cs224笔记: Lecture 4 Backpropagation and Computation Graph
Backpropagation and Computation Graph
1. Derivative w.r.t. a weight matrix
还是之前的那个例子,应用chain rule求解梯度,前向计算式子如下:
s = u T h h = f ( z ) z = W x + b s=\mathbf{u}^T\mathbf{h}\\ \mathbf{h}=f(\mathbf{z})\\ \mathbf{z}=\mathbf{W}\mathbf{x}+\mathbf{b} s=uThh=f(z)z=Wx+b
其中 W \mathbf{W} W是 n × m n \times m n×m, s s s是一个标量。
∂ s ∂ W = ∂ s ∂ h ∂ h ∂ z ∂ z ∂ W \frac{\partial s}{\partial \mathbf{W}}= \frac{\partial s}{\partial \mathbf{h}}\frac{\partial \mathbf{h}}{\partial \mathbf{z}}\frac{\partial \mathbf{z}}{\partial \mathbf{W}} ∂W∂s=∂h∂s∂z∂h∂W∂z
反向传播,用到之前求过的导数,令 δ = ∂ s ∂ z = ∂ s ∂ h ∂ h ∂ z \delta=\frac{\partial s}{\partial \mathbf{z}}=\frac{\partial s}{\partial \mathbf{h}}\frac{\partial \mathbf{h}}{\partial \mathbf{z}} δ=∂z∂s=∂h∂s∂z∂h, δ ( n , 1 ) \delta(n, 1) δ(n,1)展开如下:
δ = [ ∂ s ∂ z 1 , . . . , ∂ s ∂ z n ] \delta=[\frac{\partial s}{\partial z_1},...,\frac{\partial s}{\partial z_n}] δ=[∂z1∂s,...,∂zn∂s]
则应用chain rule:
∂ s ∂ W = δ ∂ z ∂ W = δ ∂ ∂ W ( W x + b ) \frac{\partial s}{\partial \mathbf{W}}= \delta \frac{\partial \mathbf{z}}{\partial \mathbf{W}} =\delta \frac{\partial }{\partial \mathbf{W}}(\mathbf{W}\mathbf{x}+\mathbf{b}) ∂W∂s=δ∂W∂z=δ∂W∂(Wx+b)
考虑 z \mathbf{z} z对 W \mathbf{W} W的偏导求解:
∂ z i ∂ W i j = ∂ ∂ W i j ( W i x + b i ) = ∂ ∂ W i j ∑ k = 1 d W i k x k = x j \begin{aligned} \frac{\partial z_i}{\partial W_{ij}} &= \frac{\partial }{\partial W_{ij}}(W_ix+b_i)\\ &=\frac{\partial }{\partial W_{ij}}\sum_{k=1}^dW_{ik}x_k\\ &=x_j \end{aligned} ∂Wij∂zi=∂Wij∂(Wix+bi)=∂Wij∂k=1∑dWikxk=xj
代入原式有( δ i \delta_i δi对应 z i z_i zi, z i z_i zi对应 x j x_j xj):
∂ s ∂ W i j = δ i x j \frac{\partial s}{\partial W_{ij}}=\delta_ix_j ∂Wij∂s=δixj
所以总的结果是一个外积(outer product):
∂ s ∂ W = δ T x T ( n , m ) = ( n , 1 ) × ( 1 , m ) \frac{\partial s}{\partial \mathbf{W}}=\delta^T\mathbf{x}^T \\ (n, m)=(n, 1)\times(1, m) ∂W∂s=δTxT(n,m)=(n,1)×(1,m)
Pitfall问题
假设我们使用预训练好的词向量做训练,有三个同义单词:TV,telly,television,但是前两个在训练集中,第三个在测试集中,这样本身预训练好的三个词向量在相近的区间,但是在我们的训练集一顿操作后,前两个词向量位置改变了,变得与第三个远了,这样就给后来的任务带来了麻烦,例如分类任务,同义的三个词有可能会被分成两类。上图:
(训练前,拿到别人训练好的词向量)
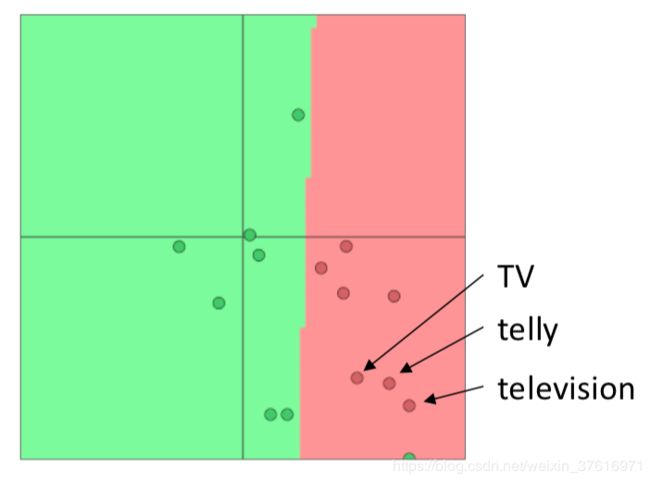
(跑完我们的训练后)

解决方法:
If you only have a small training data set, don’t train the word vectors;
If you have have a large dataset, it probably will work better to “train = update = fine-tune” word vectors to the task;
大意就是如果你的训练集比较小,就直接拿别人训练好的词向量用就完事了,不要再用你的数据集训练了,很容易出现上述的pitfall问题;但是你如果有一个很大的训练集,那可以再对训练后的词向量做fine-tuning,而不太可能出现pitfall的问题
2. Computation Graphs and Backpropagation
引入计算图(Computation Graphs),便于我们对神经网络前向传播后向传播的理解和计算。
还是上个例子:
s = u T h h = f ( z ) z = W x + b x ( i n p u t s ) s=\mathbf{u}^T\mathbf{h}\\ \mathbf{h}=f(\mathbf{z})\\ \mathbf{z}=\mathbf{W}\mathbf{x}+\mathbf{b}\\ \mathbf{x}(inputs) s=uThh=f(z)z=Wx+bx(inputs)
前向传播(forward progagation) 的计算图如下:
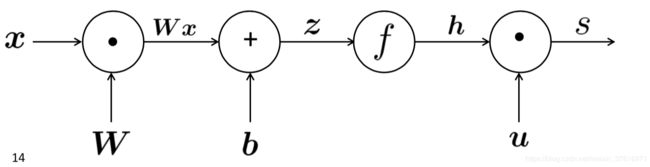
源点为输入,中间结点是操作(operations),边(edges)传递操作的结果。
反向传播(backpropagation) 计算图如下,边(edges)传递梯度:
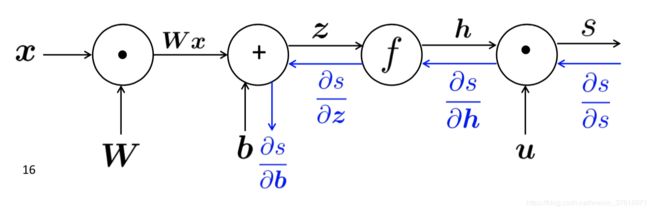
对于每一个结点都会存储一个局部梯度(local gradient),便于反向传播梯度的计算:
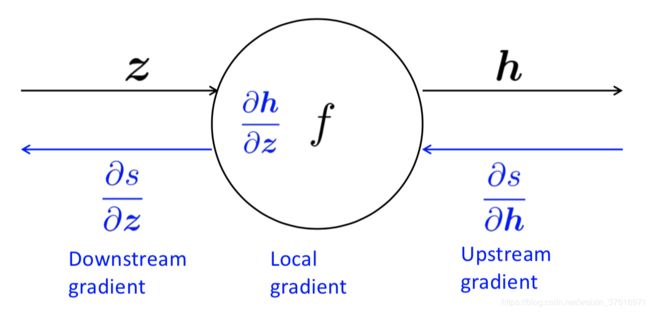
有了local gradient,应用chain rule计算梯度如下:
∂ s ∂ z = ∂ s ∂ h ∂ h ∂ z \frac{\partial s}{\partial \mathbf{z}}= \frac{\partial s}{\partial \mathbf{h}} \frac{\partial \mathbf{h}}{\partial \mathbf{z}} ∂z∂s=∂h∂s∂z∂h
[ D o w n s t r e a m G r a d i e n t ] = [ U p s t r e a m G r a d i e n t ] × [ L o c a l G r a d i e n t ] [DownstreamGradient] = [UpstreamGradient]\times [LocalGradient] [DownstreamGradient]=[UpstreamGradient]×[LocalGradient]
举个例子,函数及输入如下:
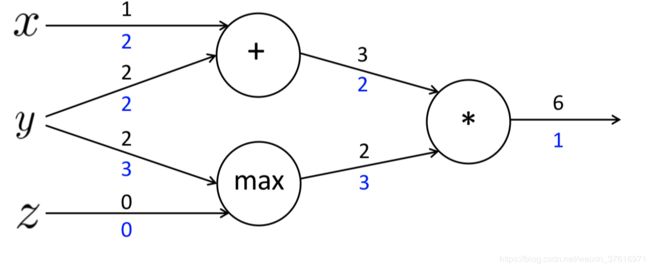
f ( x , y , z ) = ( x + y ) m a x ( y , z ) x = 1 , y = 2 , z = 0 f(x, y, z) = (x+y)max(y, z)\\ x=1, y=2, z=0 f(x,y,z)=(x+y)max(y,z)x=1,y=2,z=0
前向传播步骤如下:
a = x + y b = m a x ( y , z ) f = a b a = x+y\\ b=max(y, z)\\ f = ab a=x+yb=max(y,z)f=ab

计算local gradients并存储在各结点:
∂ a ∂ x = 1 ∂ a ∂ y = 1 ∂ b ∂ y = 1 ∂ b ∂ z = 0 ∂ y ∂ a = b = 2 ∂ y ∂ b = a = 3 \frac{\partial a}{\partial x}=1\\ \frac{\partial a}{\partial y}=1\\ \frac{\partial b}{\partial y}=1\\ \frac{\partial b}{\partial z}=0\\ \frac{\partial y}{\partial a}=b=2\\ \frac{\partial y}{\partial b}=a=3\\ ∂x∂a=1∂y∂a=1∂y∂b=1∂z∂b=0∂a∂y=b=2∂b∂y=a=3
反向传播计算梯度,downstream=upstream*local:
∂ f ∂ f = 1 ∂ f ∂ a = ∂ f ∂ f ∂ f ∂ a = 1 ∗ 2 = 2 ∂ f ∂ b = ∂ f ∂ f ∂ f ∂ b = 1 ∗ 3 = 2 ∂ f ∂ x = ∂ f ∂ a ∂ a ∂ x = 2 ∗ 1 = 2 ∂ f ∂ y = ∂ f ∂ a ∂ a ∂ y + ∂ f ∂ b ∂ b ∂ y = 2 ∗ 1 + 3 ∗ 1 = 5 ∂ f ∂ z = ∂ f ∂ b ∂ b ∂ z = 2 ∗ 0 = 0 \frac{\partial f}{\partial f}=1\\ \frac{\partial f}{\partial a}=\frac{\partial f}{\partial f}\frac{\partial f}{\partial a}=1*2=2\\ \frac{\partial f}{\partial b}=\frac{\partial f}{\partial f}\frac{\partial f}{\partial b}=1*3=2\\ \frac{\partial f}{\partial x}=\frac{\partial f}{\partial a}\frac{\partial a}{\partial x}=2*1=2\\ \frac{\partial f}{\partial y}=\frac{\partial f}{\partial a}\frac{\partial a}{\partial y}+\frac{\partial f}{\partial b}\frac{\partial b}{\partial y}=2*1+3*1=5\\ \frac{\partial f}{\partial z}=\frac{\partial f}{\partial b}\frac{\partial b}{\partial z}=2*0=0\\ ∂f∂f=1∂a∂f=∂f∂f∂a∂f=1∗2=2∂b∂f=∂f∂f∂b∂f=1∗3=2∂x∂f=∂a∂f∂x∂a=2∗1=2∂y∂f=∂a∂f∂y∂a+∂b∂f∂y∂b=2∗1+3∗1=5∂z∂f=∂b∂f∂z∂b=2∗0=0
这里注意 y y y的upstream来自两部分 a a a和 b b b,在计算 y y y的梯度时需要将它们加起来。计算图如下,蓝色数字字代表反向传播的梯度
In General
1 前向传播:
-按照拓扑结构的顺序(topological sort order)访问结点
-在给定前驱结点值的基础上计算结点的值
2 反向传播
-初始化输出的梯度为1
-以拓扑逆序访问每个结点,使用后继结点的梯度应用chain rule计算当前结点的梯度
(这里计算图肯定是无环图(acyclic graph),所以拓扑顺序很好确定)
通过数值计算梯度可以用于检验梯度
例如定义一个较小的 h = 1 e − 4 h=1e-4 h=1e−4,导数可以通过 f ′ ( x ) = f ( x + h ) − f ( x − h ) 2 h f'(x)=\frac{f(x+h)-f(x-h)}{2h} f′(x)=2hf(x+h)−f(x−h)得到一个近似值
这个方法易于实现,但是计算比较耗时。
3. Regularizations/Vectorization/Non-linearities/Parameters Initialization/Optimizers/Learning Rate
Regularization(正则化)
奥卡姆剃刀原则,我们希望训练出的模型越简单越好,所以在损失函数里对参数增加了一个惩罚项,可以解决过拟合(overfitting)问题
例如对所有参数增加一个L2 Regularization:
J ( θ ) = 1 N − log ( e x p ( f y i ) ∑ c = 1 C e x p ( f y c ) ) + λ ∑ k θ k 2 J(\theta)=\frac{1}{N}-\log(\frac{exp(f_{y_i})}{\sum_{c=1}^Cexp(f_{y_c})})+\lambda\sum_k\theta_k^2 J(θ)=N1−log(∑c=1Cexp(fyc)exp(fyi))+λk∑θk2
Vectorization
使用向量(矩阵)表示数据,进行计算可以大大加快算法的速度。
Non-linearities
logistic(“sigmoid”)
f ( z ) = 1 1 + e x p ( − z ) f(z)=\frac{1}{1+exp(-z)} f(z)=1+exp(−z)1
tanh,其实可以由logistic转换得到, t a n h ( z ) = 2 l o g i s t i c ( 2 z ) − 1 tanh(z)=2logistic(2z)-1 tanh(z)=2logistic(2z)−1
f ( z ) = e x p ( z ) − e x p ( − z ) e x p ( z ) + e x p ( − z ) f(z) = \frac{exp(z)-exp(-z)}{exp(z)+exp(-z)} f(z)=exp(z)+exp(−z)exp(z)−exp(−z)
hard tanh:
H a r d T a n h ( z ) = { − 1 if x<-1 x if -1<=x<=1 1 if x>1 HardTanh(z) = \begin{cases}-1&\text{if x<-1}\\ x&\text{if -1<=x<=1}\\ 1&\text{if x>1} \end{cases} HardTanh(z)=⎩⎪⎨⎪⎧−1x1if x<-1if -1<=x<=1if x>1
上述的logistic和tanh如今只有一些特殊的情况下使用,深度网络不在用到它们。
ReLU(rectified linear unit)
r e c t ( z ) = m a x ( z , 0 ) rect(z)=max(z, 0) rect(z)=max(z,0)
Leaky ReLU
l e a k y R e L U ( z ) = { 0.01 x if x<0 x if x>=0 leakyReLU(z) = \begin{cases}0.01x&\text{if x<0}\\ x&\text{if x>=0} \end{cases} leakyReLU(z)={0.01xxif x<0if x>=0
ReLU会经常用于构造feed-forward深度网络,训练快性能好。
Parameters Initialization
参数通常是用一个随机的小的数字初始化,为了避免相同防止其阻碍训练(To avoid symmetries that prevent learning/specialization)
Optimizers
通常SGD就可以,其他的如: Adagrad, RMSprop, Adam, SparseAdam
Learning Rates
可以使用一个常量作为学习率,但是它的大小必须小心定义,过大会导致模型不能收敛,过小会导致模型收敛时间过长。
也可以通过学习时间到增长不断得减少学习率,可以手动的凭经验去调整,也可以通过一些公式自动调整,例如
l r = l r 0 e − k t , for epoch t lr=lr_0e^{-kt},\text{for epoch t} lr=lr0e−kt,for epoch t