R for Data Science总结之——Tidy Data
R for Data Science总结之——Tidy Data
在R中进行数据挖掘要求数据集具有tidy data的特征,这有点类似数据库中的范式结构:
- 每一个变量都有自己独立的一列
- 每一个观测值都有自己独立的一行
- 每一个数据都是独立的单元格

这里我们会用到tidyr包来处理每一个数据集使其拥有tidy data的特征,其包含在tidyverse框架中:
library(tidyverse)
table1
#> # A tibble: 6 x 4
#> country year cases population
#>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583
table2
#> # A tibble: 12 x 4
#> country year type count
#>
#> 1 Afghanistan 1999 cases 745
#> 2 Afghanistan 1999 population 19987071
#> 3 Afghanistan 2000 cases 2666
#> 4 Afghanistan 2000 population 20595360
#> 5 Brazil 1999 cases 37737
#> 6 Brazil 1999 population 172006362
#> # ... with 6 more rows
table3
#> # A tibble: 6 x 3
#> country year rate
#> *
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583
# Spread across two tibbles
table4a # cases
#> # A tibble: 3 x 3
#> country `1999` `2000`
#> *
#> 1 Afghanistan 745 2666
#> 2 Brazil 37737 80488
#> 3 China 212258 213766
table4b # population
#> # A tibble: 3 x 3
#> country `1999` `2000`
#> *
#> 1 Afghanistan 19987071 20595360
#> 2 Brazil 172006362 174504898
#> 3 China 1272915272 1280428583
这之中只有table1符合tidy data的要求,而拥有tidy的特征是使用dplyr中mutate, summary等函数的基础:
# Compute rate per 10,000
table1 %>%
mutate(rate = cases / population * 10000)
#> # A tibble: 6 x 5
#> country year cases population rate
#>
#> 1 Afghanistan 1999 745 19987071 0.373
#> 2 Afghanistan 2000 2666 20595360 1.29
#> 3 Brazil 1999 37737 172006362 2.19
#> 4 Brazil 2000 80488 174504898 4.61
#> 5 China 1999 212258 1272915272 1.67
#> 6 China 2000 213766 1280428583 1.67
# Compute cases per year
table1 %>%
count(year, wt = cases)
#> # A tibble: 2 x 2
#> year n
#>
#> 1 1999 250740
#> 2 2000 296920
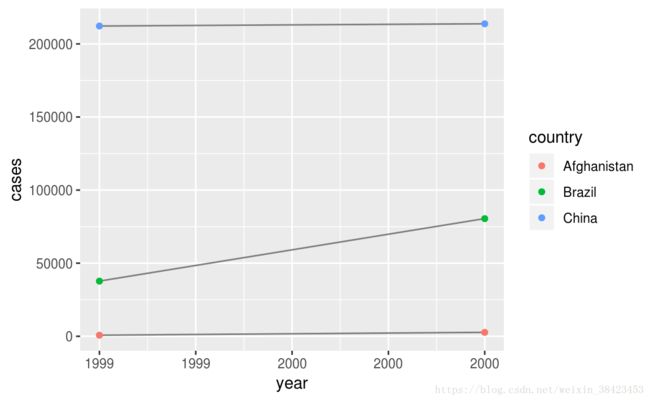
# Visualise changes over time
library(ggplot2)
ggplot(table1, aes(year, cases)) +
geom_line(aes(group = country), colour = "grey50") +
geom_point(aes(colour = country))
Gathering
table4a
#> # A tibble: 3 x 3
#> country `1999` `2000`
#> *
#> 1 Afghanistan 745 2666
#> 2 Brazil 37737 80488
#> 3 China 212258 213766
这个数据集中两列1999和2000是数值而不是变量,列名应放在变量year和cases中:
table4a %>%
gather(`1999`, `2000`, key = "year", value = "cases")
#> # A tibble: 6 x 3
#> country year cases
#>
#> 1 Afghanistan 1999 745
#> 2 Brazil 1999 37737
#> 3 China 1999 212258
#> 4 Afghanistan 2000 2666
#> 5 Brazil 2000 80488
#> 6 China 2000 213766
对于table4b同理:
table4b %>%
gather(`1999`, `2000`, key = "year", value = "population")
#> # A tibble: 6 x 3
#> country year population
#>
#> 1 Afghanistan 1999 19987071
#> 2 Brazil 1999 172006362
#> 3 China 1999 1272915272
#> 4 Afghanistan 2000 20595360
#> 5 Brazil 2000 174504898
#> 6 China 2000 1280428583
将table4a和table4b合并成一个数据集可用join函数:
tidy4a <- table4a %>%
gather(`1999`, `2000`, key = "year", value = "cases")
tidy4b <- table4b %>%
gather(`1999`, `2000`, key = "year", value = "population")
left_join(tidy4a, tidy4b)
#> Joining, by = c("country", "year")
#> # A tibble: 6 x 4
#> country year cases population
#>
#> 1 Afghanistan 1999 745 19987071
#> 2 Brazil 1999 37737 172006362
#> 3 China 1999 212258 1272915272
#> 4 Afghanistan 2000 2666 20595360
#> 5 Brazil 2000 80488 174504898
#> 6 China 2000 213766 1280428583
Spreading
spread与gather恰恰相反是将列中的值变为列名:
table2
#> # A tibble: 12 x 4
#> country year type count
#>
#> 1 Afghanistan 1999 cases 745
#> 2 Afghanistan 1999 population 19987071
#> 3 Afghanistan 2000 cases 2666
#> 4 Afghanistan 2000 population 20595360
#> 5 Brazil 1999 cases 37737
#> 6 Brazil 1999 population 172006362
#> # ... with 6 more rows
table2 %>%
spread(key = type, value = count)
#> # A tibble: 6 x 4
#> country year cases population
#>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583
Separating
对于一些数据集,某一列可以分解成两列或者某两列需要整合成一列:
table3
#> # A tibble: 6 x 3
#> country year rate
#> *
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583
table3 %>%
separate(rate, into = c("cases", "population"))
#> # A tibble: 6 x 4
#> country year cases population
#> *
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583
默认分离标识符为/也可以在sep参数中进行修改:
table3 %>%
separate(rate, into = c("cases", "population"), sep = "/")
为了将生成的列赋予更好的类型,可以修改convert参数:
table3 %>%
separate(rate, into = c("cases", "population"), convert = TRUE)
#> # A tibble: 6 x 4
#> country year cases population
#> *
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583
也可以修改sep参数从第几个数值开始分割:
table3 %>%
separate(year, into = c("century", "year"), sep = 2)
#> # A tibble: 6 x 4
#> country century year rate
#> *
#> 1 Afghanistan 19 99 745/19987071
#> 2 Afghanistan 20 00 2666/20595360
#> 3 Brazil 19 99 37737/172006362
#> 4 Brazil 20 00 80488/174504898
#> 5 China 19 99 212258/1272915272
#> 6 China 20 00 213766/1280428583
Uniting
unite与separate恰好相反
table5 %>%
unite(new, century, year)
#> # A tibble: 6 x 3
#> country new rate
#>
#> 1 Afghanistan 19_99 745/19987071
#> 2 Afghanistan 20_00 2666/20595360
#> 3 Brazil 19_99 37737/172006362
#> 4 Brazil 20_00 80488/174504898
#> 5 China 19_99 212258/1272915272
#> 6 China 20_00 213766/1280428583
table5 %>%
unite(new, century, year)
#> # A tibble: 6 x 3
#> country new rate
#>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583
table5 %>%
unite(new, century, year, sep = "")
#> # A tibble: 6 x 3
#> country new rate
#>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583
缺省值
缺省值分为明确标识为NA与隐式缺省两种:
stocks <- tibble(
year = c(2015, 2015, 2015, 2015, 2016, 2016, 2016),
qtr = c( 1, 2, 3, 4, 2, 3, 4),
return = c(1.88, 0.59, 0.35, NA, 0.92, 0.17, 2.66)
)
其中2015年第四季度数据显式缺省,2016年第一季度数据隐式缺省。
stocks %>%
spread(year, return)
#> # A tibble: 4 x 3
#> qtr `2015` `2016`
#>
#> 1 1 1.88 NA
#> 2 2 0.59 0.92
#> 3 3 0.35 0.17
#> 4 4 NA 2.66
去除这些数据可设置na.rm = TRUE:
stocks %>%
spread(year, return) %>%
gather(year, return, `2015`:`2016`, na.rm = TRUE)
#> # A tibble: 6 x 3
#> qtr year return
#> *
#> 1 1 2015 1.88
#> 2 2 2015 0.59
#> 3 3 2015 0.35
#> 4 2 2016 0.92
#> 5 3 2016 0.17
#> 6 4 2016 2.66
另外也可使用complete()函数让这些数据显式呈现:
stocks %>%
complete(year, qtr)
#> # A tibble: 8 x 3
#> year qtr return
#>
#> 1 2015 1 1.88
#> 2 2015 2 0.59
#> 3 2015 3 0.35
#> 4 2015 4 NA
#> 5 2016 1 NA
#> 6 2016 2 0.92
#> # ... with 2 more rows
有的时候一些数据集省略一些值是因为其和上值相同,这时可用fill()函数:
treatment <- tribble(
~ person, ~ treatment, ~response,
"Derrick Whitmore", 1, 7,
NA, 2, 10,
NA, 3, 9,
"Katherine Burke", 1, 4
)
treatment %>%
fill(person)
#> # A tibble: 4 x 3
#> person treatment response
#>
#> 1 Derrick Whitmore 1 7
#> 2 Derrick Whitmore 2 10
#> 3 Derrick Whitmore 3 9
#> 4 Katherine Burke 1 4
实例研究
下面通过一个实例研究一个普通数据集整理成tidy data的过程:
who
#> # A tibble: 7,240 x 60
#> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534
#>
#> 1 Afghan… AF AFG 1980 NA NA NA
#> 2 Afghan… AF AFG 1981 NA NA NA
#> 3 Afghan… AF AFG 1982 NA NA NA
#> 4 Afghan… AF AFG 1983 NA NA NA
#> 5 Afghan… AF AFG 1984 NA NA NA
#> 6 Afghan… AF AFG 1985 NA NA NA
#> # ... with 7,234 more rows, and 53 more variables: new_sp_m3544 ,
#> # new_sp_m4554 , new_sp_m5564 , new_sp_m65 ,
#> # new_sp_f014 , new_sp_f1524 , new_sp_f2534 ,
#> # new_sp_f3544 , new_sp_f4554 , new_sp_f5564 ,
#> # new_sp_f65 , new_sn_m014 , new_sn_m1524 ,
#> # new_sn_m2534 , new_sn_m3544 , new_sn_m4554 ,
#> # new_sn_m5564 , new_sn_m65 , new_sn_f014 ,
#> # new_sn_f1524 , new_sn_f2534 , new_sn_f3544 ,
#> # new_sn_f4554 , new_sn_f5564 , new_sn_f65 ,
#> # new_ep_m014 , new_ep_m1524 , new_ep_m2534 ,
#> # new_ep_m3544 , new_ep_m4554 , new_ep_m5564 ,
#> # new_ep_m65 , new_ep_f014 , new_ep_f1524 ,
#> # new_ep_f2534 , new_ep_f3544 , new_ep_f4554 ,
#> # new_ep_f5564 , new_ep_f65 , newrel_m014 ,
#> # newrel_m1524 , newrel_m2534 , newrel_m3544 ,
#> # newrel_m4554 , newrel_m5564 , newrel_m65 ,
#> # newrel_f014 , newrel_f1524 , newrel_f2534 ,
#> # newrel_f3544 , newrel_f4554 , newrel_f5564 ,
#> # newrel_f65
首先后面几列看起来像是某一列的数值,使用gather():
who1 <- who %>%
gather(new_sp_m014:newrel_f65, key = "key", value = "cases", na.rm = TRUE)
who1
#> # A tibble: 76,046 x 6
#> country iso2 iso3 year key cases
#> *
#> 1 Afghanistan AF AFG 1997 new_sp_m014 0
#> 2 Afghanistan AF AFG 1998 new_sp_m014 30
#> 3 Afghanistan AF AFG 1999 new_sp_m014 8
#> 4 Afghanistan AF AFG 2000 new_sp_m014 52
#> 5 Afghanistan AF AFG 2001 new_sp_m014 129
#> 6 Afghanistan AF AFG 2002 new_sp_m014 90
#> # ... with 7.604e+04 more rows
我们在看一下key列的分布:
who1 %>%
count(key)
#> # A tibble: 56 x 2
#> key n
#>
#> 1 new_ep_f014 1032
#> 2 new_ep_f1524 1021
#> 3 new_ep_f2534 1021
#> 4 new_ep_f3544 1021
#> 5 new_ep_f4554 1017
#> 6 new_ep_f5564 1017
#> # ... with 50 more rows
为了将key列完全分离,先将其变成规整格式:
who2 <- who1 %>%
mutate(key = stringr::str_replace(key, "newrel", "new_rel"))
who2
#> # A tibble: 76,046 x 6
#> country iso2 iso3 year key cases
#>
#> 1 Afghanistan AF AFG 1997 new_sp_m014 0
#> 2 Afghanistan AF AFG 1998 new_sp_m014 30
#> 3 Afghanistan AF AFG 1999 new_sp_m014 8
#> 4 Afghanistan AF AFG 2000 new_sp_m014 52
#> 5 Afghanistan AF AFG 2001 new_sp_m014 129
#> 6 Afghanistan AF AFG 2002 new_sp_m014 90
#> # ... with 7.604e+04 more rows
所有的格式统一后,再separate():
who3 <- who2 %>%
separate(key, c("new", "type", "sexage"), sep = "_")
who3
#> # A tibble: 76,046 x 8
#> country iso2 iso3 year new type sexage cases
#>
#> 1 Afghanistan AF AFG 1997 new sp m014 0
#> 2 Afghanistan AF AFG 1998 new sp m014 30
#> 3 Afghanistan AF AFG 1999 new sp m014 8
#> 4 Afghanistan AF AFG 2000 new sp m014 52
#> 5 Afghanistan AF AFG 2001 new sp m014 129
#> 6 Afghanistan AF AFG 2002 new sp m014 90
#> # ... with 7.604e+04 more rows
我们再看一下new列,发现其实际为一个常数,则丢弃掉:
who3 %>%
count(new)
#> # A tibble: 1 x 2
#> new n
#>
#> 1 new 76046
who4 <- who3 %>%
select(-new, -iso2, -iso3)
我们再将sex和age进行分离:
who5 <- who4 %>%
separate(sexage, c("sex", "age"), sep = 1)
who5
#> # A tibble: 76,046 x 6
#> country year type sex age cases
#>
#> 1 Afghanistan 1997 sp m 014 0
#> 2 Afghanistan 1998 sp m 014 30
#> 3 Afghanistan 1999 sp m 014 8
#> 4 Afghanistan 2000 sp m 014 52
#> 5 Afghanistan 2001 sp m 014 129
#> 6 Afghanistan 2002 sp m 014 90
#> # ... with 7.604e+04 more rows
这就完成了一个数据集的tidy过程,将整个流程综合成一个管道为:
who %>%
gather(key, value, new_sp_m014:newrel_f65, na.rm = TRUE) %>%
mutate(key = stringr::str_replace(key, "newrel", "new_rel")) %>%
separate(key, c("new", "var", "sexage")) %>%
select(-new, -iso2, -iso3) %>%
separate(sexage, c("sex", "age"), sep = 1)
全文代码已上传GITHUB点此进入