关键词:blktrace、blk tracer、blkparse、block traceevents、BIO。
本章只做一个记录,关于优化Block层IO性能方法工具。
对Block层没有详细分析,对工作的使用和结果分析也没有展开。
如果有合适的机会补充。
1. blktrace介绍
如下图可知整个Block I/O框架可以分为三层:VFS、Block和I/O设备驱动。
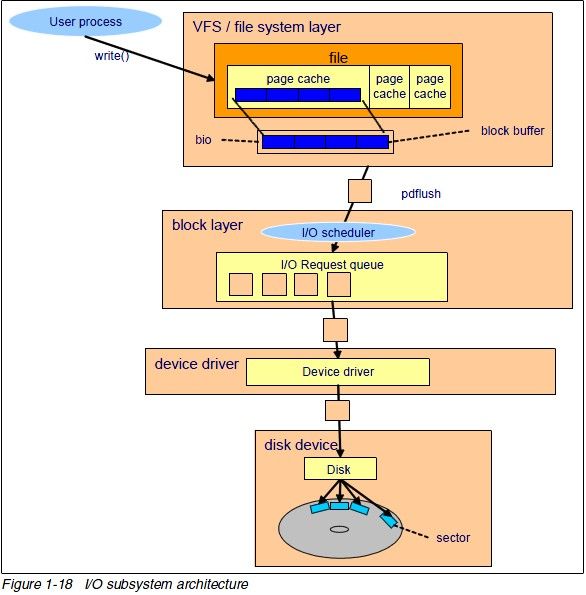
Linux内核中提供了跟踪Block层操作的手段,可以通过blk跟踪器、或者使用blktrace/blkparse/btt工具抓取分析、或者使用block相关trace events记录。
2. blk跟踪器分析
blk跟踪器作为Linux ftrace的一个跟踪器,主要跟踪Linux Block层相关操作。
2.1 使用blk跟踪器
执行脚本sh blk_tracer.sh 4k 512 fsync,抓取相关case。
#!/bin/bash
echo $1 $2 $3
#Prepare for the test
echo 1 > /sys/block/mmcblk0/trace/enable
echo 0 > /sys/kernel/debug/tracing/tracing_on
echo 0 > /sys/kernel/debug/tracing/events/enableecho 10000 > /sys/kernel/debug/tracing/buffer_size_kb
echo blk > /sys/kernel/debug/tracing/current_tracerecho 1 > /sys/kernel/debug/tracing/tracing_on
#Run the test case
if [ $3 = 'fsync' ]; then
dd bs=$1 count=$2 if=/dev/zero of=out_empty conv=fsync
else
dd bs=$1 count=$2 if=/dev/zero of=out_empty
fi#Capture the test log
echo 0 > /sys/kernel/debug/tracing/tracing_on
echo 0 > /sys/block/mmcblk0/trace/enable
cat /sys/kernel/debug/tracing/trace > test_$1_$2_$3.txt
echo nop > /sys/kernel/debug/tracing/current_tracer
echo > /sys/kernel/debug/tracing/trace
2.2 注册blk跟踪器
首先register_tracer向ftrace注册blk跟踪器,然后打印核心函数是blk_tracer_print_line。
static int __init init_blk_tracer(void) { ... if (register_tracer(&blk_tracer) != 0) { pr_warning("Warning: could not register the block tracer\n"); unregister_ftrace_event(&trace_blk_event); return 1; } return 0; } static struct tracer blk_tracer __read_mostly = { .name = "blk", .init = blk_tracer_init, .reset = blk_tracer_reset, .start = blk_tracer_start, .stop = blk_tracer_stop, .print_header = blk_tracer_print_header, .print_line = blk_tracer_print_line, .flags = &blk_tracer_flags, .set_flag = blk_tracer_set_flag, }; static enum print_line_t blk_tracer_print_line(struct trace_iterator *iter) { if (!(blk_tracer_flags.val & TRACE_BLK_OPT_CLASSIC)) return TRACE_TYPE_UNHANDLED; return print_one_line(iter, true); }
print_one_line是打印的核心,这里最主要是根据当前struct blk_io_trace->action选择合适的打印函数。
static enum print_line_t print_one_line(struct trace_iterator *iter, bool classic) { struct trace_seq *s = &iter->seq; const struct blk_io_trace *t; u16 what; int ret; bool long_act; blk_log_action_t *log_action; t = te_blk_io_trace(iter->ent); what = t->action & ((1 << BLK_TC_SHIFT) - 1);-------------------------------what表示是什么操作类型? long_act = !!(trace_flags & TRACE_ITER_VERBOSE); log_action = classic ? &blk_log_action_classic : &blk_log_action; if (t->action == BLK_TN_MESSAGE) { ret = log_action(iter, long_act ? "message" : "m"); if (ret) ret = blk_log_msg(s, iter->ent); goto out; } if (unlikely(what == 0 || what >= ARRAY_SIZE(what2act)))---------------------------what为0表示未知操作类型 ret = trace_seq_printf(s, "Unknown action %x\n", what); else { ret = log_action(iter, what2act[what].act[long_act]);--------------------------首先调用blk_long_action_classic或者blk_long_action打印 if (ret) ret = what2act[what].print(s, iter->ent);----------------------------------然后在调用具体action对应的但因函数打印细节。 } out: return ret ? TRACE_TYPE_HANDLED : TRACE_TYPE_PARTIAL_LINE; } static const struct { const char *act[2]; int (*print)(struct trace_seq *s, const struct trace_entry *ent); } what2act[] = { [__BLK_TA_QUEUE] = {{ "Q", "queue" }, blk_log_generic }, [__BLK_TA_BACKMERGE] = {{ "M", "backmerge" }, blk_log_generic }, [__BLK_TA_FRONTMERGE] = {{ "F", "frontmerge" }, blk_log_generic }, [__BLK_TA_GETRQ] = {{ "G", "getrq" }, blk_log_generic }, [__BLK_TA_SLEEPRQ] = {{ "S", "sleeprq" }, blk_log_generic }, [__BLK_TA_REQUEUE] = {{ "R", "requeue" }, blk_log_with_error }, [__BLK_TA_ISSUE] = {{ "D", "issue" }, blk_log_generic }, [__BLK_TA_COMPLETE] = {{ "C", "complete" }, blk_log_with_error }, [__BLK_TA_PLUG] = {{ "P", "plug" }, blk_log_plug }, [__BLK_TA_UNPLUG_IO] = {{ "U", "unplug_io" }, blk_log_unplug }, [__BLK_TA_UNPLUG_TIMER] = {{ "UT", "unplug_timer" }, blk_log_unplug }, [__BLK_TA_INSERT] = {{ "I", "insert" }, blk_log_generic }, [__BLK_TA_SPLIT] = {{ "X", "split" }, blk_log_split }, [__BLK_TA_BOUNCE] = {{ "B", "bounce" }, blk_log_generic }, [__BLK_TA_REMAP] = {{ "A", "remap" }, blk_log_remap }, }
从fill_rwbs()可知,RWBS之类的字符表示读写类型,W-BLK_TC_WRITE、S-BLK_TC_SYNC、R-BLK_TC_READ、N-BLK_TN_MESSAGE等等。
结合what2act可知当前当前打印的确切含义,结合打印函数,可知其大概含义。
dd-844 [000] .... 1540.751312: 179,0 Q WS 32800 + 1 [dd]---------------Q-queue操作,WS-写同步,blk_log_generic打印-磁盘偏移量+写sector数目 [进程名] dd-844 [000] .... 1540.751312: 179,0 G WS 32800 + 1 [dd]---------------G-getrq操作 dd-844 [000] .... 1540.751312: 179,0 I WS 32800 + 1 [dd] dd-844 [000] .... 1540.753937: 179,0 P N [dd]-------------------------P-plug操作,N-BLK_TN_MESSAGE dd-844 [000] .... 1540.753937: 179,0 A WS 18079 + 1 <- (179,1) 18047 dd-844 [000] .... 1540.753937: 179,0 Q WS 18079 + 1 [dd] dd-844 [000] .... 1540.753967: 179,0 G WS 18079 + 1 [dd] dd-844 [000] .... 1540.753967: 179,0 I WS 2863 + 1 [dd] dd-844 [000] .... 1540.753967: 179,0 I WS 18079 + 1 [dd] dd-844 [000] .... 1540.753967: 179,0 U N [dd] 2------------------------U-unplug_io操作, mmcqd/0-673 [000] .... 1540.753967: 179,0 D WS 2863 + 1 [mmcqd/0] mmcqd/0-673 [000] .... 1540.753998: 179,0 D WS 18079 + 1 [mmcqd/0] mmcqd/0-673 [000] .... 1540.757690: 179,0 C WS 2863 + 1 [0] mmcqd/0-673 [000] .... 1540.760681: 179,0 C WS 18079 + 1 [0] dd-844 [000] .... 1540.760742: 179,0 A R 2864 + 1 <- (179,1) 2832------A-remap操作,读取偏移量+读取sect数 <-源设备主从设备号 源设备偏移量
3.blktrace使用及原理
blktrace是针对Linux内核中Block I/O的跟踪工具,属于内核Block Layer。
通过这个工具可以获得I/O请求队列的详细情况,包括读写进程名、进程号、执行时间、读写物理块号、块大小等等。
PS:代码是LInux 3.4.110,但是试验在Ubuntu Kernel 4.4.0-31进行。
3.1 blktrace的使用
安装blktrace
sudo apt-get install blktrace
blktrace用于抓取Block I/O相关的log,blkparse用于分析blktrace抓取的二进制log。通过btt也可以用blktrace抓取的二进制log。
sudo blktrace -d /dev/sda6 -o - | blkparse -i -
或者分开使用
sudo blktrace -d /dev/sda6 -o sda6 #生成sda6.blktrace.x文件
blkparse -i sda6.blktrace.* -o sda6.txt
btt -i sda6.blktrace.*
3.2 blktrace原理
1. blktrace在运行的时候会在/sys/kernel/debug/block下面设备名称对应的目录,并生成四个文件droppeed/msg/trace0/trace2。
2. blktrace通过ioctl对内核进行设置,从而抓取log。
3. blktrace针对系统每个CPU绑定一个线程来收集相应数据。
3.2.1 Block设备blktrace相关节点
使用strace跟中blktrace执行流程可以看出:打开/dev/sda6设备,然后通过ioctl发送BLKTRACESETUP和BLKTRACESTART。
open("/dev/sda6", O_RDONLY|O_NONBLOCK) = 3 statfs("/sys/kernel/debug", {f_type=0x64626720, f_bsize=4096, f_blocks=0, f_bfree=0, f_bavail=0, f_files=0, f_ffree=0, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0... ioctl(3, BLKTRACESETUP, {act_mask=65535, buf_size=524288, buf_nr=4, start_lba=0, end_lba=0, pid=0}, {name="sda6"}) = 0... ioctl(3, BLKTRACESTART, 0x608c20) = 0
下面通过走查代码简单分析流程。
add_disk() ->blk_register_queue() ->blk_trace_init_sysfs() ->blk_trace_attr_group ->blk_trace_attrs
如果定义了CONFIG_BLK_DEV_IO_TRACE,会在/sys/block/sda/sda6下创建一个trace目录。执行blktrace可以打开enable。
3.2.2 Block设备ioctl相关命令
ioctl通过/dev/sda6设置进去,可以看一下ioctl代码流程。
def_blk_fops ->unlocked_ioctl = block_ioctl ->blkdev_ioctl ->BLKTRACESTART/BLKTRACESTOP/BLKTRACESETUPBLKTRACETEARDOWN ->blk_trace_ioctl
blk_trace_ioctl处理BLKTRACESETUP/BLKTRACESTART/BLKTRACESTOP/BLKTRACETEARDOWN四种情况,分别表示配置、开始、停止、释放资源。
int blk_trace_ioctl(struct block_device *bdev, unsigned cmd, char __user *arg) { struct request_queue *q; int ret, start = 0; char b[BDEVNAME_SIZE]; q = bdev_get_queue(bdev); if (!q) return -ENXIO; mutex_lock(&bdev->bd_mutex); switch (cmd) { case BLKTRACESETUP: bdevname(bdev, b); ret = blk_trace_setup(q, b, bdev->bd_dev, bdev, arg); break; #if defined(CONFIG_COMPAT) && defined(CONFIG_X86_64) case BLKTRACESETUP32: bdevname(bdev, b); ret = compat_blk_trace_setup(q, b, bdev->bd_dev, bdev, arg); break; #endif case BLKTRACESTART: start = 1; case BLKTRACESTOP: ret = blk_trace_startstop(q, start); break; case BLKTRACETEARDOWN: ret = blk_trace_remove(q); break; default: ret = -ENOTTY; break; } mutex_unlock(&bdev->bd_mutex); return ret; }
int blk_trace_setup(struct request_queue *q, char *name, dev_t dev, struct block_device *bdev, char __user *arg) { struct blk_user_trace_setup buts; int ret; ret = copy_from_user(&buts, arg, sizeof(buts)); if (ret) return -EFAULT; ret = do_blk_trace_setup(q, name, dev, bdev, &buts); if (ret) return ret; if (copy_to_user(arg, &buts, sizeof(buts))) { blk_trace_remove(q); return -EFAULT; } return 0; } int do_blk_trace_setup(struct request_queue *q, char *name, dev_t dev, struct block_device *bdev, struct blk_user_trace_setup *buts) { struct blk_trace *old_bt, *bt = NULL; struct dentry *dir = NULL; int ret, i; ... bt = kzalloc(sizeof(*bt), GFP_KERNEL); if (!bt) return -ENOMEM; ret = -ENOMEM; bt->sequence = alloc_percpu(unsigned long); if (!bt->sequence) goto err; bt->msg_data = __alloc_percpu(BLK_TN_MAX_MSG, __alignof__(char)); if (!bt->msg_data) goto err; ret = -ENOENT; mutex_lock(&blk_tree_mutex); if (!blk_tree_root) { blk_tree_root = debugfs_create_dir("block", NULL);-------------------创建/sys/kernel/debug/block目录 if (!blk_tree_root) { mutex_unlock(&blk_tree_mutex); goto err; } } mutex_unlock(&blk_tree_mutex); dir = debugfs_create_dir(buts->name, blk_tree_root);---------------------在/sys/kernel/debug/block目录下创建设备名称对应目录 if (!dir) goto err; bt->dir = dir; bt->dev = dev; atomic_set(&bt->dropped, 0); ret = -EIO; bt->dropped_file = debugfs_create_file("dropped", 0444, dir, bt, &blk_dropped_fops);--------------------------------在/sys/kernel/debug/block/sda6下创建dropped节点 if (!bt->dropped_file) goto err; bt->msg_file = debugfs_create_file("msg", 0222, dir, bt, &blk_msg_fops); if (!bt->msg_file) goto err; bt->rchan = relay_open("trace", dir, buts->buf_size, buts->buf_nr, &blk_relay_callbacks, bt);----------------------为每个CPU创建/sys/kernel/debug/block/sda6/tracex对应额relay channel ... if (atomic_inc_return(&blk_probes_ref) == 1) blk_register_tracepoints();-------------------------------------------注册和/sys/kernel/debug/tracing/events/block下同样的trace events。 return 0; err: blk_trace_free(bt); return ret; }
blk_trace_startstop执行blktrace的开关操作,停止过后将per cpu的relay chanel强制flush出来。
int blk_trace_startstop(struct request_queue *q, int start) { int ret; struct blk_trace *bt = q->blk_trace; ... ret = -EINVAL; if (start) { if (bt->trace_state == Blktrace_setup || bt->trace_state == Blktrace_stopped) { blktrace_seq++; smp_mb(); bt->trace_state = Blktrace_running; trace_note_time(bt); ret = 0; } } else { if (bt->trace_state == Blktrace_running) { bt->trace_state = Blktrace_stopped; relay_flush(bt->rchan); ret = 0; } } return ret; }
释放blktrace设置创建的buffer、删除相关文件节点,并去注册trace events。
int blk_trace_remove(struct request_queue *q) { struct blk_trace *bt; bt = xchg(&q->blk_trace, NULL); if (!bt) return -EINVAL; if (bt->trace_state != Blktrace_running) blk_trace_cleanup(bt); return 0; } static void blk_trace_cleanup(struct blk_trace *bt) { blk_trace_free(bt); if (atomic_dec_and_test(&blk_probes_ref)) blk_unregister_tracepoints(); }
这里的print_one_line和blk跟踪器的打印稍有不同,此处调用blk_log_action打印公共部分信息。
static int __init init_blk_tracer(void) { if (!register_ftrace_event(&trace_blk_event)) { pr_warning("Warning: could not register block events\n"); return 1; } ... } static enum print_line_t blk_trace_event_print(struct trace_iterator *iter, int flags, struct trace_event *event) { return print_one_line(iter, false); }
blk跟踪器使用blk_log_action_classic()打印,两者区别在于blk跟踪器
static int blk_log_action_classic(struct trace_iterator *iter, const char *act) { char rwbs[RWBS_LEN]; unsigned long long ts = iter->ts; unsigned long nsec_rem = do_div(ts, NSEC_PER_SEC); unsigned secs = (unsigned long)ts; const struct blk_io_trace *t = te_blk_io_trace(iter->ent); fill_rwbs(rwbs, t); return trace_seq_printf(&iter->seq, "%3d,%-3d %2d %5d.%09lu %5u %2s %3s ", MAJOR(t->device), MINOR(t->device), iter->cpu, secs, nsec_rem, iter->ent->pid, act, rwbs); } static int blk_log_action(struct trace_iterator *iter, const char *act) { char rwbs[RWBS_LEN]; const struct blk_io_trace *t = te_blk_io_trace(iter->ent); fill_rwbs(rwbs, t); return trace_seq_printf(&iter->seq, "%3d,%-3d %2s %3s ", MAJOR(t->device), MINOR(t->device), act, rwbs); }
3.3 blkparse结果分析
使用blkparse分析blktrace后,得出的结果和blk跟踪器大概类似。
可见实验结果多了第2列CPU序号,和第4列执行的时间戳。
8,6 1 1 0.000000000 173 P N [jbd2/sda1-8] 8,6 1 2 0.000011134 173 U N [jbd2/sda1-8] 1 8,0 1 3 4.000017080 570 A WS 528813240 + 8 <- (8,6) 440921272 8,6 1 4 4.000018315 570 Q WS 528813240 + 8 [jbd2/sda6-8] 8,6 1 5 4.000024476 570 G WS 528813240 + 8 [jbd2/sda6-8] 8,6 1 6 4.000025282 570 P N [jbd2/sda6-8] 8,0 1 7 4.000026610 570 A WS 528813248 + 8 <- (8,6) 440921280 8,6 1 8 4.000026935 570 Q WS 528813248 + 8 [jbd2/sda6-8] 8,6 1 9 4.000028253 570 M WS 528813248 + 8 [jbd2/sda6-8] 8,0 1 10 4.000028895 570 A WS 528813256 + 8 <- (8,6) 440921288 8,6 1 11 4.000029180 570 Q WS 528813256 + 8 [jbd2/sda6-8] 8,6 1 12 4.000029585 570 M WS 528813256 + 8 [jbd2/sda6-8] 8,0 1 13 4.000030182 570 A WS 528813264 + 8 <- (8,6) 440921296 8,6 1 14 4.000030463 570 Q WS 528813264 + 8 [jbd2/sda6-8] 8,6 1 15 4.000030845 570 M WS 528813264 + 8 [jbd2/sda6-8] 8,0 1 16 4.000031406 570 A WS 528813272 + 8 <- (8,6) 440921304 8,6 1 17 4.000031687 570 Q WS 528813272 + 8 [jbd2/sda6-8] 8,6 1 18 4.000032066 570 M WS 528813272 + 8 [jbd2/sda6-8] ... CPU0 (sda6): Reads Queued: 2375, 16816KiB Writes Queued: 909, 4648KiB Read Dispatches: 2329, 16632KiB Write Dispatches: 310, 3876KiB Reads Requeued: 0 Writes Requeued: 15 Reads Completed: 23, 132KiB Writes Completed: 0, 0KiB Read Merges: 27, 108KiB Write Merges: 489, 1960KiB Read depth: 32 Write depth: 31 IO unplugs: 379 Timer unplugs: 0 CPU1 (sda6): Reads Queued: 2737, 12724KiB Writes Queued: 1152, 5080KiB Read Dispatches: 2755, 12908KiB Write Dispatches: 759, 5852KiB Reads Requeued: 0 Writes Requeued: 249 Reads Completed: 5061, 29408KiB Writes Completed: 945, 9728KiB Read Merges: 0, 0KiB Write Merges: 759, 3044KiB Read depth: 32 Write depth: 31 IO unplugs: 212 Timer unplugs: 1 Total (sda6): Reads Queued: 5112, 29540KiB Writes Queued: 2061, 9728KiB Read Dispatches: 5084, 29540KiB Write Dispatches: 1069, 9728KiB Reads Requeued: 0 Writes Requeued: 264 Reads Completed: 5084, 29540KiB Writes Completed: 945, 9728KiB Read Merges: 27, 108KiB Write Merges: 1248, 5004KiB IO unplugs: 591 Timer unplugs: 1 Throughput (R/W): 2KiB/s / 0KiB/s Events (sda6): 41303 entries Skips: 0 forward (0 - 0.0%)
4. block的Traceevents
关于block Traceevents和blk跟踪器的关联,可以通过blk_register_tracepoints()和include/trace/events/block.h中定义的时间关联起来,两者是一一对应的。
block事件打印的信息多了一个字符串,可读性更强一点。比blk跟踪器和blktrace更容易了解含义。
在/sys/kernel/debug/tracing/events/block下,可以分别打开相关事件:
block_bio_backmerge
block_bio_bounce
block_bio_complete
block_bio_frontmerge
block_bio_queue
block_bio_remap
block_getrq
block_plug
block_rq_abort
block_rq_complete
block_rq_insert
block_rq_issue
block_rq_remap
block_rq_requeue
block_sleeprq
block_split
block_unplug
同时根据这些字符串,也容易找出内核中代码位置。
也只有明白了block层流程,以及这些关键事件的log,才能知道问题点在哪里?然后再去进行优化。
# tracer: nop # # entries-in-buffer/entries-written: 14856/14856 #P:1 # # _-----=> irqs-off # / _----=> need-resched # | / _---=> hardirq/softirq # || / _--=> preempt-depth # ||| / delay # TASK-PID CPU# |||| TIMESTAMP FUNCTION # | | | |||| | | dd-955 [000] .... 3287.902618: block_bio_remap: 179,0 W 472280 + 16 <- (179,1) 472248 dd-955 [000] .... 3287.902618: block_bio_queue: 179,0 W 472280 + 16 [dd] dd-955 [000] .... 3287.902649: block_getrq: 179,0 W 472280 + 16 [dd] dd-955 [000] .... 3287.902649: block_plug: [dd] dd-955 [000] d... 3287.902649: block_rq_insert: 179,0 W 0 () 472280 + 16 [dd] dd-955 [000] d... 3287.902679: block_unplug: [dd] 1 mmcqd/0-673 [000] d... 3287.902679: block_rq_issue: 179,0 W 0 () 472280 + 16 [mmcqd/0] mmcqd/0-673 [000] d... 3287.907440: block_rq_complete: 179,0 W () 472280 + 16 [0] dd-955 [000] .... 3287.907501: block_bio_remap: 179,0 WS 32800 + 1 <- (179,1) 32768 dd-955 [000] .... 3287.907501: block_bio_queue: 179,0 WS 32800 + 1 [dd] dd-955 [000] .... 3287.907501: block_getrq: 179,0 WS 32800 + 1 [dd] dd-955 [000] d... 3287.907501: block_rq_insert: 179,0 WS 0 () 32800 + 1 [dd] mmcqd/0-673 [000] d... 3287.907532: block_rq_issue: 179,0 WS 0 () 32800 + 1 [mmcqd/0] mmcqd/0-673 [000] d... 3287.921631: block_rq_complete: 179,0 WS () 32800 + 1 [0] dd-955 [000] .... 3287.921631: block_bio_remap: 179,0 WS 2794 + 1 <- (179,1) 2762 dd-955 [000] .... 3287.921631: block_bio_queue: 179,0 WS 2794 + 1 [dd] dd-955 [000] .... 3287.921631: block_getrq: 179,0 WS 2794 + 1 [dd] dd-955 [000] .... 3287.921661: block_plug: [dd] dd-955 [000] .... 3287.921661: block_bio_remap: 179,0 WS 18010 + 1 <- (179,1) 17978 dd-955 [000] .... 3287.921661: block_bio_queue: 179,0 WS 18010 + 1 [dd] dd-955 [000] .... 3287.921661: block_getrq: 179,0 WS 18010 + 1 [dd] dd-955 [000] .... 3287.921661: block_bio_remap: 179,0 WS 2792 + 1 <- (179,1) 2760 dd-955 [000] .... 3287.921661: block_bio_queue: 179,0 WS 2792 + 1 [dd] dd-955 [000] .... 3287.921661: block_getrq: 179,0 WS 2792 + 1 [dd] dd-955 [000] .... 3287.921661: block_bio_remap: 179,0 WS 18008 + 1 <- (179,1) 17976 dd-955 [000] .... 3287.921661: block_bio_queue: 179,0 WS 18008 + 1 [dd] dd-955 [000] .... 3287.921692: block_getrq: 179,0 WS 18008 + 1 [dd] dd-955 [000] .... 3287.921692: block_bio_remap: 179,0 WS 2797 + 1 <- (179,1) 2765 dd-955 [000] .... 3287.921692: block_bio_queue: 179,0 WS 2797 + 1 [dd] dd-955 [000] .... 3287.921692: block_getrq: 179,0 WS 2797 + 1 [dd] dd-955 [000] .... 3287.921692: block_bio_remap: 179,0 WS 18013 + 1 <- (179,1) 17981 dd-955 [000] .... 3287.921692: block_bio_queue: 179,0 WS 18013 + 1 [dd]
5. 优化尝试
对文件系统性能的调优,主要通过两个目录下节点:/proc/sys/vm和/sys/block/sda/queue。
5.1 更改IO调度算法
echo cfq > /sys/block/sda/queue/scheduler
5.2 修改磁盘相关内核参数
/sys/block/sda/queue/scheduler
/sys/block/sda/queue/nr_requests 磁盘队列长度。默认只有 128 个队列,可以提高到 512 个.会更加占用内存,但能更加多的合并读写操作,速度变慢,但能读写更加多的量
/sys/block/sda/queue/iosched/antic_expire 等待时间 。读取附近产生的新请时等待多长时间
这个参数控制文件系统的文件系统写缓冲区的大小,单位是百分比,表示系统内存的百分比,表示当写缓冲使用到系统内存多少的时候,开始向磁盘写出数 据.增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能.但是,当你需要持续、恒定的写入场合时,应该降低其数值,一般启动上缺省是 10.下面是增大的方法: echo ’40’>
/proc/sys/vm/dirty_background_ratio
这个参数控制文件系统的pdflush进程,在何时刷新磁盘.单位是百分比,表示系统内存的百分比,意思是当写缓冲使用到系统内存多少的时候, pdflush开始向磁盘写出数据.增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能.但是,当你需要持续、恒定的写入场合时,应该降低其数值,一般启动上缺省是 5.下面是增大的方法: echo ’20’ >
/proc/sys/vm/dirty_writeback_centisecs
这个参数控制内核的脏数据刷新进程pdflush的运行间隔.单位是 1/100 秒.缺省数值是500,也就是 5 秒.如果你的系统是持续地写入动作,那么实际上还是降低这个数值比较好,这样可以把尖峰的写操作削平成多次写操作.设置方法如下: echo ‘200’ > /proc/sys/vm/dirty_writeback_centisecs 如果你的系统是短期地尖峰式的写操作,并且写入数据不大(几十M/次)且内存有比较多富裕,那么应该增大此数值: echo ‘1000’ > /proc/sys/vm/dirty_writeback_centisecs
/proc/sys/vm/dirty_expire_centisecs
这个参数声明Linux内核写缓冲区里面的数据多“旧”了之后,pdflush进程就开始考虑写到磁盘中去.单位是 1/100秒.缺省是 30000,也就是 30 秒的数据就算旧了,将会刷新磁盘.对于特别重载的写操作来说,这个值适当缩小也是好的,但也不能缩小太多,因为缩小太多也会导致IO提高太快.建议设置为 1500,也就是15秒算旧. echo ‘1500’ > /proc/sys/vm/dirty_expire_centisecs 当然,如果你的系统内存比较大,并且写入模式是间歇式的,并且每次写入的数据不大(比如几十M),那么这个值还是大些的好.
参考文档
1. Linux IO Scheduler(Linux IO 调度器)
2. Linux文件系统性能优化
3. Linux 性能优化之 IO 子系统