1、FM的原理
1.1 FM介绍及其优缺点
FM就是因子分解机。通过不同组合不同的特征,解决推荐系统中数据稀疏的问题。
FM模型吸收了支持向量机和矩阵分解模型的优点,使用特征项隐含向量训练获得预测模型。此模型可以用于评分预测,点击率预测。使用分解因子对所有变量间的二阶相互作用进行建模,能够很好的处理数据稀疏情况下各个变量间的相互作用。
缺点是对不同特征进行特征组合,没有考虑有些特征是属于同一个领域的,二是只考虑到二阶特征组合,并没有对高阶的特征组进行建模。
1.2 FM算法原理
1.2.1 首先对特征进行one-hot编码
FM模型为了解决推荐用户-项目数据稀疏的情况下,各个特征组合的问题,以电视节目点击为例,用户对什么电视节目感兴趣,并预测是否会点击。
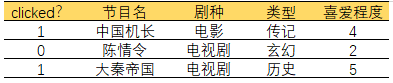
clicked?用0,1表示,表明用户会不会点击此节目,0表示不会点击,1表示会点击。“节目名”,“剧种”,和“类型”是分类特征,这种分类特征会使用one-hot进行编码,如果特征的结果中有连续变量,那么此变量就是原来的值。编码结果如下表:

因为“节目名”,“剧种”,“类型”是categorical特征,所以经过one-hot编码以后,矩阵会变得非常稀疏,如上图所示,0出现的位置非常的多,比如在用户和物品类别非常多的情况下,矩阵会非常非常的稀疏,所作的特征工程会非常的大。
1.2.2 对特征进行组合(二阶组合)
FM的是在线性回归的基础上发展而来的,因为线性回归只是考虑的一阶特征的情况,但是大量的特征之间是有一定的联系的,也就是说组合特征也会对预测的结果产生影响,比如女生就比较喜欢看言情、家庭剧,男生喜欢看历史、推理题材的剧。显然,用户的性别和喜欢看的剧的种类是有相当大的关联的,因此在预测用户点击率的时候把组合特征考虑在内是非常有必要的。
1)线性模型
线性模型没有考虑到特征之间组合的关系,而FM模型考虑到二阶特征组合因此需要在线性模型的基础上加入一个二阶组合,相当于一个二阶多项式,其二阶表达式为,加入二阶表达式就可以引出FM的模型表达式。
2)FM模型公式
其中n表示one-hot编码后特征的个数,比如上边的例子中,特征个数n=9,和表示第i和第j个特征的值,也就是说,,因为特征矩阵非常的稀疏,因此相乘很大可能结果为0,从而权重很大程度上也会为0,为了学习得到权重,吸收了MF矩阵分解的原理,使,其中就是特征i和特征j的隐含向量,为点积,公式为,k为隐含向量的维度,从而把FM模型公式改为如下所示:
其中根据论文交叉项展开推导
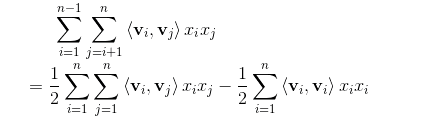
下边为这个交叉项推导详细解释:
假设特征经过one-hot编码后有3维度特征,,,根据论文所说,特征矩阵的非常稀疏,由此隐含向量的取值k基本取比较小的值就可以拟合了,因此在此例子中选取了k=3,假设隐含向量,,,所以
其中i为特征数,k为隐向量维度,所以
根据上述w与x相乘,可得到
因此

3)FM的作用:回归,二分类
回归:直接预测数值,并使用均方误差作为损失函数,可加入正则化L2,来防止过拟合,并最小化损失函数。
损失函数:
使用随机梯度下降进行优化,其偏导为:
二分类:最后的结果经过一个sigmoid函数,并使用交叉熵作为损失函数,并最小化损失函数。
损失函数:
其中为sigmoid函数其表达式为
因此其偏导为:
的公式如下图所示
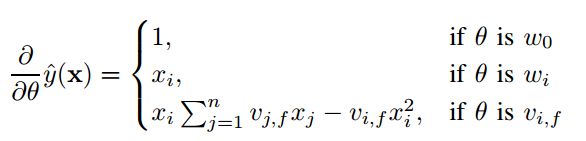
2、FM代码实现
实验使用了movielens的100k的数据集,是评分预测的实验,因此采用的损失函数为均方误差。
2.1 numpy实现
numpy的实现只是便于理解FM模型公式具体是怎么运作的,实验采用了网上的数据集,截取了其中的5个样本进行测试,其中有8个特征,都是连续变量,因此不需要对数据做one-hot编码。
实现的模型代码:
import numpy as np
from random import normalvariate
data = np.array([[6,148,72,35,0,33.6,0.627,50],[1,85,66,29,0,26.6,0.351,31],
[8,183,64,0,0,23.3,0.672,32],[1,89,66,23,94,28.1,0.167,21],
[0,137,40,35,168,43.1,2.288,33]])
label=np.array([1,0,1,0,1])
def sigmoid(inx):
return 1.0 / (1 + np.exp(-inx))
def fit(data,alpha=0.01,k=3,iter_num=5):
'''alpha为学习率,k为v的隐特征数,iter_num为迭代次数
初始化所需要的参数'''
m,n = data.shape #m为样本个数,n为特征个数
w = np.zeros(n)
w_0 = 0.
v = normalvariate(0, 0.2) * np.ones((n, k))
for it in range(iter_num):
for x in range(m):
'''前向传播得到预测值'''
inter_1 = data[x].dot(v)
inter_2 = np.multiply(data[x],data[x]).dot((np.multiply(v,v)))
interaction =np.sum(inter_1*inter_1-inter_2)/2
p = w_0+ w.dot(data[x])+interaction
print('预测值:',p)
'''损失函数'''
loss = sigmoid(label[x]*p)-1
'''随机梯度下降,得到各个权重'''
w_0 = w_0 - alpha*loss*label[0]
for i in range(n):
if data[x, i] != 0:
w[i] = w[i] - alpha*loss*label[0]*data[0][i]
for j in range(k):
v[i,j]=v[i,j]-alpha*loss*label[0]*(data[0][i]*(inter_1[j])-v[i,j]*data[0][i]*data[0][i])
return w_0,w,v
2.2 tensorflow实现
本方法在特征数量较小的情况下可以进行one-hot对特征进行处理,当特征数量较大的时候,由于计算机内存的限制,可以使用embedding_lookup的方法寻找隐含向量,具体步骤可以参考DeepFM的方法
方法一:
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
cols = ['user', 'item', 'rating', 'timestamp']
train = pd.read_csv('D:/recsys/DeepMF/Data/ml-100k/ua.base', delimiter='\t', names=cols,converters={'user':str,'item':str})
test = pd.read_csv('D:/recsys/DeepMF/Data/ml-100k/ua.test', delimiter='\t', names=cols,converters={'user':str,'item':str})
train = train.drop(['timestamp'], axis=1)
test = test.drop(['timestamp'], axis=1)
df_x_train = train[['user','item']]
df_x_test = test[['user','item']]
df_zong = pd.concat([df_x_train,df_x_test])
y_train = train['rating'].values.reshape(-1,1)
y_test = test['rating'].values.reshape(-1,1)
vec = DictVectorizer()
vec.fit_transform(df_zong.to_dict(orient='record'))
del df_zong
x_train = vec.transform(df_x_train.to_dict(orient='record')).toarray()
x_test = vec.transform(df_x_test.to_dict(orient='record')).toarray()
print("x_train shape", x_train.shape)
print("x_test shape", x_test.shape)
k=8
learning_rate=0.05
l2_w = 0.001
l2_v = 0.001
epoch=20
m,n = x_train.shape
print(m,n)
x = tf.placeholder(tf.float32,[None,n],name='feature')
y = tf.placeholder(tf.float32,[None,1],name='label')
'''初始化参数'''
w_0 = tf.Variable(tf.zeros([1]))
w = tf.Variable(tf.random_normal([n], mean=0, stddev=0.01))
v = tf.Variable(tf.random_normal([k,n],mean=0,stddev=0.01))
'''前向传播'''
#---------first order---------
first_order = tf.reduce_sum(tf.multiply(w,x),axis=1,keepdims=True)
liner = tf.add(w_0,first_order) # None*1
#---------second order---------
mul_square = tf.pow(tf.matmul(x,tf.transpose(v)),2) #None * n
squqre_mul = tf.matmul(tf.pow(x,2),tf.transpose(tf.pow(v,2))) #None * n
second_order = 0.5* tf.reduce_sum(tf.subtract(mul_square,squqre_mul),1,keepdims=True) # None * 1
#---------FM Model的预测值---------
fm_model = tf.add(liner,second_order) # None * 1
'''损失函数'''
loss = tf.reduce_mean(tf.square(fm_model-y))
l2_norm = tf.reduce_sum(l2_w * tf.square(w)+ l2_v * tf.square(v))
losses = tf.add(loss,l2_norm)
'''随机梯度下降'''
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(losses)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for step in range(epoch):
tmp_loss,_ = sess.run([losses,train_op],feed_dict={x:x_train,y:y_train})
validate_loss = sess.run(loss, feed_dict={x: x_test, y: y_test})
print("epoch:%d train loss:%f validate_loss:%f" %
(step, tmp_loss, validate_loss))
rmse = sess.run(loss, feed_dict={x: x_test, y: y_test})
RMSE = np.sqrt(rmse)
print("rmse:", RMSE)
predict = sess.run(fm_model, feed_dict={x: x_test})
print("predict:", predict)
由于自己的数据集的特征数量多,使用方法一跑数据集会出现memory error的错误,因此根据DeepFM的代码改写了FM数据预处理的部分,给特征建一个字典、
方法二:
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
def get_feature_dict(df,num_col):
'''
特征向量字典,其格式为{field:{特征:编号}}
:param df:
:return: {field:{特征:编号}}
'''
feature_dict={}
total_feature=0
df.drop('rate',axis=1,inplace=True)
for col in df.columns:
if col in num_col:
feature_dict[col]=total_feature
total_feature += 1
else:
unique_feature = df[col].unique()
feature_dict[col]=dict(zip(unique_feature,range(total_feature,total_feature+len(unique_feature))))
total_feature += len(unique_feature)
return feature_dict,total_feature
def get_data(df,feature_dict):
'''
:param df:
:return:
'''
y = df[['rate']].values
dd = df.drop('rate',axis=1)
df_index = dd.copy()
df_value = dd.copy()
for col in df_index.columns:
if col in num_col:
df_index[col] = feature_dict[col]
else:
df_index[col] = df_index[col].map(feature_dict[col])
df_value[col] = 1.0
xi=df_index.values.tolist()
xv=df_value.values.tolist()
return xi,xv,y
df = pd.read_csv('D:/huashuData/用户特征/dianbo_user_3.csv', converters={'user_id': str, 'program_id': str})
df_train, df_test = train_test_split(df, test_size=0.2, stratify=df['user_id'], random_state=10)
num_col = ['count']
label_col = ['rate']
dict,feature_size = get_feature_dict(df,num_col)
x_train_index,x_train_value,y_train = get_data(df_train,dict)
x_test_index, x_test_value, y_test = get_data(df_train, dict)
# print(y_train)
embedding_size = 8
lr = 0.02
l2_w = 0.01
l2_v = 0.01
epoch = 20
m, n = np.array(x_train_index).shape
print(m, n)
xidx = tf.placeholder(tf.int32, [None, None], name='feat_index')
xval = tf.placeholder(tf.float32, [None, None], name='feat_value')
y = tf.placeholder(tf.float32, [None, 1], name='label')
'''初始化参数'''
w_0 = tf.Variable(tf.zeros([1]))
w = tf.Variable(tf.random_normal([feature_size, 1], mean=0, stddev=0.01))
v = tf.Variable(tf.random_normal([feature_size, embedding_size], mean=0, stddev=0.01))
'''embedding'''
embedding_first = tf.nn.embedding_lookup(w, xidx)
embedding = tf.nn.embedding_lookup(v, xidx) # N n embedding_size
value = tf.reshape(xval, [-1, n, 1])
embedding_value = tf.multiply(embedding, value) # N n embedding_size
'''前向传播'''
# ---------first order---------
first_order = tf.reduce_sum(tf.multiply(embedding_first, value), axis=1)
liner = tf.add(w_0,first_order) # None*1
# ---------second order---------
mul_square = tf.square(tf.reduce_sum(embedding_value, 1))# None * 8
squqre_mul = tf.reduce_sum(tf.square(embedding_value), 1) # None * 8
second_order = 0.5 * tf.reduce_sum(tf.subtract(mul_square, squqre_mul), 1,keepdims=True) # None * 1
# ---------FM Model的预测值---------
fm_model = tf.add(liner, second_order) # None * 1
'''损失函数'''
loss = tf.reduce_mean(tf.square(fm_model - y))
# l2_norm = tf.reduce_sum(l2_w * tf.square(w) + l2_v * tf.square(v))
# losses = tf.add(loss, l2_norm)
'''随机梯度下降'''
train_op = tf.train.GradientDescentOptimizer(lr).minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for step in range(epoch):
tmp_loss, _ = sess.run([loss, train_op], feed_dict={xidx: x_train_index, xval: x_train_value, y: y_train})
print("epoch:%d tmp_loss:%f" %(step,tmp_loss))
完整代码详见:https://github.com/garfieldsun/recsys/tree/master/FM
3、参考文献
FM模型原理
FM模型numpy实现