 条\n".format(self.data_num)) for handler in handlers: print(" {0} 表插入数据 {1} 条".format(handler.table_name, handler.data_size)) def __get_handler(self, account): account_length = len(account) if 6 <= account_length <= 14: fw = account[0].lower() ascii_fw = ord(fw) if 48 <= ascii_fw <= 52: fw = "04" elif 53 <= ascii_fw <= 57: fw = "59" elif 97 <= ascii_fw <= 100: fw = "ad" elif 101 <= ascii_fw <= 104: fw = "eh" elif 105 <= ascii_fw <= 108: fw = "il" elif 109 <= ascii_fw <= 112: fw = "mp" elif 113 <= ascii_fw <= 116: fw = "qt" elif 117 <= ascii_fw <= 119: fw = "uw" elif 120 <= ascii_fw <= 122: fw = "xz" else: fw = "00" tn = "{0}_{1}".format(account_length, fw) else: tn = str(account_length) if tn not in self.__handler_dict: self.__handler_dict[tn] = DataHandler(account_length, table_name + tn, self.data_submit) return self.__handler_dict.get(tn) class DataHandler: CREATE_STATEMENT = "CREATE TABLE IF not exists `{0}` ( " \ "`id` int(11) NOT NULL AUTO_INCREMENT, " \ "`email` char({1}) DEFAULT NULL, " \ "`password` varchar(40) DEFAULT NULL, " \ "`email_type` varchar(40) DEFAULT NULL, " \ "`remark` varchar(100) DEFAULT NULL, " \ "PRIMARY KEY (`id`), " \ "UNIQUE KEY `id_UNIQUE` (`id`) " \ ") ENGINE=InnoDB DEFAULT CHARSET=utf8" INSERT_STATEMENT = "INSERT INTO {0}(email, password, email_type, remark) VALUES (%s, %s, %s, %s)" def __init__(self, _length, _table_name, _data_submit): self.__data_buf = [] self.__data_buf_count = 0 self.data_size = 0 self.length = _length self.table_name = _table_name self.data_submit = _data_submit self.__insert_statement = DataHandler.INSERT_STATEMENT.format(self.table_name) sql = DataHandler.CREATE_STATEMENT.format(self.table_name, self.length) print("+++++++++++++++++++++++ 创建表:{0} +++++++++++++++++++++++".format(self.table_name)) self.data_submit.submit_task(sql, None) def handle_data(self, account, password, email_type, remark): self.data_size = self.data_size + 1 self.__data_buf.append([account, password, email_type, remark]) self.__data_buf_count = self.__data_buf_count + 1 if self.__data_buf_count >= buf_size: self.flush() def flush(self): if not self.__data_buf_count: return try: i = self.data_submit.submit_task(self.__insert_statement, self.__data_buf) print("--------- 提交入库任务: {0} 条数据入表 {1} ,当前队列长度 {2} ---------".format(self.__data_buf_count, self.table_name, i)) self.__data_buf_count = 0 self.__data_buf = [] except Exception as e: error_log.log_exception(e) if self.__data_buf_count > 0: for m in self.__data_buf: error_log.log_db_error("{0},{1},{2},{3}".format(m[0], m[1], m[2], m[3])) self.__data_buf_count = 0 self.__data_buf = [] class DataSubmit(threading.Thread): def __init__(self, _connection): super(DataSubmit, self).__init__() self.connection = _connection self.queue = Queue(queue_size) self.r = True self.cursor = self.connection.cursor() self.start() def exit_task(self): self.r = False try: self.join() self.connection.commit() finally: self.cursor.close() self.connection.close() def run(self): while self.r or not self.queue.empty(): try: _task = self.queue.get(timeout=1) except Empty: continue try: if _task[1]: self.cursor.executemany(_task[0], _task[1]) else: self.cursor.execute(_task[0]) self.connection.commit() except Exception as e: print("{0} -- {1}".format(_task[0], _task[1])) error_log.log_exception(e) def submit_task(self, sql, param): self.queue.put([sql, param]) return self.queue.qsize() class FileDataReader: def __init__(self, root_dir, _line_handler): self.root_dir = root_dir self.line_handler = _line_handler def read_start(self): self.__read_dir(self.root_dir) def __read_dir(self, file_dir): if os.path.isdir(file_dir): for filename in os.listdir(file_dir): path = os.path.join(file_dir, filename) if os.path.isdir(path): self.__read_dir(path) else: self.__read_file(path) else: self.__read_file(file_dir) def __read_file(self, path): print("------------- 文件处理中:{0} -------------".format(path)) file = open(path) line = "" line_num = 0 while True: line_num += 1 try: line = file.readline() except Exception as e: error_log.log_read_error("ERROR:{0} , file = {1} , line_num = {2}".format(e, path, line_num)) if line: line = line.strip() if line: self.line_handler.handle(line) else: break class LineHandler: EMAIL_REGEXP = r"^([\w\.-]+)@([\w\.-]+)\.([\w\.]{2,6})$" # denglinglu | 46eeeb68107c0b8fe54c9d47a8c71d0e | [email protected] | 3681994 R1 = r"^.+\t\|\t[a-z0-9]{32}\t\|\t.+\t\|\t\t.+$" def __init__(self, _error_log, _data_transfer): self.error_log = _error_log self.data_transfer = _data_transfer def handle(self, line): handle = False separator = "" for s in separators: if s in line: separator = s break if separator: if separator == "," and line.endswith(","): line = line[0:-1] if separator == "----" and line.endswith("----"): line = line[0:-4] if re.match(LineHandler.R1, line): line = line.replace("\t|\t\t", "\t").replace("\t|\t", "\t") arr = line.split(separator) length = len(arr) if length == 2: handle = True self.handle_split_2(arr[0].strip(), arr[1].strip(), line) elif length == 3: handle = True self.handle_split_3(arr[0].strip(), arr[1].strip(), arr[2].strip(), line) elif length == 4: handle = True self.handle_split_4(arr[0].strip(), arr[1].strip(), arr[2].strip(), arr[3].strip(), line, separator) elif length == 5: handle = True self.handle_split_5(arr[0].strip(), arr[1].strip(), arr[2].strip(), arr[3].strip(), arr[4].strip(), line, separator) if not handle: # 太短或太长的行 直接吞掉 if 10 <= len(line) < 200: error_log.log_format_error(line) def handle_split_2(self, word1, word2, line): password = word2 if "@" in word1: # [email protected] 对应这种情况 ---- 邮箱-密码 account_type = self.split_email(word1) if not account_type: self.error_log.log_email_format_error(line) return account = account_type[0] email_type = account_type[1] self.post(account, password, email_type, None, line) else: # ls407994769----407994769 对应这种情况 ---- 账号-密码 # [email protected] 要排除这种脏数据 account = word1 if "@" in password: self.error_log.log_format_error(line) return self.post(account, password, None, None, line) def handle_split_3(self, word1, word2, word3, line): # 昵称 -- 密码 -- 邮箱 # [email protected] 对应这种 password = word2 remark = word1 account_type = self.split_email(word3) if not account_type: self.error_log.log_email_format_error(line) return account = account_type[0] email_type = account_type[1] self.post(account, password, email_type, remark, line) def handle_split_4(self, word1, word2, word3, word4, line, separator): if word1 and word2 and word3 and word4: if "@" in word2 and len(word3) == 32: # 昵称 -- 邮箱 -- MD5 -- 密码 # zqzsky12345----zqzsky1@163.com----e10adc3949ba59abbe56e057f20f883e----123456 对应这种 password = word4 remark = word1 + "--" + word3 account_type = self.split_email(word2) if not account_type: self.error_log.log_email_format_error(line) return account = account_type[0] email_type = account_type[1] self.post(account, password, email_type, remark, line) elif len(word2) == 32 and "@" in word3: # 昵称 -- MD5 -- 邮箱 -- 密码 # zqzsky12345----zqzsky1@163.com----e10adc3949ba59abbe56e057f20f883e----123456 对应这种 password = word4 remark = word1 + "--" + word2 account_type = self.split_email(word3) if not account_type: self.error_log.log_email_format_error(line) return account = account_type[0] email_type = account_type[1] self.post(account, password, email_type, remark, line) else: self.error_log.log_format_error(line) elif separator == "\t" and word1 and word2 and not word3 and word4: # 昵称 -- 邮箱 -- 空 -- 密码 # [email protected] ----6021159 password = word4 remark = word1 account_type = self.split_email(word2) if not account_type: self.error_log.log_email_format_error(line) return account = account_type[0] email_type = account_type[1] self.post(account, password, email_type, remark, line) else: self.error_log.log_format_error(line) def handle_split_5(self, word1, word2, word3, word4, word5, line, separator): if separator == "\t" and word1 and word2 and word3 and not word4 and word5: # 昵称 -- MD5 -- 邮箱 -- 空 -- 密码 # libing879768 056094b080db1e3062a35a8a588079f5 [email protected] libing 对应这种 if len(word2) != 32: self.error_log.log_format_error(line) return password = word5 remark = word1 + "--" + word2 account_type = self.split_email(word3) if not account_type: self.error_log.log_email_format_error(line) return account = account_type[0] email_type = account_type[1] self.post(account, password, email_type, remark, line) else: self.error_log.log_format_error(line) def post(self, account, password, email_type, remark, line): if not self.valid_account(account): self.error_log.log_account_length_error(line) return if not self.valid_password(password): self.error_log.log_password_length_error(line) return if not self.valid_email_type(email_type): self.error_log.log_email_type_length_error(line) return if not self.valid_remark(remark): self.error_log.log_remark_length_error(line) return self.data_transfer.transfer_data(account, password, email_type, remark) def split_email(self, email): if re.match(LineHandler.EMAIL_REGEXP, email): arr = email.split("@") # 因为数据中 163.com 和 126.com 是最多的,所以,省一点是一点 if arr[1] == "163.com" or arr[1] == "163.COM": email_type = "163" elif arr[1] == "126.com" or arr[1] == "126.COM": email_type = "126" else: email_type = arr[1] return [arr[0], email_type] else: return None def valid_account(self, account): # 邮箱账号长度限制在 2 -- 40 return account and 2 <= len(account) <= 40 def valid_password(self, password): # 密码长度限制在 6 -- 40 return password and 6 <= len(password) <= 40 def valid_email_type(self, email_type): # 邮箱类型长度限制在 3 -- 40 return not email_type or 3 <= len(email_type) <= 40 def valid_remark(self, remark): # 备注长度限制在 3 -- 20 return not remark or len(remark) <= 100 class DataErrorLog: READ_ERROR = "read_error" FORMAT_ERROR = "format_error" EMAIL_FORMAT_ERROR = "email_format_error" ACCOUNT_LENGTH_ERROR = "account_length_error" PASSWORD_LENGTH_ERROR = "password_length_error" EMAIL_TYPE_LENGTH_ERROR = "email_type_length_error" REMARK_LENGTH_ERROR = "remark_length_error" DB_ERROR = "db_error" EXCEPTION = "exception" def __init__(self, log_dir): self.log_dir = log_dir if not os.path.exists(log_dir): os.makedirs(log_dir) if not os.path.isdir(log_dir): os.remove(log_dir) os.makedirs(log_dir) self.__read_error_handler = ErrorLogHandler(log_dir, DataErrorLog.READ_ERROR) self.__format_error_handler = ErrorLogHandler(log_dir, DataErrorLog.FORMAT_ERROR) self.__email_format_error_handler = ErrorLogHandler(log_dir, DataErrorLog.EMAIL_FORMAT_ERROR) self.__account_length_error_handler = ErrorLogHandler(log_dir, DataErrorLog.ACCOUNT_LENGTH_ERROR) self.__password_length_error_handler = ErrorLogHandler(log_dir, DataErrorLog.PASSWORD_LENGTH_ERROR) self.__email_type_length_error_handler = ErrorLogHandler(log_dir, DataErrorLog.EMAIL_TYPE_LENGTH_ERROR) self.__remark_length_error_handler = ErrorLogHandler(log_dir, DataErrorLog.REMARK_LENGTH_ERROR) self.__db_error_handler = ErrorLogHandler(log_dir, DataErrorLog.DB_ERROR) self.__exception_handler = ErrorLogHandler(log_dir, DataErrorLog.EXCEPTION) def log_read_error(self, error): self.__read_error_handler.handle_log(error) def log_format_error(self, error): self.__format_error_handler.handle_log(error) def log_email_format_error(self, error): self.__email_format_error_handler.handle_log(error) def log_account_length_error(self, error): self.__account_length_error_handler.handle_log(error) def log_password_length_error(self, error): self.__password_length_error_handler.handle_log(error) def log_email_type_length_error(self, error): self.__email_type_length_error_handler.handle_log(error) def log_remark_length_error(self, error): self.__remark_length_error_handler.handle_log(error) def log_db_error(self, error): self.__db_error_handler.handle_log(error) def log_exception(self, e): text = "{0}:{1}".format(time.strftime('%H:%M:%S', time.localtime(time.time())), e) self.__exception_handler.handle_log(text) print(text) def close(self): self.__read_error_handler.close() self.__format_error_handler.close() self.__email_format_error_handler.close() self.__account_length_error_handler.close() self.__password_length_error_handler.close() self.__email_type_length_error_handler.close() self.__remark_length_error_handler.close() self.__db_error_handler.close() self.__exception_handler.close() class ErrorLogHandler: MAX_FILE_LINE = max_log_line_num def __init__(self, dir_path, name): self.file_count = 0 self.line_count = 0 self.total_line_count = 0 self.dir_path = dir_path self.name = name self.file = None def handle_log(self, log): if not self.file or self.line_count >= ErrorLogHandler.MAX_FILE_LINE: self.file_count = self.file_count + 1 self.line_count = 0 self.file = self.__new_file("{0}_{1}".format(self.name, self.file_count)) print(log, file=self.file) self.line_count = self.line_count + 1 self.total_line_count = self.total_line_count + 1 def __new_file(self, filename): self.close() p = os.path.join(self.dir_path, filename) if os.path.exists(p): os.remove(p) print("********** 创建日志文件:{0} **********".format(p)) return open(p, 'a') def close(self): if self.file: self.file.close() start = int(round(time.time() * 1000)) print("############## buf_size = {0} ##############".format(buf_size)) print("############## queue_size = {0} ##############".format(queue_size)) print("############## table_name = {0} ##############".format(table_name)) print("############## max_log_line_num = {0} ##############".format(max_log_line_num)) print("############## error_log_dir = {0} ##############".format(error_log_dir)) print("############## data_file_path = {0} ##############".format(data_file_path)) print("############## separators = {0} ##############".format(separators)) data_submit = DataSubmit(connection) data_transfer = DataTransfer(data_submit) error_log = DataErrorLog(error_log_dir) line_handler = LineHandler(error_log, data_transfer) file_data_reader = FileDataReader(data_file_path, line_handler) try: file_data_reader.read_start() data_transfer.flush() finally: data_submit.exit_task() error_log.close() end = int(round(time.time() * 1000)) ms = end - start hh = int(ms / (60 * 60 * 1000)) mm = int((ms % (60 * 60 * 1000)) / (60 * 1000)) ss = int(((ms % (60 * 60 * 1000)) % (60 * 1000)) / 1000) print("\n 处理完成,用时 {0}时 {1}分 {2}秒 \n".format(hh, mm, ss))
修改下文件位置,就可以跑起来了。注意,跑之前,mysql 所在分区至少预留 100G的空间,并且,关闭mysql日志功能。否则,根本就没法用。
buf_size 数值不要设置过大,不然分分钟就爆内存。
思路很简单,一行一行的读,分析出账号密码,其他信息当做备注,然后入库。源数据格式不统一,趟了好几次坑之后,才摸清大概的几种格式。
读数据是很快的,分析数据也不是性能瓶颈。性能瓶颈在mysql入库,所以单独起了个线程用来入库,保证全部时间都在入库,不让分析数据占用时间。
如果内存足够,可以把buf_size放大点,一次入库多点,可以提升效率。
由于数据量实在太大,将邮箱账号按长度分表,如 8 个字符的账号 存入表 email_8 。光分长度,数据量还是太大,查询效率太低,所以,又分了首字母,具体就看代码吧。
源数据当中,有部分是脏数据,没法处理,或者需要手动修改后才能处理,统一都保存至错误文件里面。
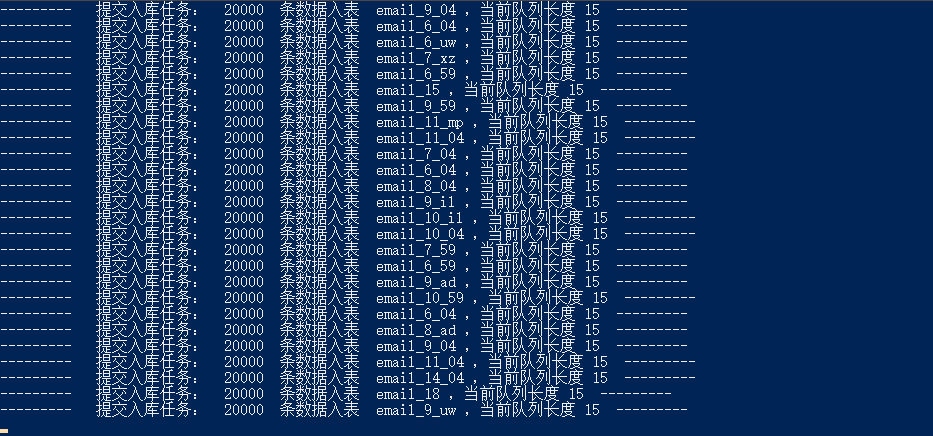
入库之后,生成的表太多了,手工没法使用,所以,还需要个存储过程:
DELIMITER $$ CREATE DEFINER=`root`@`localhost` PROCEDURE `query_account`(IN account_in varchar(255)) BEGIN declare t varchar(255); # 表前缀 declare t_name varchar(255); # 表名称 declare account_len int; # 输入要查询的账号长度 declare fw varchar(10); declare fw_ascii int; set t = "email_"; acc:BEGIN if account_in is null then leave acc; end if; set account_in = trim(account_in); set account_len = length(account_in); if account_len < 2 or account_len > 40 then leave acc; end if; if account_len >= 6 and account_len <= 14 then BEGIN set fw = lower( left(account_in, 1) ); set fw_ascii = ord(fw); if fw_ascii >= 48 and fw_ascii <=52 then set fw = "04"; elseif fw_ascii >= 53 and fw_ascii <=57 then set fw = "59"; elseif fw_ascii >= 97 and fw_ascii <=100 then set fw = "ad"; elseif fw_ascii >= 101 and fw_ascii <=104 then set fw = "eh"; elseif fw_ascii >= 105 and fw_ascii <=108 then set fw = "il"; elseif fw_ascii >= 109 and fw_ascii <=112 then set fw = "mp"; elseif fw_ascii >= 113 and fw_ascii <=116 then set fw = "qt"; elseif fw_ascii >= 117 and fw_ascii <=119 then set fw = "uw"; elseif fw_ascii >= 120 and fw_ascii <=122 then set fw = "xz"; else set fw = "00"; end if; set t_name = concat(t, account_len, "_", fw); END; else set t_name = concat(t, account_len); end if; set @v_sql=concat('select * from ', t_name, ' where email = ?'); prepare stmt from @v_sql; SET @a = account_in; EXECUTE stmt USING @a; deallocate prepare stmt; END acc; END$$ DELIMITER ;
存储过程使用方法:
call query_account('helloworld')