vivado HLS硬件化指令(三)HLS增大运算吞吐量的硬件优化
背景:为了更少的时延,我们需要增大吞吐量和流率,因此需要用到下面的优化指令。
目的:熟悉UG902文档中HLS关于增大吞吐量和流率的优化指令。
目录
1. Task Pipeline
1.1 Rewinding pipelined loops
1.2 Flushing Pipeline
1.3 Automatic loop pipeline
2 Partition Array to improve pipelining
3.dependencies
3.1 去除false dependencies来改善loop pipeline
4. loop unrolling
1. Task Pipeline
Pipeline的意思是一个操作并不需要完成所有的步骤,而下一个操作就会开始。可以用于函数和循环。
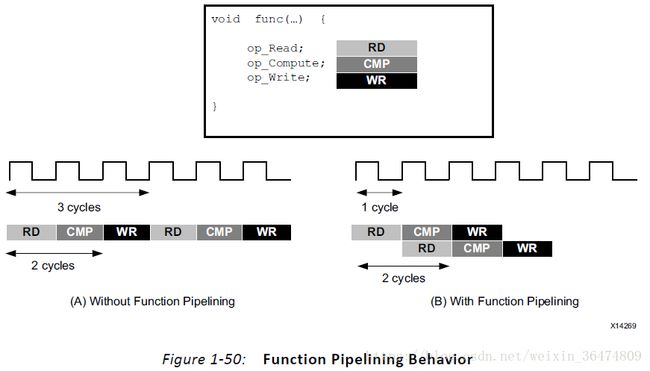
如果没有pipeline优化指令,则函数每3个时钟周期读取一个数,每2个时钟周期输出一个数。函数的Initiation Interval(II)为3,latency为2。加了pipeline之后,II=1

运用循环流水线,可以将一个8时钟周期的循环(II=3)改为4时钟周期。
PIPELINE指令的II(Initiation interval)默认值为1,II可以被确认。Pipeline指令下面的层级的会被UNROLL,所有的子函数需要被单独的PIPELINE。
函数PIPELINE与循环PIPELINE的区别,如下图:
- 函数中,PIPELINE会永久运行不结束。
- 循环中,PIPELINE指令会一直执行知道所有的循环结束。

1.1 Rewinding pipelined loops
Loops which are the top-level loop in a function or are used in a region where the DATAFLOW optimization is used can be made to continuously execute using the PIPELINE directive with the rewind option.即DATAFLOW指令需要使用PIPELINE的rewind选项。

1.2 Flushing Pipeline
Pipeline会持续的执行,只要有数据输入到pipeline之中。如果没有数据可以被获取,则pipeline会中止。如果没有数据可以读入,则pipeline会中止,像下面那样,有数据读入时,pipeline会继续开始。

1.3 Automatic loop pipeline
Solution——Solution settings——general——add——config_compile
可以设置iteration limit,在limit之下的就自动被pipeline
2 Partition Array to improve pipelining

这种报错就是不能满足II=1,因为内存port数量的限制。数组通常被存在BRAM上,BRAM最大的端口数量为2,因此限制了读和写的吞吐量。为了改善带宽,我们可以将数组实现为更小的数组,这样就能有效的增加port的数量。
数组运用ARRAY_PARTITION指令分开,HLS会提供三个类型的partation指令:
- Block:整体的分
- cyclic:交叉的分
- complete:数组分为单独的元素进行操作
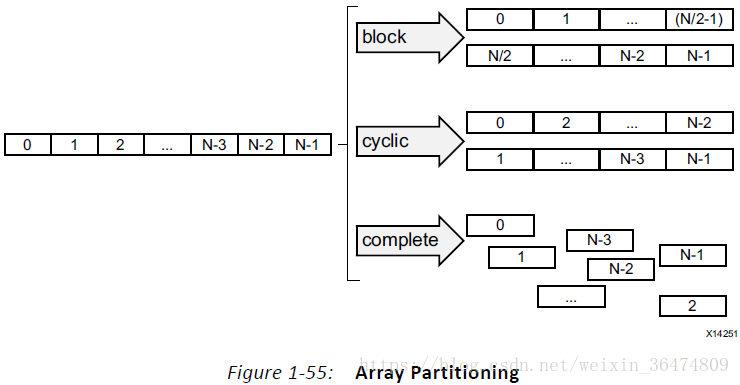
对于block指令和cyclic指令来说,factor指令用于将数组分成不同的小数组的数量的个数。例如,上面的就是factor为2,如果不能整除。最后一个数组就有更少的元素。
当分开多元数组的时候,dimension选项用于具体化数组分成的维度。


3.dependencies
HLS会基于c代码创建一个硬件的datapath。如果没有pipeline指令,则执行的时候是一个序列,因此没有dependecies。当读和写操作在前一个读和写操作之后被执行,则认为是具有dependencies。
- read-after-write,RAW是true denpendency。例如:t=a*b;c=t+1
- write-after-read,WAR是anti-dependency,当一个指令在前一个指令运行之前不能更新一个寄存器或者memory。例如,b=t+a;t=3;
- write-after-write,WAW当不用按照确定的顺序进行写操作时。t=a+b;c=t+1;t=1;
- read-after-read,RAR为no-dependency
例如,生成一个pipeline时,
int top(int a, int b) {
int t,c;
I1: t = a * b;
I2: c = t + 1;
return c;
}I2语句用到了I1语句的t,硬件上,乘法操作需要3个时钟周期。I2会被delay这么久。如果进行pipeline,则实验依然会是3因,但是II变味了1,因为这是一个严格的前馈的datapath。
int top(int a) {
int r=1,rnext,m,i,out;
static int mem[256];
L1: for(i=0;i<=254;i++) {
#pragma HLS PIPELINE II=1
I1: m = r * a , mem[i+1]=m; // line 7
I2: rnext = mem[i], r = rnext; // line 8
}
return r;
}当作用的是数组不是变量时,memory dependencies就会发生。sheduling上面的L1就会产生下面这些警告信息:
WARNING: [SCHED 204-68] Unable to enforce a carried dependency constraint (II = 1,
distance = 1)
between 'store' operation (top.cpp:7) of variable 'm', top.cpp:7 on array 'mem' and
'load' operation ('rnext', top.cpp:8) on array 'mem'.
INFO: [SCHED 204-61] Pipelining result: Target II: 1, Final II: 2, Depth: 3.如果写一个参数,读取另一个,就不会出现这样的问题。
// Iteration for i=0
I1: m = r * a , mem[1]=m; // line 7
I2: rnext = mem[0], r = rnext; // line 8
// Iteration for i=1
I1: m = r * a , mem[2]=m; // line 7
I2: rnext = mem[1], r = rnext; // line 8
// Iteration for i=2
I1: m = r * a , mem[3]=m; // line 7
I2: rnext = mem[2], r = rnext; // line 8
3.1 去除false dependencies来改善loop pipeline
如果loop之间有dependencies,则pipeline就不能进行。
void foo(int rows, int cols, ...)
for (row = 0; row < rows + 1; row++) {
for (col = 0; col < cols + 1; col++) {
#pragma HLS PIPELINE II=1
if (col < cols) {
buff_A[2][col] = buff_A[1][col]; // read from buff_A[1][col]
buff_A[1][col] = buff_A[0][col]; // write to buff_A[1][col]
buff_B[1][col] = buff_B[0][col];
temp = buff_A[0][col];
}
}
}这个例子中,HLS并不知道cols的值,并且保守的假定buff_A[1][col]与buff_A[1][col]之间是具有dependence的。

如果cols=0,则下一个循环迭代就会很快开始,从buff_A[0][cols]的读与写不能同时发生。cols会一直是0,但HLS不能假设数据之间的独立性。所以可以用DEPENDENCE指令来让HLS知道数据之间的关联性。在这里,假设数据之间,在loop iteration之间,没有dependence,
void foo(int rows, int cols, ...)
for (row = 0; row < rows + 1; row++) {
for (col = 0; col < cols + 1; col++) {
#pragma HLS PIPELINE II=1
#pragma AP dependence variable=buff_A inter false
#pragma AP dependence variable=buff_B inter false
if (col < cols) {
buff_A[2][col] = buff_A[1][col]; // read from buff_A[1][col]
buff_A[1][col] = buff_A[0][col]; // write to buff_A[1][col]
buff_B[1][col] = buff_B[0][col];
temp = buff_A[0][col];
}
}
}- Inter:(迭代间相关)指定dependency是存在于同一个循环的不同的迭代之中
如果进行这个指令指明false,则HLS会将循环进行并行化处理。
- Intra:(迭代内相关)指定dependence是在一个循环迭代之中。例如一个数组会在iteration的开始和结束被access
当intradependencies被指明为false时,HLS就会将loop中间的operation进行自由的移动。
大多数情况下,data dependencies是一个困难的问题,往往需要更改源码。
4. loop unrolling
默认模式下,HLS会将loop进行rolled,所以loop会被当作单个的entity。loop中所有的操作都被运用相同的硬件资源迭代实现。
运用UNROLL指令,可以将for循环进行展开。

- Rolled loop:每个迭代需要单独的时钟周期。一共四个时钟周期,只需要一个乘法器和单端口的BRAM
- Partially unrolled loop:loop被factor为2的展开。需要两个乘法器和双端口的RAM,实现需要两个时钟周周期就能结束。一半的II和一半的latency。
- Unrolled loop:完全unrolled,需要4个乘法器。更重要的是,需要4次读和写,但是BRAM最多两个端口,因此需要将数组进行partation。
// Array Order : 0 1 2 3 4 5 6 7 8 9 10 etc. 16 etc...
// Sample Order: A0 B0 C0 D0 E0 F0 G0 H0 A1 B1 C2 etc. A2 etc...
// Output Order: A0 B0 C0 D0 E0 F0 G0 H0 A0+A1 B0+B1 C0+C2 etc. A0+A1+A2 etc...
#define CHANNELS 8
#define SAMPLES 400
#define N CHANNELS * SAMPLES
void foo (dout_t d_o[N], din_t d_i[N]) {
int i, rem;
// Store accumulated data
static dacc_t acc[CHANNELS];
// Accumulate each channel
For_Loop: for (i=0;i这个例子中,数据被存储在interleave的channel中,一共8通道。如果loop被pipeline为II=1,则每个通道每隔8时钟周期被读和写一次。
Partially unroll这个loop,factor设为8就能让每个通道并行的处理程序。(输入和输出的数组需要也被分为cyclic,这样可以在每个时钟周期之中被多接入)。如果循环被运用pipelined指令加上rewind选项优化,则design就能持续的对8个通道进行并行处理。
void foo (dout_t d_o[N], din_t d_i[N]) {
#pragma HLS ARRAY_PARTITION variable=d_i cyclic factor=8 dim=1 partition
#pragma HLS ARRAY_PARTITION variable=d_o cyclic factor=8 dim=1 partition
int i, rem;
// Store accumulated data
static dacc_t acc[CHANNELS];
// Accumulate each channel
For_Loop: for (i=0;i未完